

Published: Sep 19, 2024 by Isaac Johnson
Today we will look at finding and fixing some cost spikes. These actually came about because… well, I’ll just let you tag along to see. The goal here is to start with a Cost alert and figure out where the spend is happening and how we can remediate it.
Let’s start with the Alert
The Alert
It started with some spikes and messages to Pagerduty about Costs hitting my 50% threshold
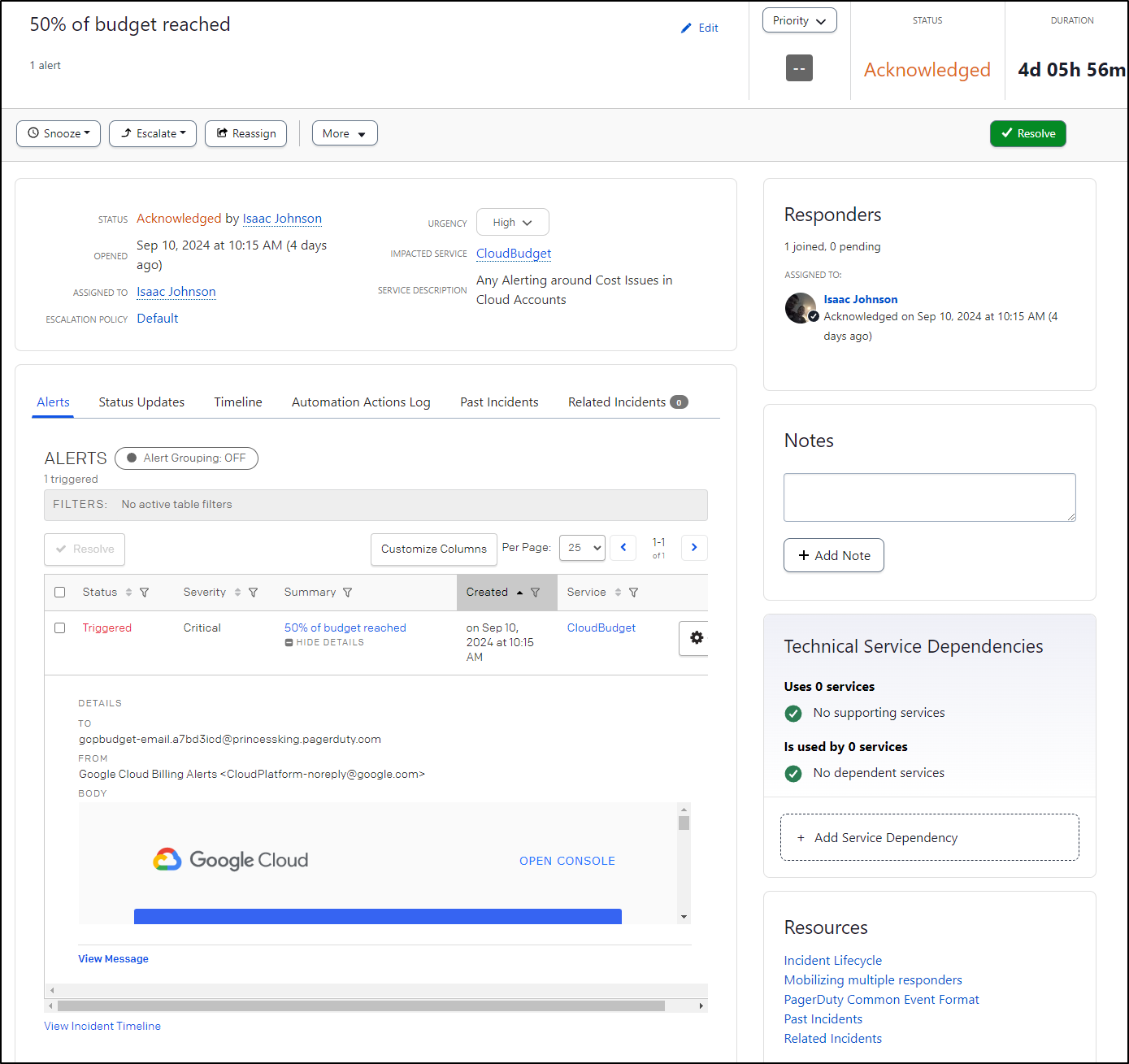
I acknowledged and made it point to come back and check. Within two days I saw it jump to 90% which isn’t good (and today 100%)
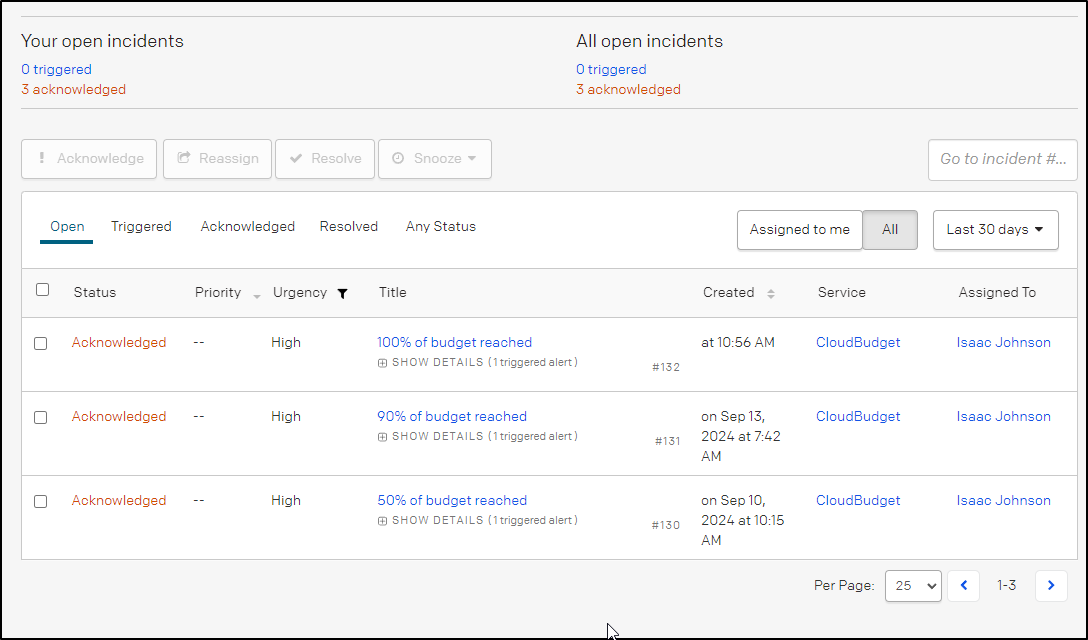
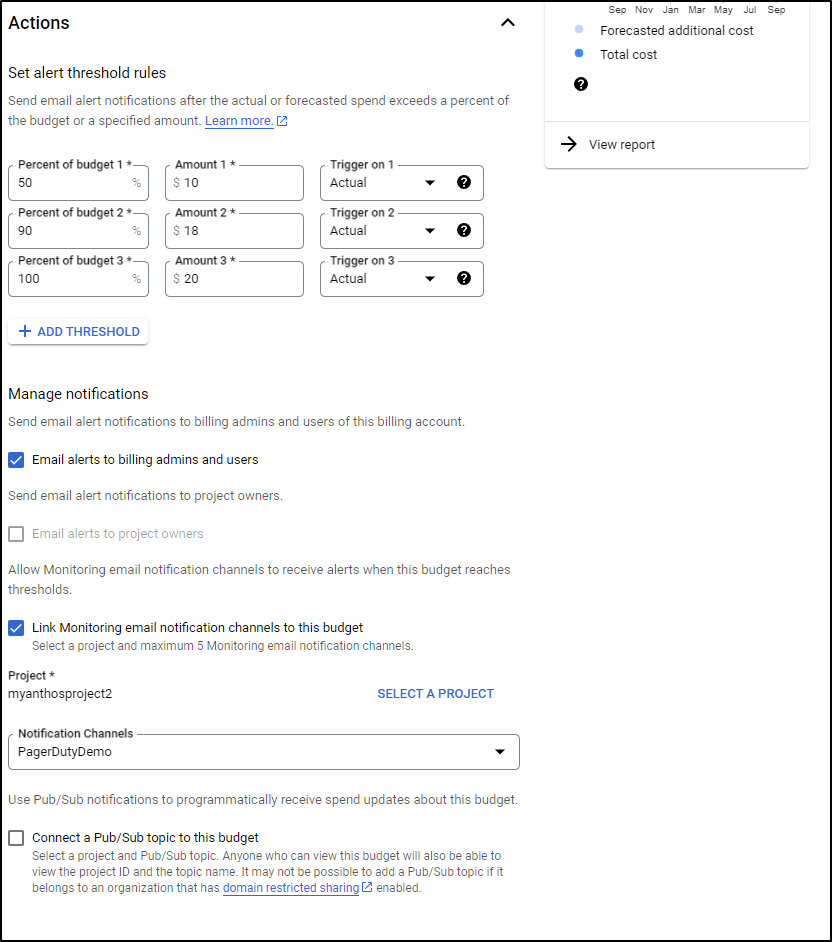
The budgets are set to $20 which is a safe amount to spend on blogging in a month
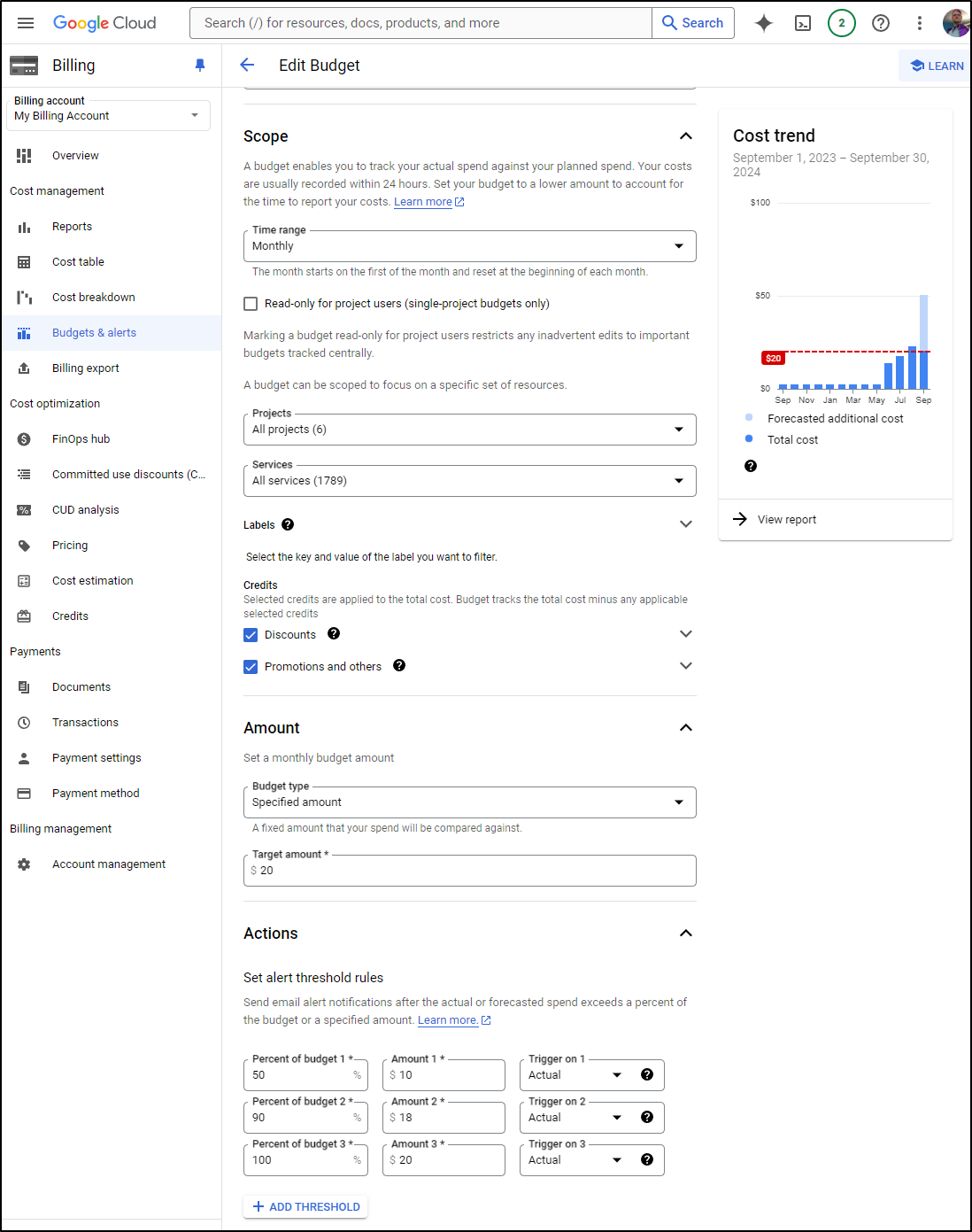
The alerts all go through PagerDuty to reach me directly
From budgets, we can go to Reports where I can see the breakdown
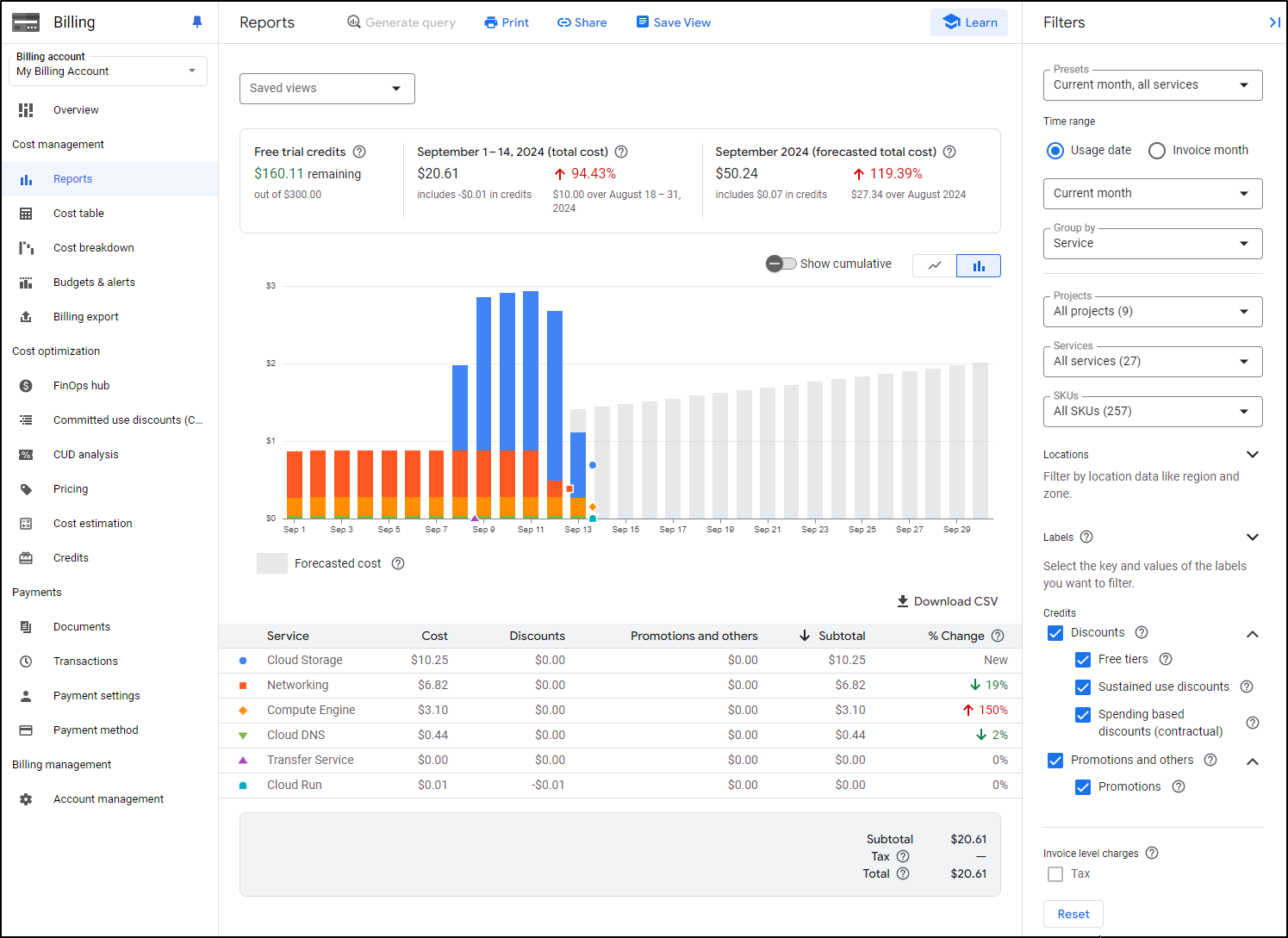
You can see that initially I assumed it was mostly due to the Loadbalancers (slated for $20/mo for a global forwarding rule) and i removed them.
However, I can now see my storage is a bit out of whack. Trimming further, I can start to narrow in the actual source of my costs
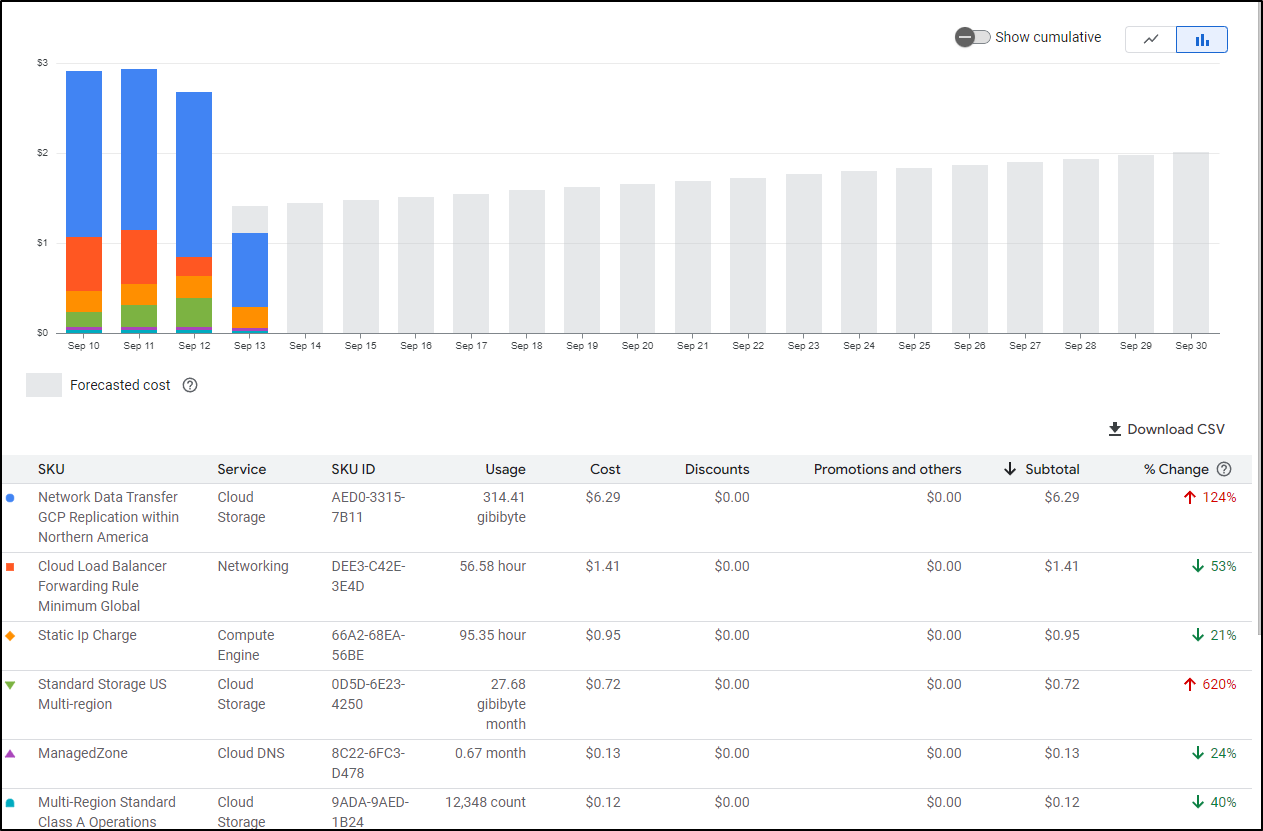
Jumping into storage I see something has gone quite wrong. One of my fuse buckets is already up to half a TB
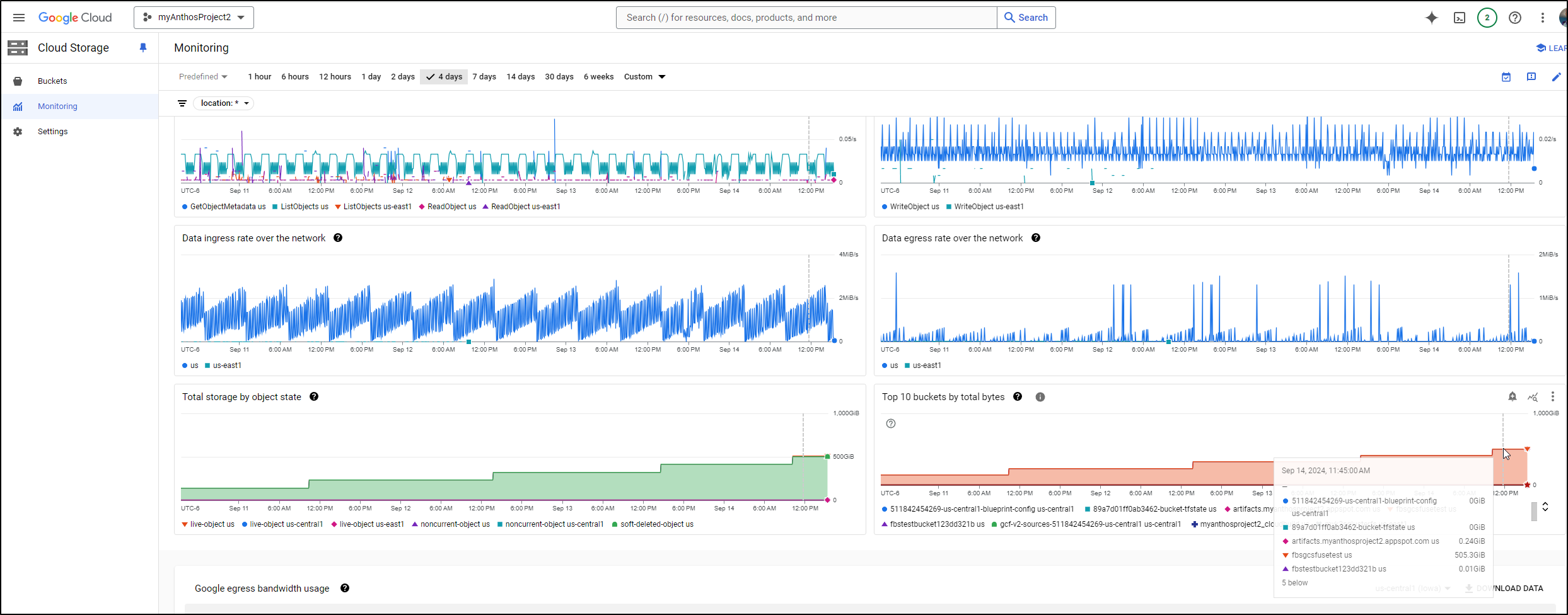
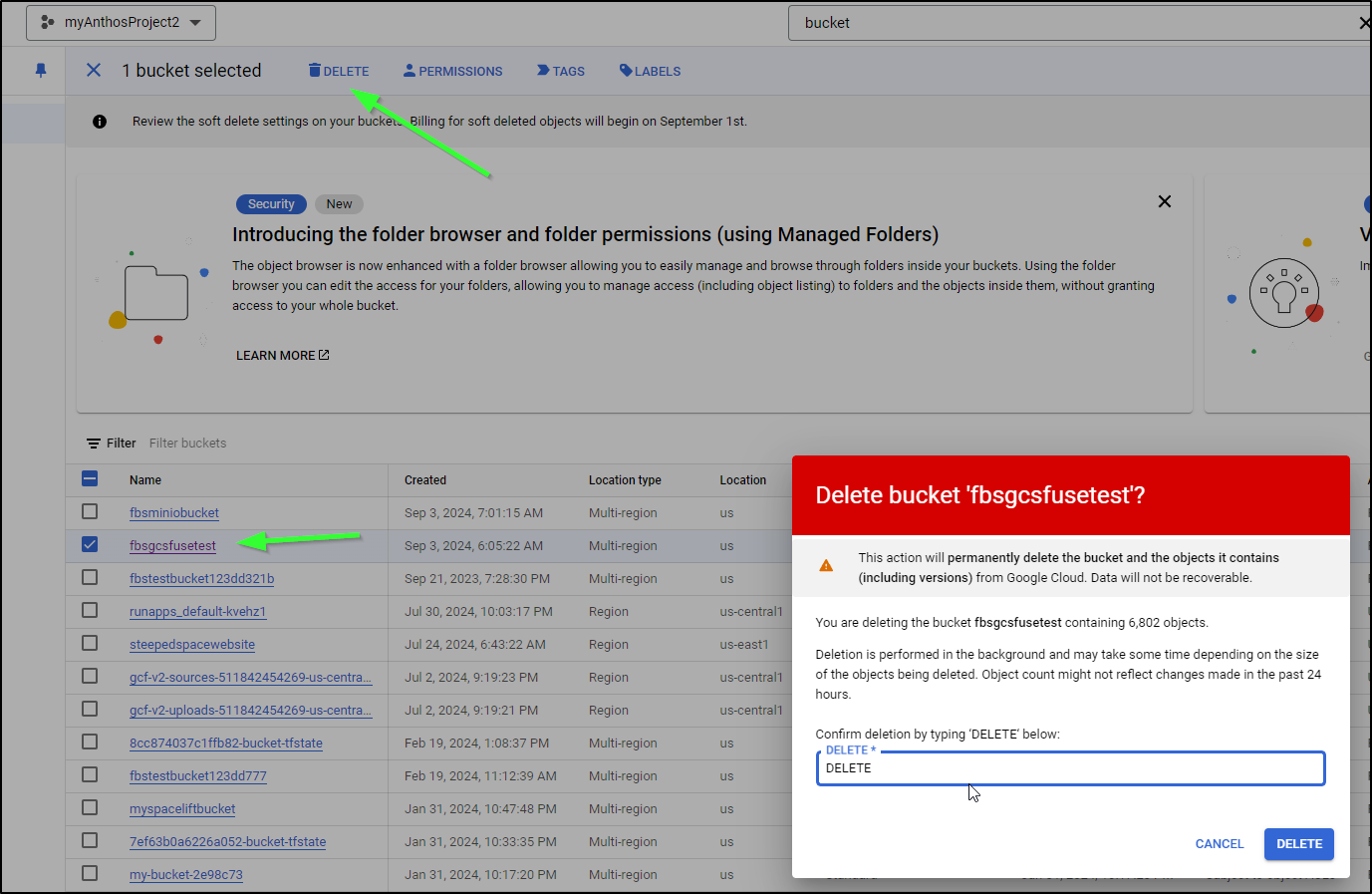
Clearly we need to figure out that “fbsgcsfusetest” bucket.
I can see every hour it spikes on writes
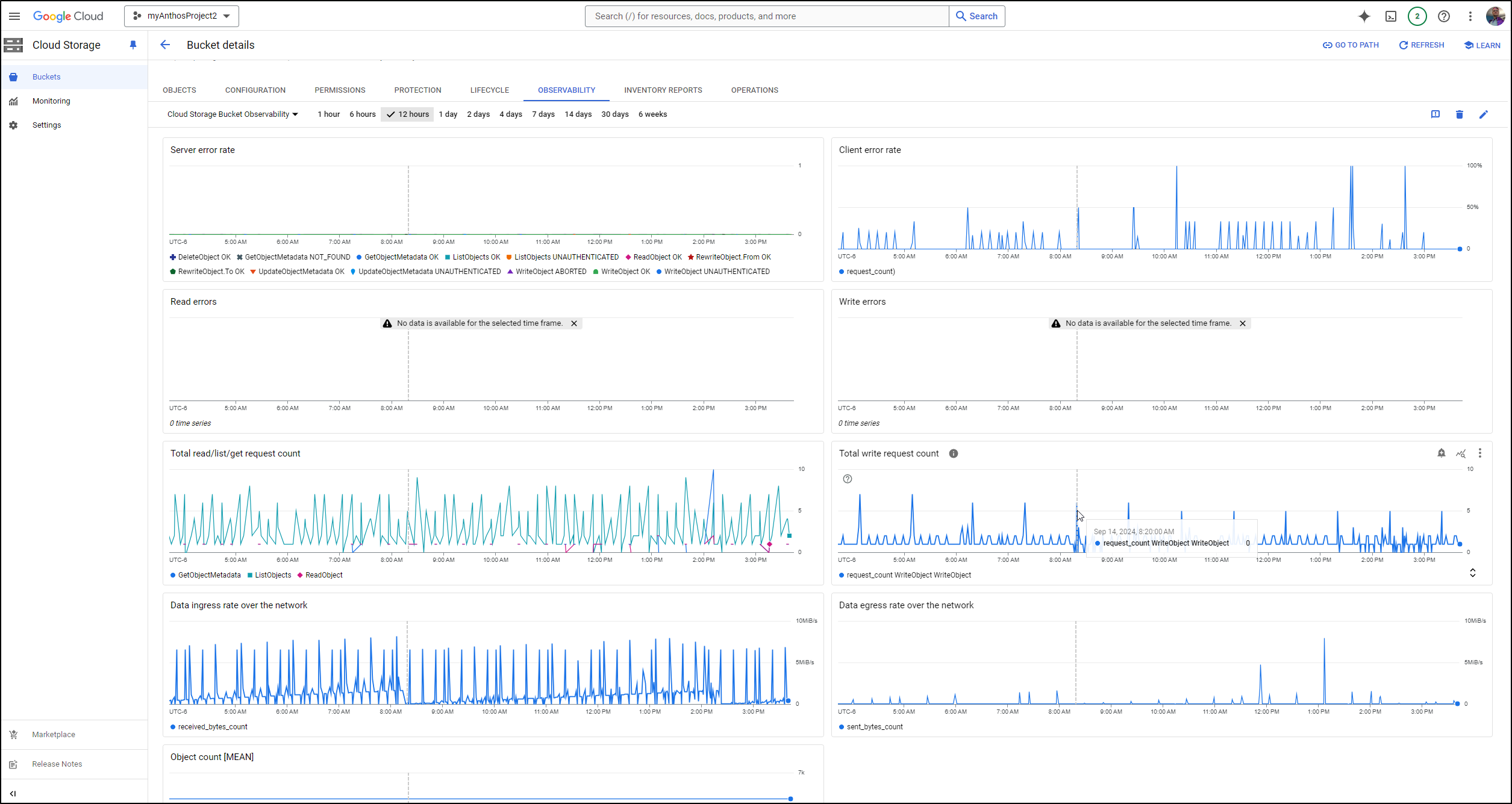
In that bucket, what catches my eye is minio and Synology Cloud Sync.
The Cloud Sync shows current timestamps on PVCs that don’t really change much.
I recall I had this fuse bucket also mounted to our Dockerhost for the Filegator backups.
I went there and did a du -chs
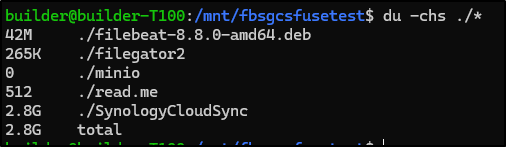
It’s barely 2.8Gb
I can also see that filegator is empty, save for logs as is minio
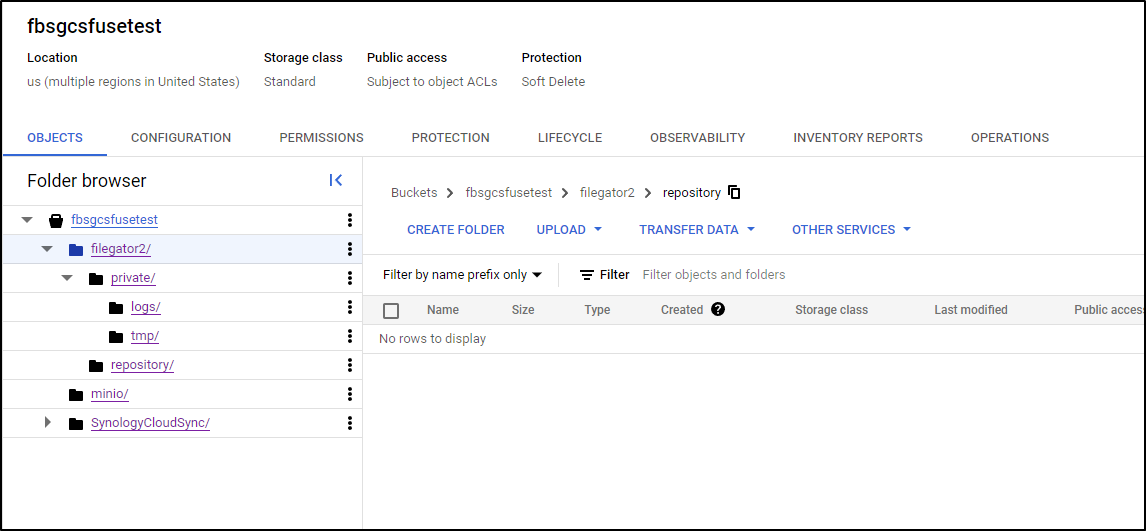
My first action is to remove the mounts from Dockerhost (.100) by first cleaning out the fstab
builder@builder-T100:/mnt/fbsgcsfusetest$ cat /etc/fstab | grep fbsgcsfusetest
fbsgcsfusetest /mnt/fbsgcsfusegator gcsfuse rw,allow_other,file_mode=777,dir_mode=777,key_file=/home/builder/sa-storage-key.json
fbsgcsfusetest /mnt/test1234 gcsfuse rw,user,exec,umask=0000,key_file=/home/builder/sa-storage-key.json
builder@builder-T100:/mnt/fbsgcsfusetest$ sudo vi /etc/fstab
builder@builder-T100:/mnt/fbsgcsfusetest$ cat /etc/fstab | grep fbsgcsfusetest
builder@builder-T100:/mnt/fbsgcsfusetest$ sudo umount /mnt/fbsgcsfusegator
builder@builder-T100:/mnt/fbsgcsfusetest$ sudo umount /mnt/test1234
umount: /mnt/test1234: not mounted.
I verified neither was used in cron
I removed the mounts from the master node of test cluster
builder@anna-MacBookAir:~$ ls /mnt/fbsgcsfusetest/
filebeat-8.8.0-amd64.deb filegator2 minio read.me SynologyCloudSync
builder@anna-MacBookAir:~$ cat /etc/fstab | grep fbsgcsfusetest
fbsgcsfusetest /mnt/fbsgcsfusetest gcsfuse rw,allow_other,file_mode=777,dir_mode=777,key_file=/home/builder/sa-storage-key.json
builder@anna-MacBookAir:~$ sudo vi /etc/fstab
builder@anna-MacBookAir:~$ cat /etc/fstab | grep fbsgcsfusetest
builder@anna-MacBookAir:~$ sudo umount /mnt/fbsgcsfusetest
On the NAS, i can see the sync job
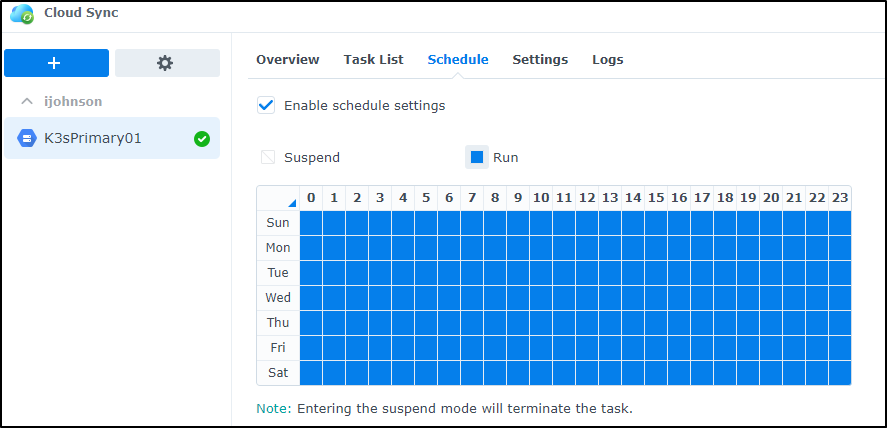
The schedule shows it’s set to run every day every hour
From the logs, it appears to just be uploading endlessly
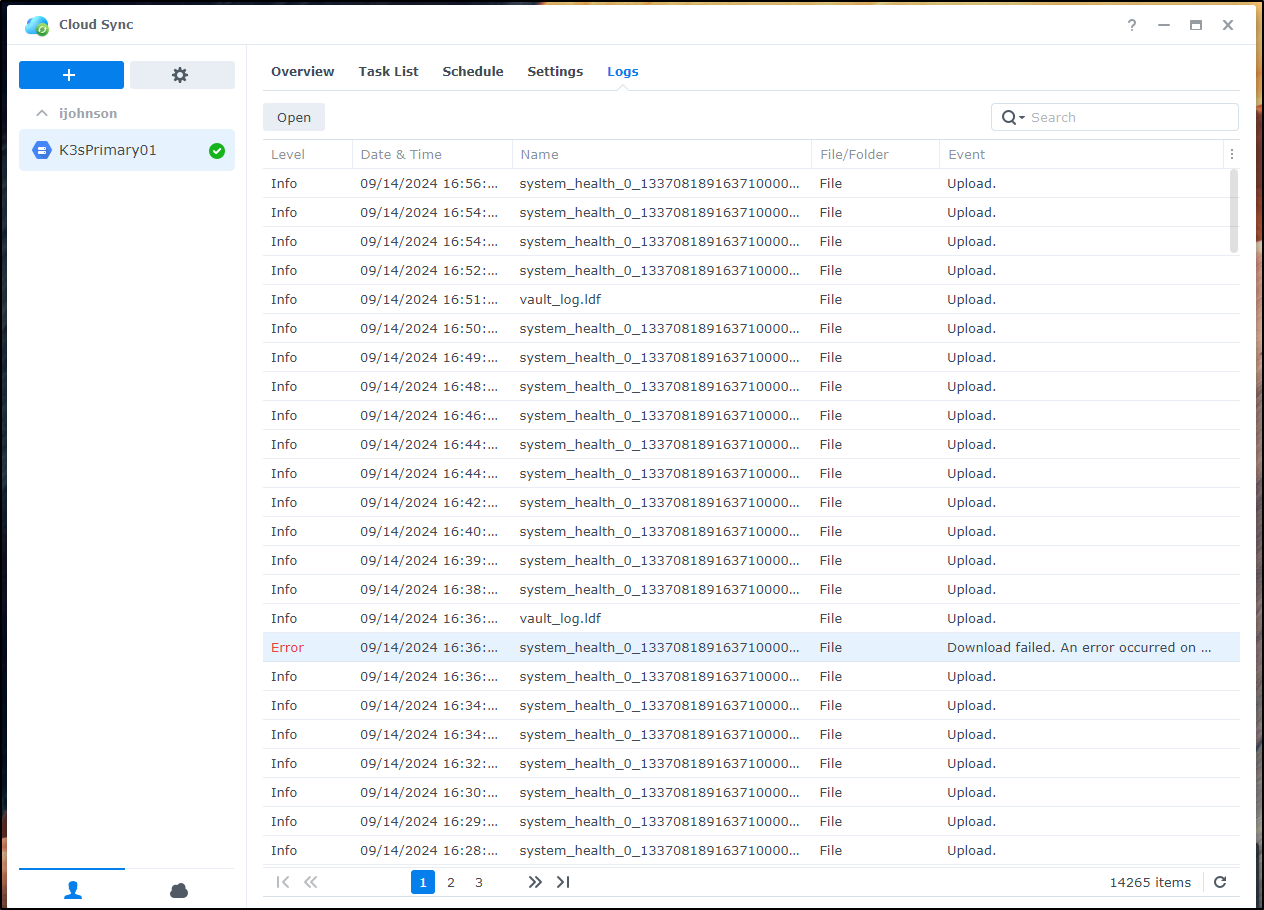
For now, I’m going to unlink
Confirm
and now I can see an empty Cloud Sync setup
And just to be certain this is dead, I’ll delete the bucket
By the next day I could see the data ingress drop precipitiously, however
How might I do this better?
Say that I still wanted cloud backups but the whole Cloud Sync tool from SYnology has erroded my confidence.
One method is to use a GCP Storage Transfer Service job which only transfers that which has changed. In our post a few weeks back about backups we covered setting up the STS agent on our Dockerhost.
Let us assume we wish to accomplish the same thing.
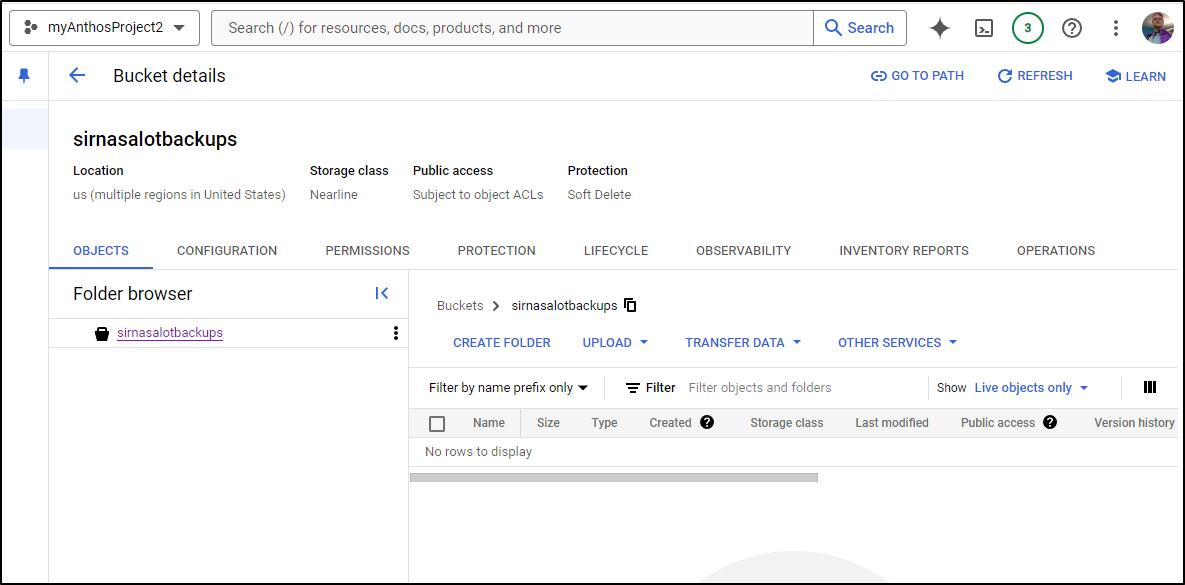
I’ll create a new bucket for this
$ gcloud storage buckets create gs://sirnasalotbackups --default-storage-class NEARLINE
Which I can verify was created and is empty
Assuming we want to back up the same thing - a PVC folder from my newer NAS
I can then make a directory to mount
builder@builder-T100:~$ sudo mkdir /mnt/sirnasilotk3sprimary01
Now I just add a line to fstab and mount it
builder@builder-T100:~$ cat /etc/fstab | tail -n1
192.168.1.116:/volume1/k3sPrimary01 /mnt/sirnasilotk3sprimary01 nfs auto,nofail,noatime,nolock,intr,tcp,actimeo=1800 0 0
builder@builder-T100:~$ sudo mount -a
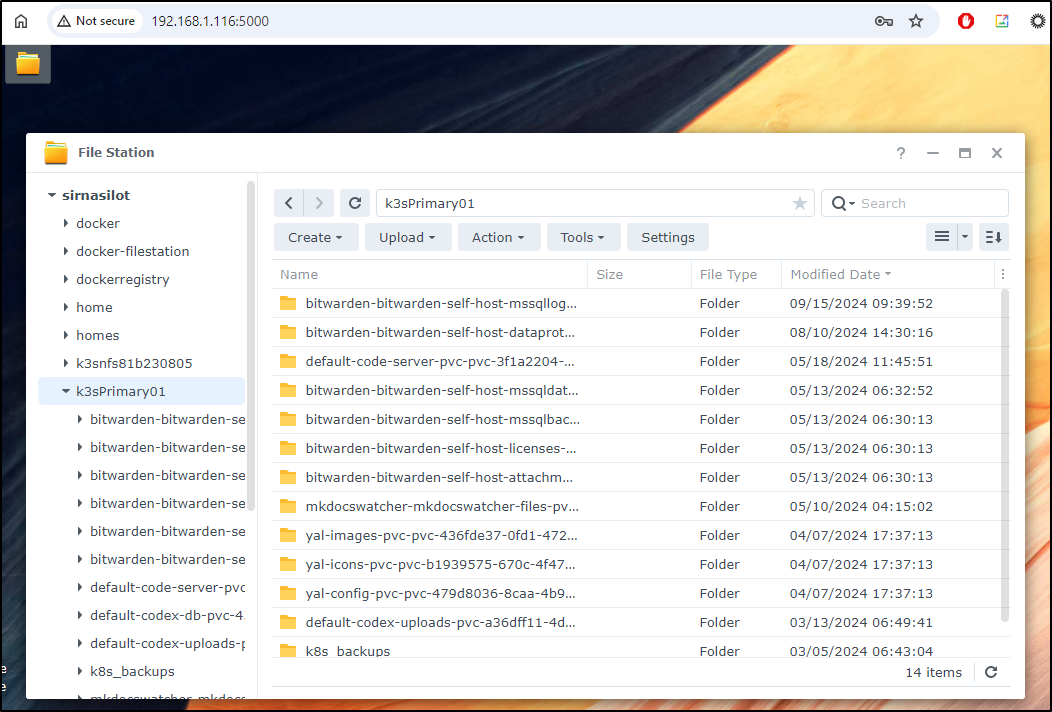
I can see it has the files now locally mounted with nfs
builder@builder-T100:~$ ls -ltra /mnt/sirnasilotk3sprimary01/
total 4
drwxrwxrwx 1 1024 users 78 Mar 3 2024 default-codex-db-pvc-45b099ea-a6ef-4582-8eed-8bdd5468c2a5
drwxrwxrwx 1 1024 users 72 Mar 5 2024 k8s_backups
drwxrwxrwx 1 1024 users 720 Mar 13 2024 default-codex-uploads-pvc-a36dff11-4dd6-4b2e-9840-89966e47e5ce
drwxrwxrwx 1 1024 users 0 Apr 7 17:37 yal-config-pvc-pvc-479d8036-8caa-4b92-bf53-8e942e2b38fd
drwxrwxrwx 1 1024 users 0 Apr 7 17:37 yal-icons-pvc-pvc-b1939575-670c-4f47-8ef5-cdaeb98e4ddb
drwxrwxrwx 1 1024 users 0 Apr 7 17:37 yal-images-pvc-pvc-436fde37-0fd1-472c-b44e-c51d5d953f31
drwxrwxrwx 1 1024 users 16 May 10 04:15 mkdocswatcher-mkdocswatcher-files-pvc-21259db3-0adc-41e3-b551-7d48ebb39d06
drwxrwxrwx 1 1024 users 0 May 13 06:30 bitwarden-bitwarden-self-host-attachments-pvc-729e0e07-1f6b-437b-bc0b-218d09f9495a
drwxrwxrwx 1 1024 users 0 May 13 06:30 bitwarden-bitwarden-self-host-mssqlbackups-pvc-8fc9f435-cec4-4248-aaf9-a234e1ac0123
drwxrwxrwx 1 1024 users 0 May 13 06:30 bitwarden-bitwarden-self-host-licenses-pvc-23b8938f-3835-4ced-8e53-eaf13c2926e7
drwxrwxrwx 1 root root 1852 May 13 06:30 .
drwxrwxrwx 1 1024 users 412 May 13 06:32 bitwarden-bitwarden-self-host-mssqldata-pvc-eef88ddc-e312-4e14-925c-0eb0f0808501
drwxrwxrwx 1 1024 users 122 May 18 11:45 default-code-server-pvc-pvc-3f1a2204-8f78-4196-adfb-55d3286fbd08
drwxrwxrwx 1 1024 users 176 Aug 10 14:30 bitwarden-bitwarden-self-host-dataprotection-pvc-269dcd5a-e055-4181-bbbe-11b27ed9c0db
drwxr-xr-x 15 root root 4096 Sep 15 15:28 ..
drwxrwxrwx 1 1024 users 932 Sep 15 15:47 bitwarden-bitwarden-self-host-mssqllog-pvc-b5607637-d557-462f-8e94-1398318319b5
I can now create a new Transfer Job
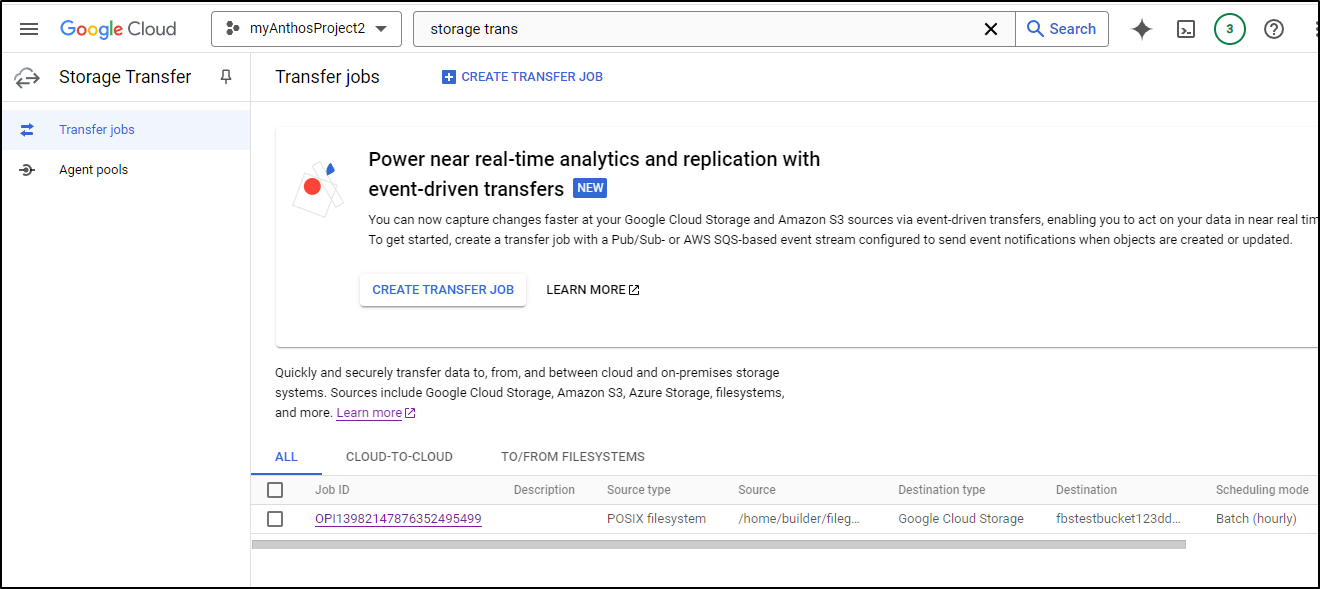
I’ll choose POSIX to Google Cloud Storage
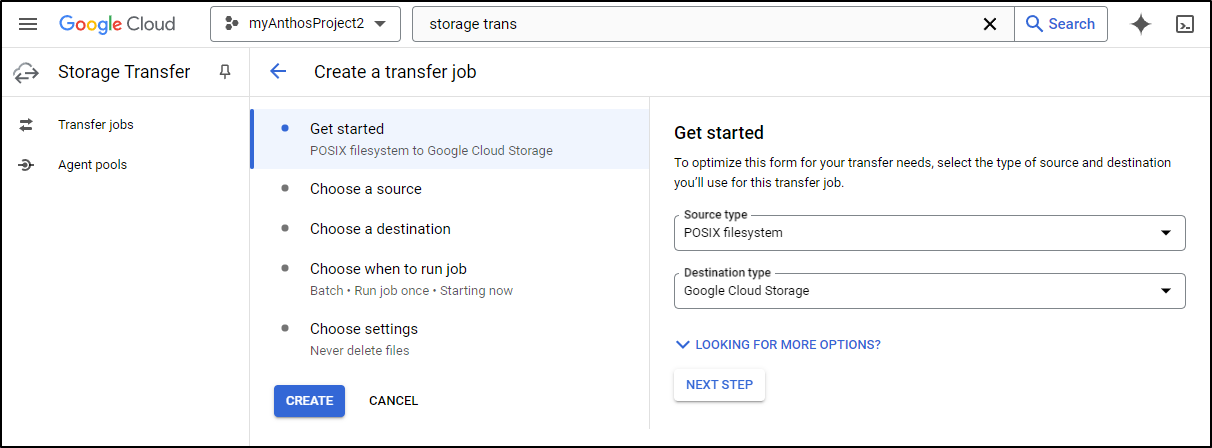
I can now pick the Dockerhost agent and it’s local path - the one we just mounted with NFS
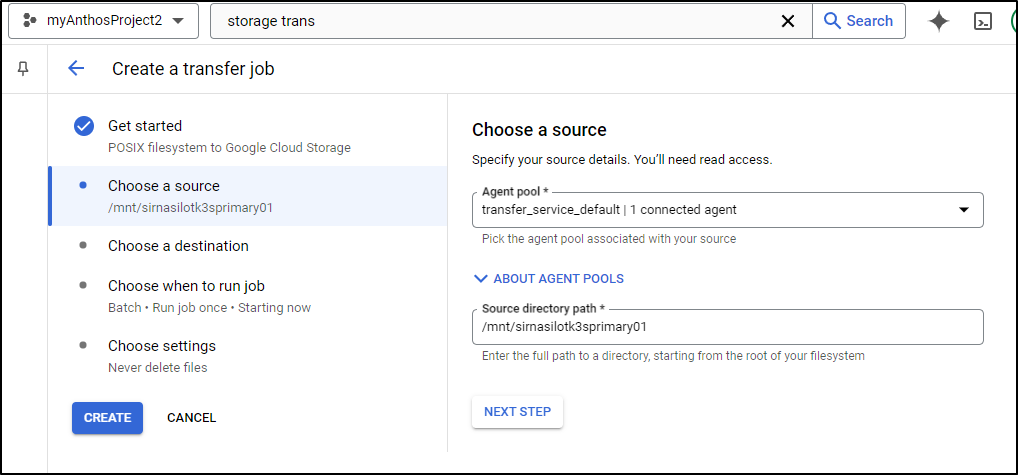
I’ll now browse and pick my new GCP bucket
We can now pick a schedule including just 1-time runs
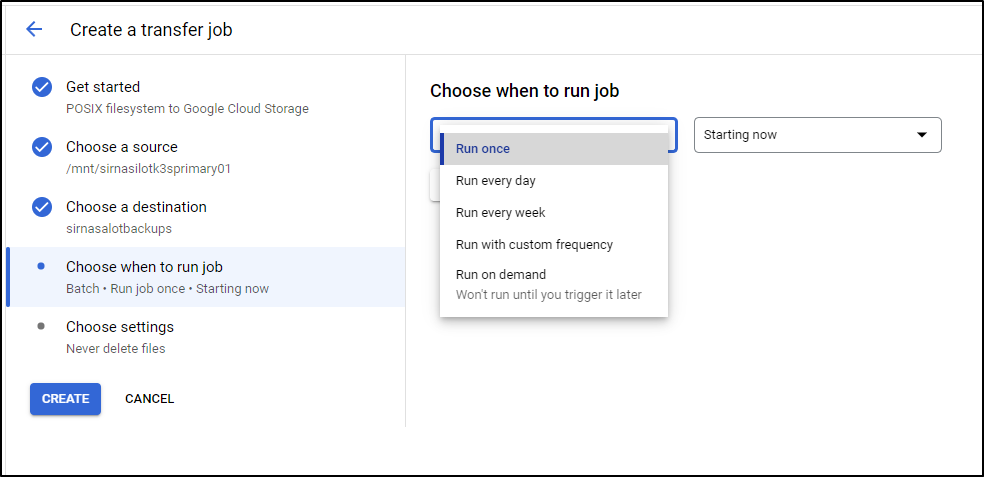
I think a weekly backup might be fine
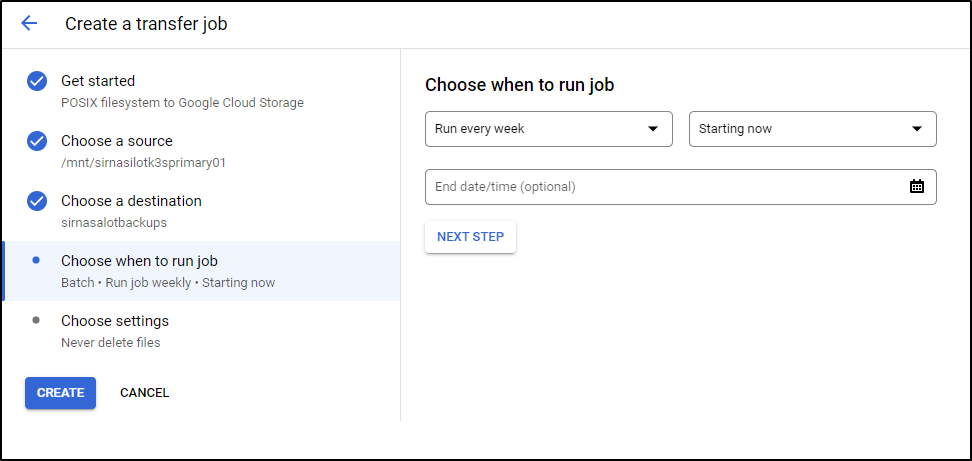
I can then enter a description and pick when we should override
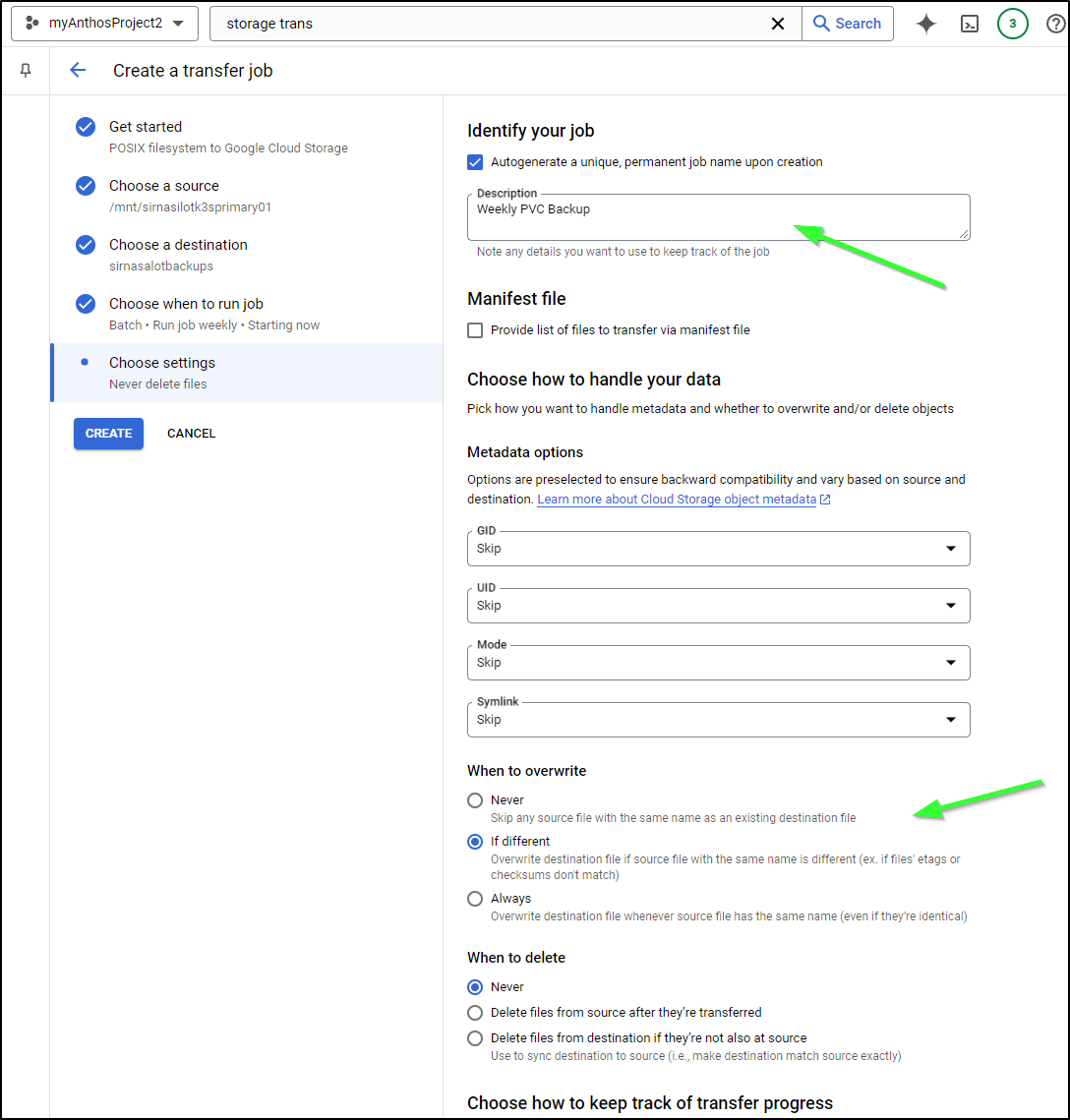
Now I see it setup
At first I saw an error
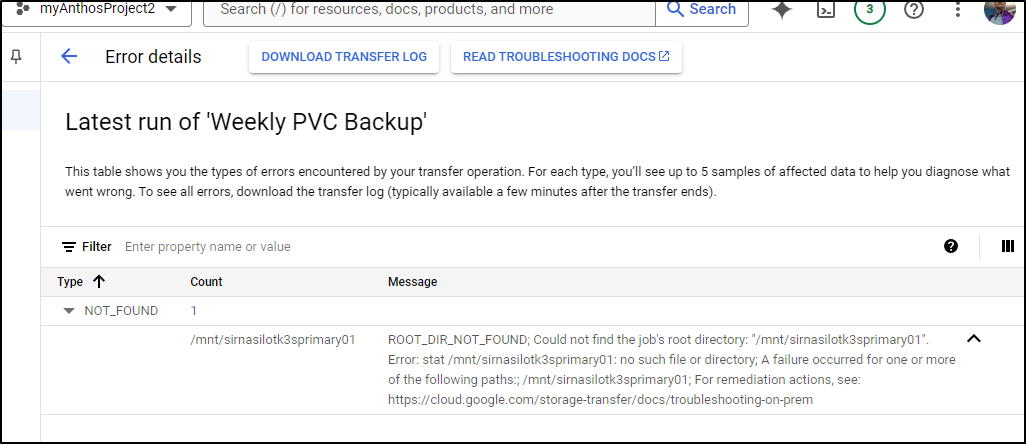
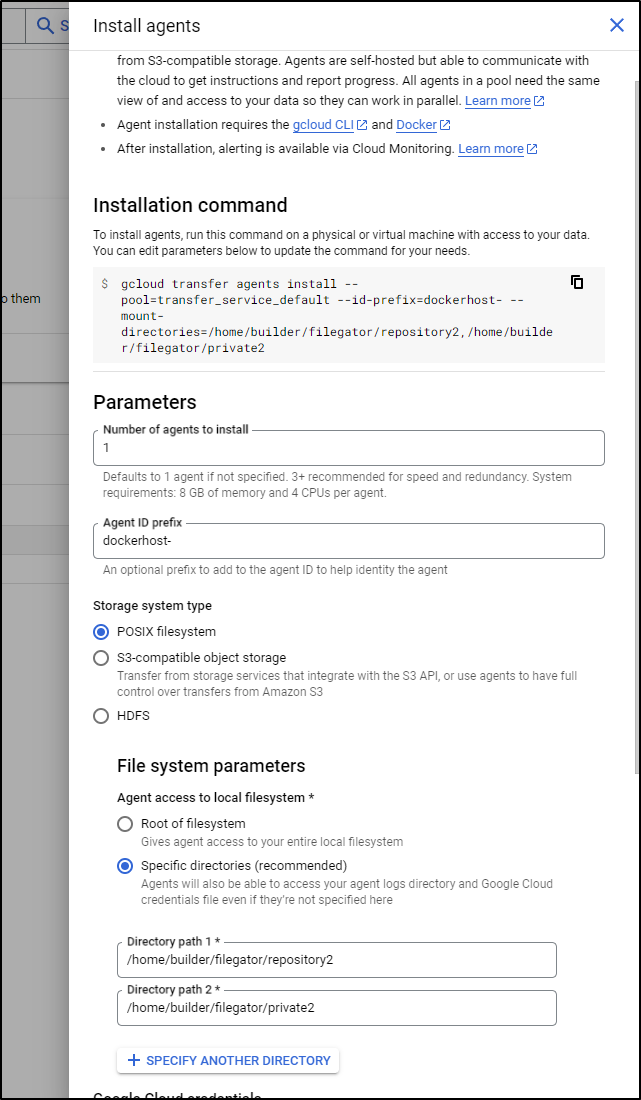
I think the issue is because I originally set the Transfer Agent up with specific sub directories:
builder@builder-T100:~$ gcloud transfer agents install --pool=transfer_service_default --id-prefix=dockerhost- --mount-directories=/home/builder/filegator/repository2,/home/builder/filegator/private2
I don’t really see an update option for STS agents, from the command line help
COMMANDS
COMMAND is one of the following:
delete
Delete a Transfer Service transfer agents.
install
Install Transfer Service agents.
I’ll remove and readd, though I have some kind of insane OTel collector that’s injecting debug into my stdout.
builder@builder-T100:~$ gcloud transfer agents install --pool=transfer_service_default --id-prefix=dockerhost- --mount-directories=/home/builder/filegator/repository2,/home/builder/filegator/private2,/mnt/sirnasilotk3sprimary01
2024-09-15 16:54:43,568 DEBUG [ddtrace.internal.module] [module.py:520] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - Calling 1 registered hooks on import of module 'urllib.request'
2024-09-15 16:54:43,944 DEBUG [ddtrace.sampler] [sampler.py:94] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - initialized RateSampler, sample 100.0% of traces
2024-09-15 16:54:44,011 DEBUG [ddtrace._trace.span] [span.py:375] [dd.service=lib dd.env= dd.version= dd.trace_id=17936441102373549520 dd.span_id=2660256420217627321] - ignoring not number metric _dd1.sr.eausr:None
2024-09-15 16:54:44,013 DEBUG [ddtrace.appsec._remoteconfiguration] [_remoteconfiguration.py:60] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - [1186658][P: 760399] Register ASM Remote Config Callback
2024-09-15 16:54:44,013 DEBUG [ddtrace._trace.tracer] [tracer.py:868] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - finishing span name='sqlite.query' id=2660256420217627321 trace_id=136782453707437134270993554655088276944 parent_id=None service='sqlite' resource='PRAGMA busy_timeout = 1000' type='sql' start=1726437284.011195 end=1726437284.0124462 duration=0.001251167 error=0 tags={'_dd.base_service': 'lib', '_dd.injection.mode': 'host', '_dd.p.dm': '-0', '_dd.p.tid': '66e757a400000000', 'component': 'sqlite', 'db.system': 'sqlite', 'language': 'python', 'runtime-id': 'e262551064f3402abdd7ad1063156023', 'span.kind': 'client'} metrics={'_dd.measured': 1, '_dd.top_level': 1, '_dd.tracer_kr': 1.0, '_sampling_priority_v1': 1, 'db.row_count': -1, 'process_id': 1186658} links='' events='' (enabled:True)
[1/3] Credentials found ✓
[2/3] Docker found ✓
2024-09-15 16:54:45,012 DEBUG [ddtrace.internal.writer.writer] [writer.py:250] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - creating new intake connection to unix:///var/run/datadog/apm.socket with timeout 2
2024-09-15 16:54:45,013 DEBUG [ddtrace.internal.writer.writer] [writer.py:254] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - Sending request: PUT v0.5/traces {'Datadog-Meta-Lang': 'python', 'Datadog-Meta-Lang-Version': '3.11.9', 'Datadog-Meta-Lang-Interpreter': 'CPython', 'Datadog-Meta-Tracer-Version': '2.11.3', 'Datadog-Client-Computed-Top-Level': 'yes', 'Datadog-Entity-ID': 'in-59077654', 'Content-Type': 'application/msgpack', 'X-Datadog-Trace-Count': '54'}
2024-09-15 16:54:45,032 DEBUG [ddtrace.internal.writer.writer] [writer.py:262] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - Got response: 200 OK
2024-09-15 16:54:45,032 DEBUG [ddtrace.internal.writer.writer] [writer.py:268] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - sent 6.2KB in 0.01996s to unix:///var/run/datadog/apm.socket/v0.5/traces
2024-09-15 16:54:45,311 DEBUG [ddtrace.internal.remoteconfig._subscribers] [_subscribers.py:45] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - [PID 1186658 | PPID 760399] Subscriber GlobalConfig is getting data
2024-09-15 16:54:45,312 DEBUG [ddtrace.internal.remoteconfig._subscribers] [_subscribers.py:47] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - [PID 1186658 | PPID 760399] Subscriber GlobalConfig got data
2024-09-15 16:54:45,312 DEBUG [ddtrace.internal.flare._subscribers] [_subscribers.py:53] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - No metadata received from data connector
1678e28e09059440b44deb10b47a370f9d1eab7e4848b03d48aa44d82253c8de
[3/3] Agent installation complete! ✓
To confirm your agents are connected, go to the following link in your browser,
and check that agent status is 'Connected' (it can take a moment for the status
to update and may require a page refresh):
https://console.cloud.google.com/transfer/on-premises/agent-pools/pool/transfer_service_default/agents?project=myanthosproject2
If your agent does not appear in the pool, check its local logs by running
"docker container logs [container ID]". The container ID is the string of random
characters printed by step [2/3]. The container ID can also be found by running
"docker container list".
2024-09-15 16:54:49,716 DEBUG [ddtrace.internal.remoteconfig.worker] [worker.py:113] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - [1186658][P: 1186658] Remote Config Poller fork. Stopping Pubsub services
2024-09-15 16:54:49,716 DEBUG [ddtrace.internal.runtime.runtime_metrics] [runtime_metrics.py:146] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - Writing metric runtime.python.gc.count.gen0:277
2024-09-15 16:54:49,719 DEBUG [ddtrace._trace.tracer] [tracer.py:313] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - Waiting 5 seconds for tracer to finish. Hit ctrl-c to quit.
2024-09-15 16:54:49,724 DEBUG [ddtrace.internal.telemetry.writer] [writer.py:752] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - generate-metrics request payload, namespace tracers
2024-09-15 16:54:51,530 DEBUG [ddtrace.internal.telemetry.writer] [writer.py:172] [dd.service=lib dd.env= dd.version= dd.trace_id=0 dd.span_id=0] - sent 7297 in 0.13236s to telemetry/proxy/api/v2/apmtelemetry. response: 202
I stopped the other agent and can see its now offline
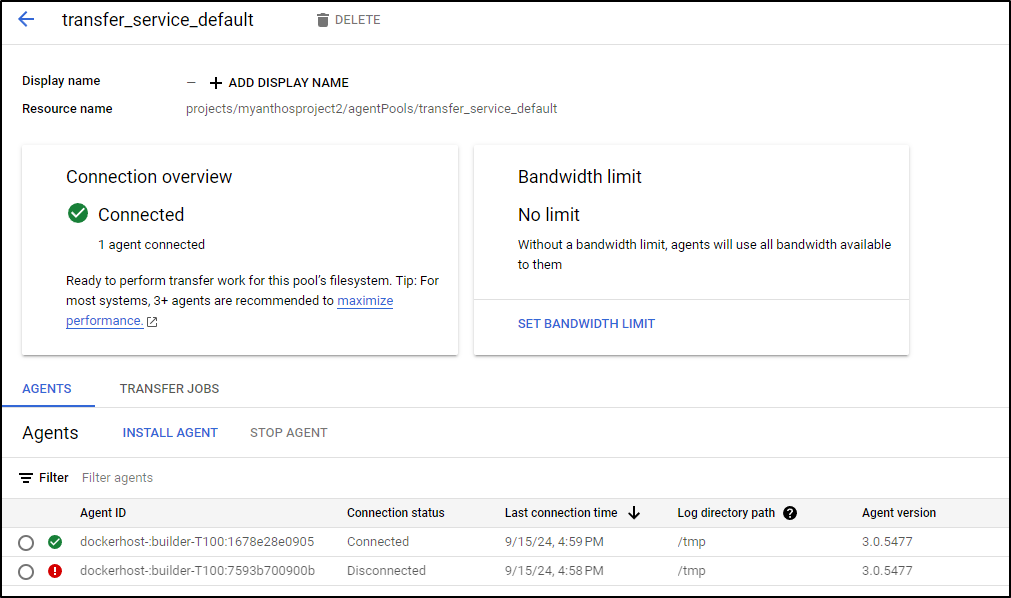
I then fired a new run
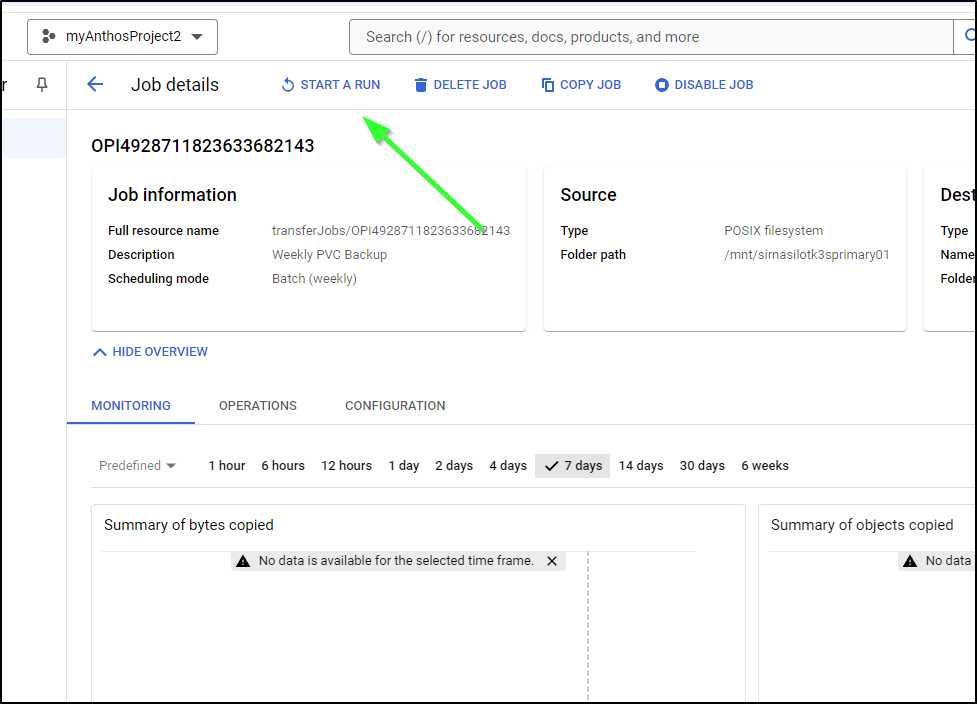
Then time in pending jobs, I can see it transferring
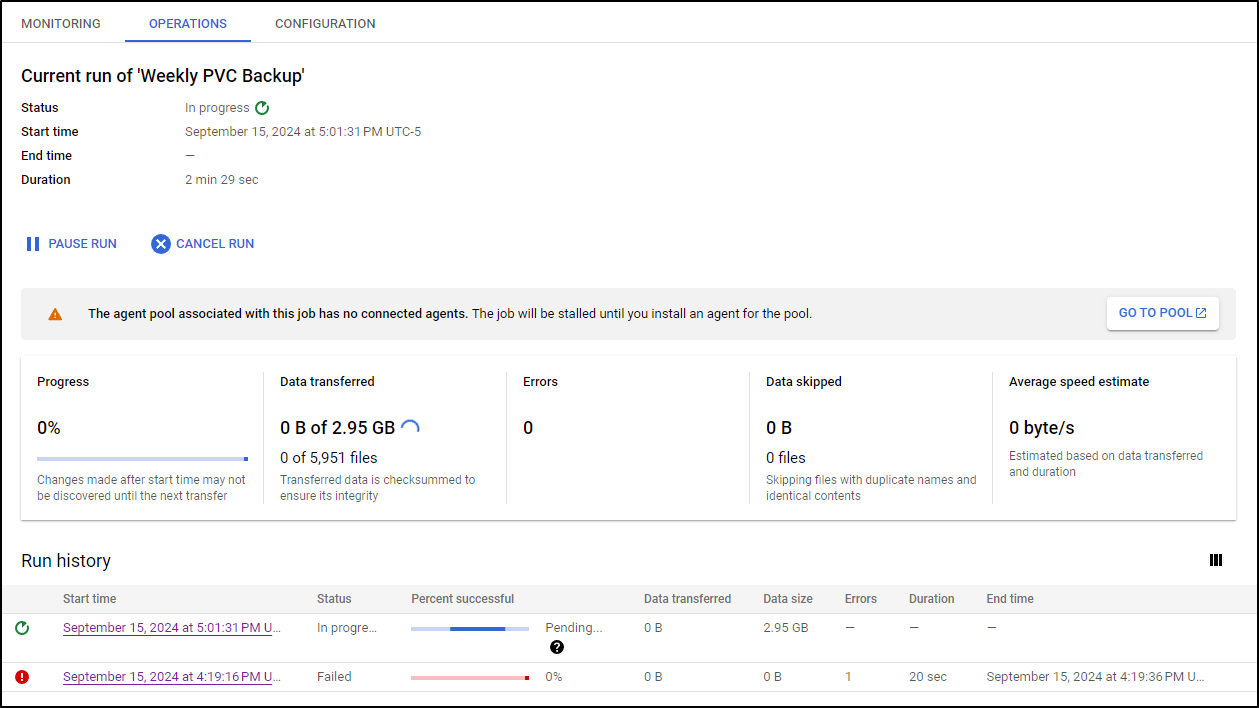
Interestingly enough, I went out to dinner and got a PagerDuty alert that my host was down.
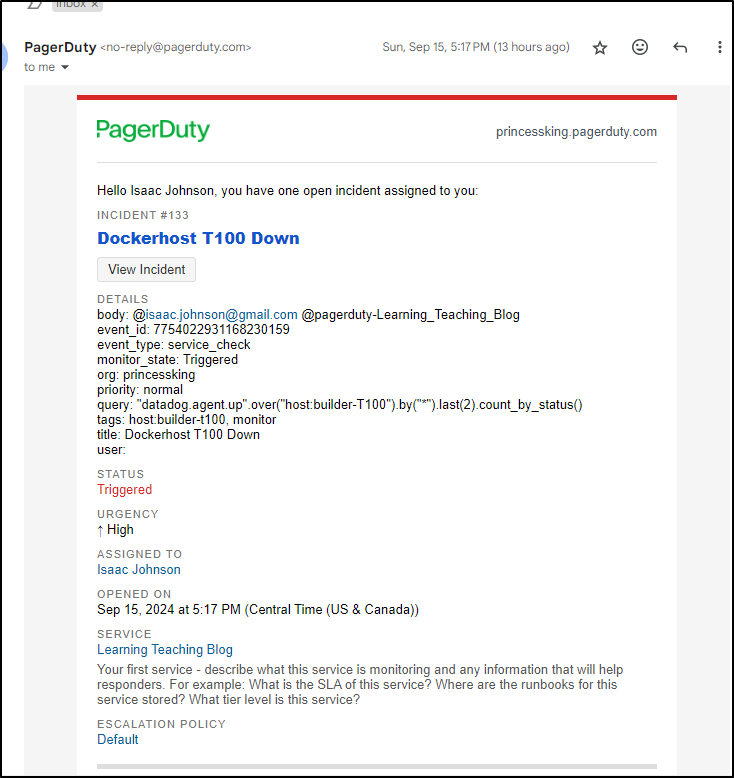
I rebooted but didn’t realize the STS agents are not set to auto-restart
In the morning, I logged in and fired one back up
builder@builder-T100:~$ gcloud transfer agents install --pool=transfer_service_default --id-prefix=dockerhost- --mount-directories=/home/builder/filegator/repository2,/home/builder/filegator/private2,/mnt/sirnasilotk3sprimary01/
and the job kicked back in where it had left off
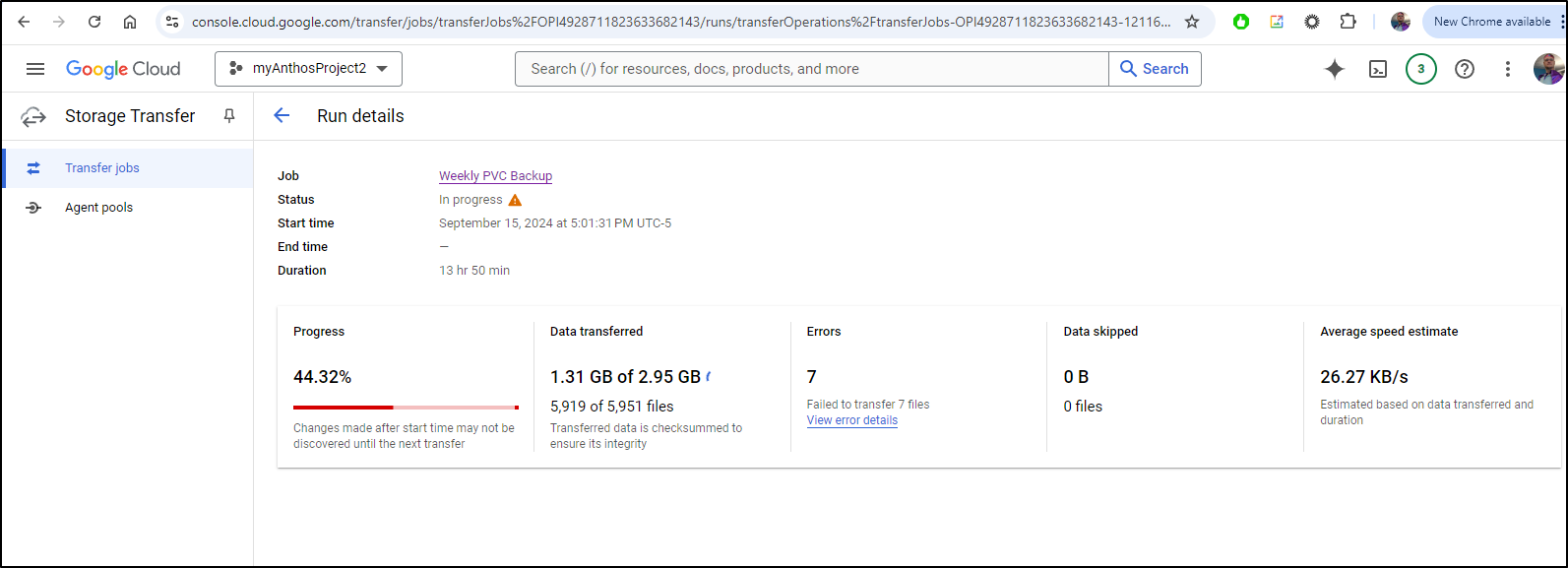
The next day I checked on it’s status and unfortunately I see it copied much but failed
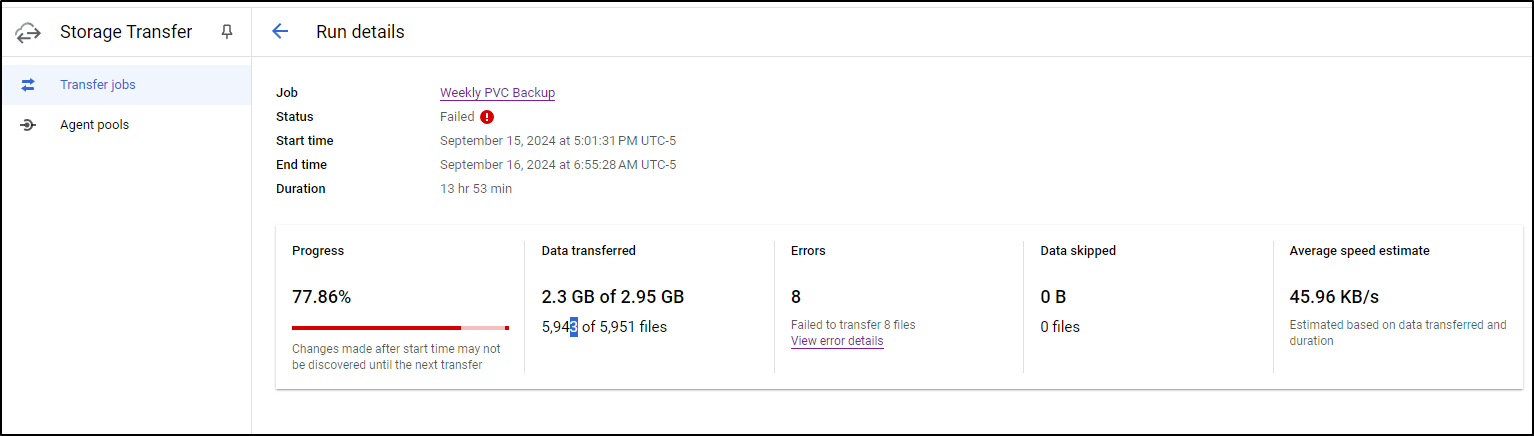
A few files disappeared during the run and some changed - this highlights the challenge in backuping live systems
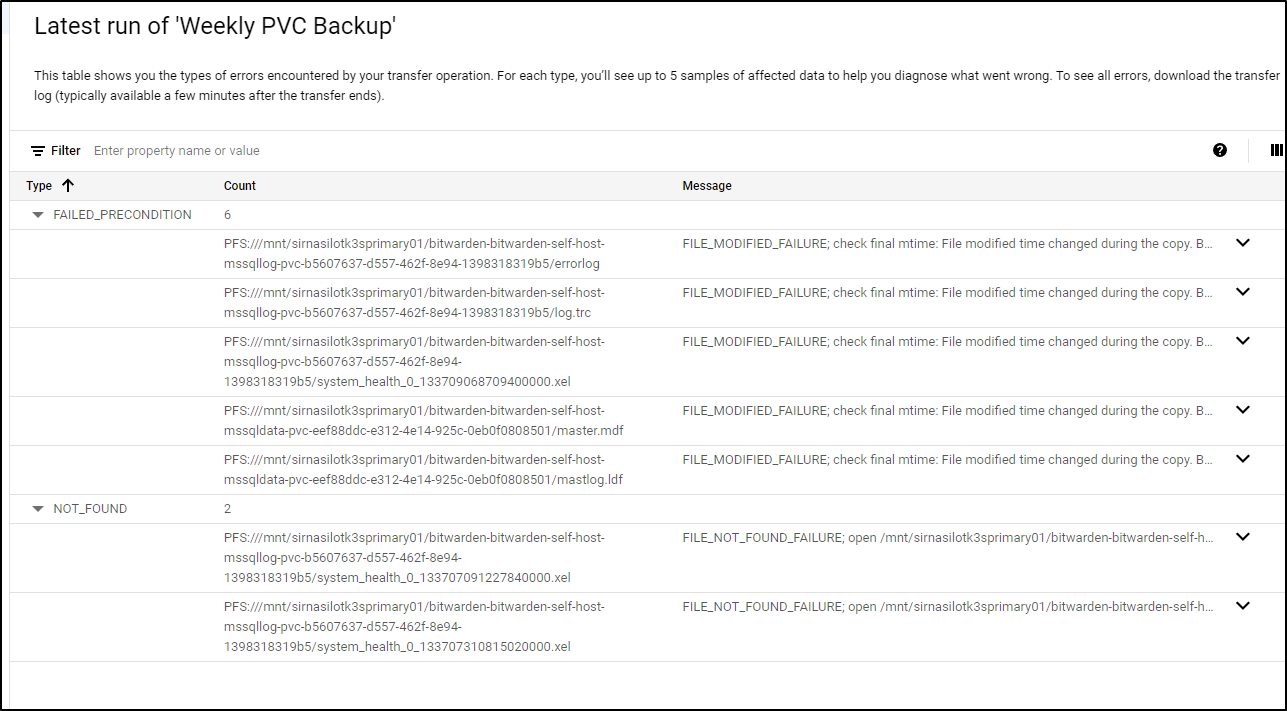
I’ll start another run
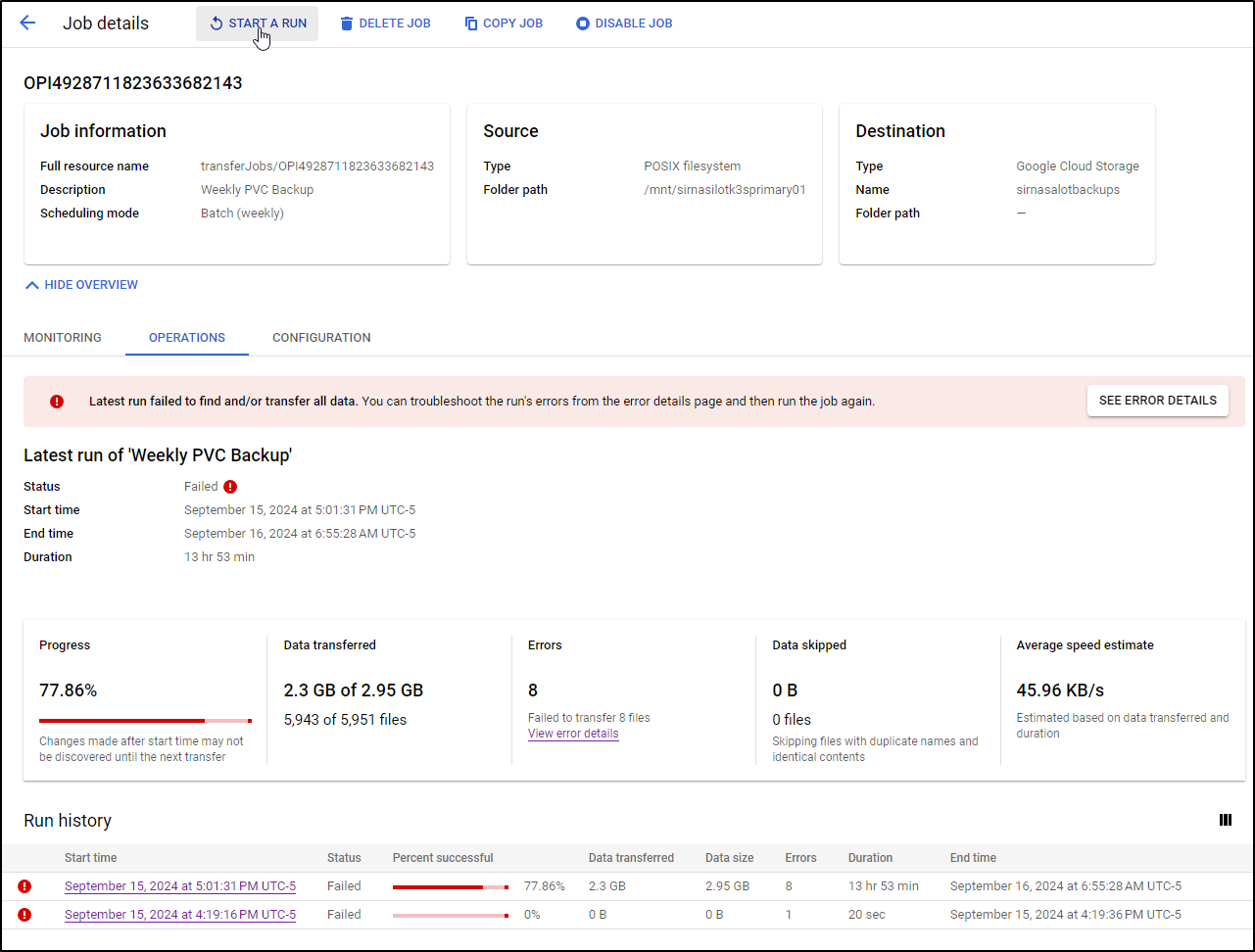
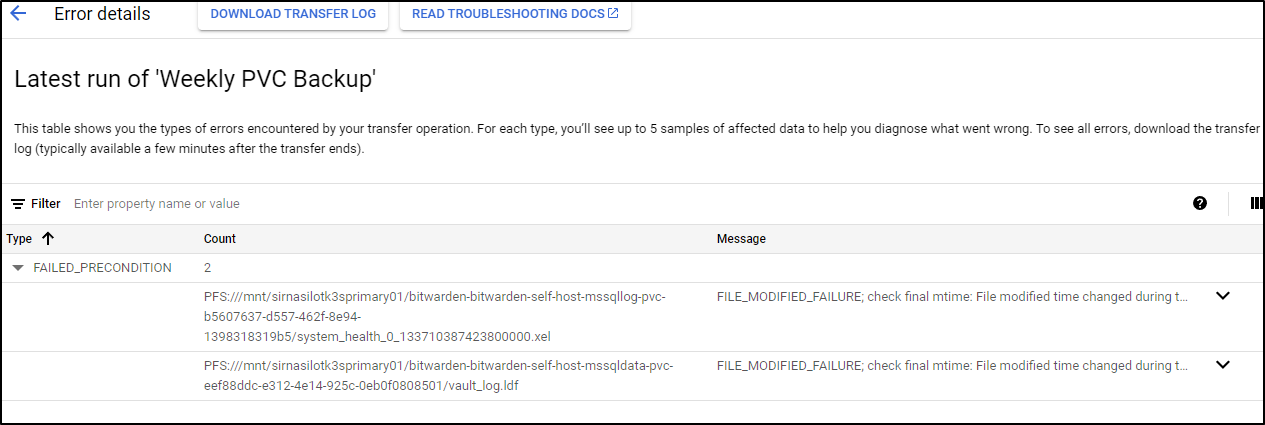
But after 5m that too failed

Really this is just because the PVC is every changing
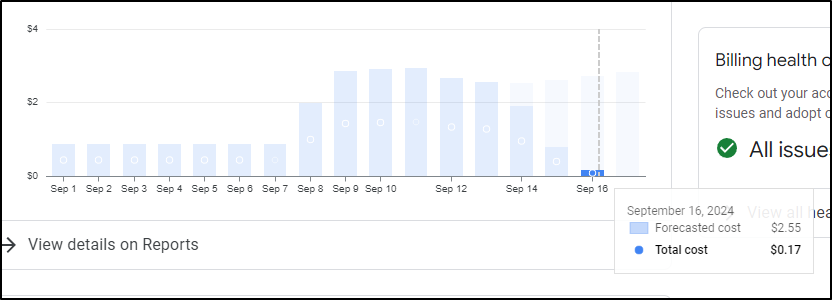
That said, looking in on costs again, it looked much much better, showing just 17c for the day
How we handle mutable fluid file systems
Okay, let’s deal with this the right way.
I’ll create a new local folder
builder@builder-T100:~$ mkdir sirnasilot-backups
builder@builder-T100:~$ pwd
/home/builder
I can do a quick test on the tgz command
builder@builder-T100:~$ tar -czf "/home/builder/sirnasilot-backups/sirnasilot_backup_$(date +%Y-%m-%d_%H-%M-%S).tar.gz" "/mnt/sirnasilotk3sprimary01"
tar: Removing leading `/' from member names
tar: /mnt/sirnasilotk3sprimary01/default-code-server-pvc-pvc-3f1a2204-8f78-4196-adfb-55d3286fbd08/data/code-server-ipc.sock: socket ignored
builder@builder-T100:~$ ls -ltrah sirnasilot-backups/
total 722M
drwxr-xr-x 65 builder builder 4.0K Sep 17 06:11 ..
drwxrwxr-x 2 builder builder 4.0K Sep 17 06:14 .
-rw-rw-r-- 1 builder builder 722M Sep 17 06:15 sirnasilot_backup_2024-09-17_06-14-10.tar.gz
# remove
builder@builder-T100:~$ rm ./sirnasilot-backups/sirnasilot_backup_2024-09-17_06-14-10.tar.gz
I then add to my crontab. I’ll set it to run in a couple minutes
builder@builder-T100:~$ crontab -e
crontab: installing new crontab
builder@builder-T100:~$ crontab -l | tail -n1
19 6 * * * tar -czf "/home/builder/sirnasilot-backups/sirnasilot_backup_$(date +%Y-%m-%d_%H-%M-%S).tar.gz" "/mnt/sirnasilotk3sprimary01"
builder@builder-T100:~$ date
Tue Sep 17 06:17:27 AM CDT 2024
So that I’ll be able to access this, I’ll drop my last Transfer Agent
builder@builder-T100:~$ docker ps | grep tsop-agent
e5ba09fa9719 gcr.io/cloud-ingest/tsop-agent:latest "python3 ./autoupdat…" 24 hours ago Up 24 hours
vibrant_lalande
builder@builder-T100:~$ docker stop vibrant_lalande
vibrant_lalande
builder@builder-T100:~$ docker rm vibrant_lalande
Error response from daemon: No such container: vibrant_lalande
Then add a new one with this new dir
$ gcloud transfer agents install --pool=transfer_service_default --id-prefix=dockerhost- --mount-directories=/home/builder/filegator/repository2,/home/builder/filegator/private2,/home/builder/sirnasilot-backups
I’ll delete the last
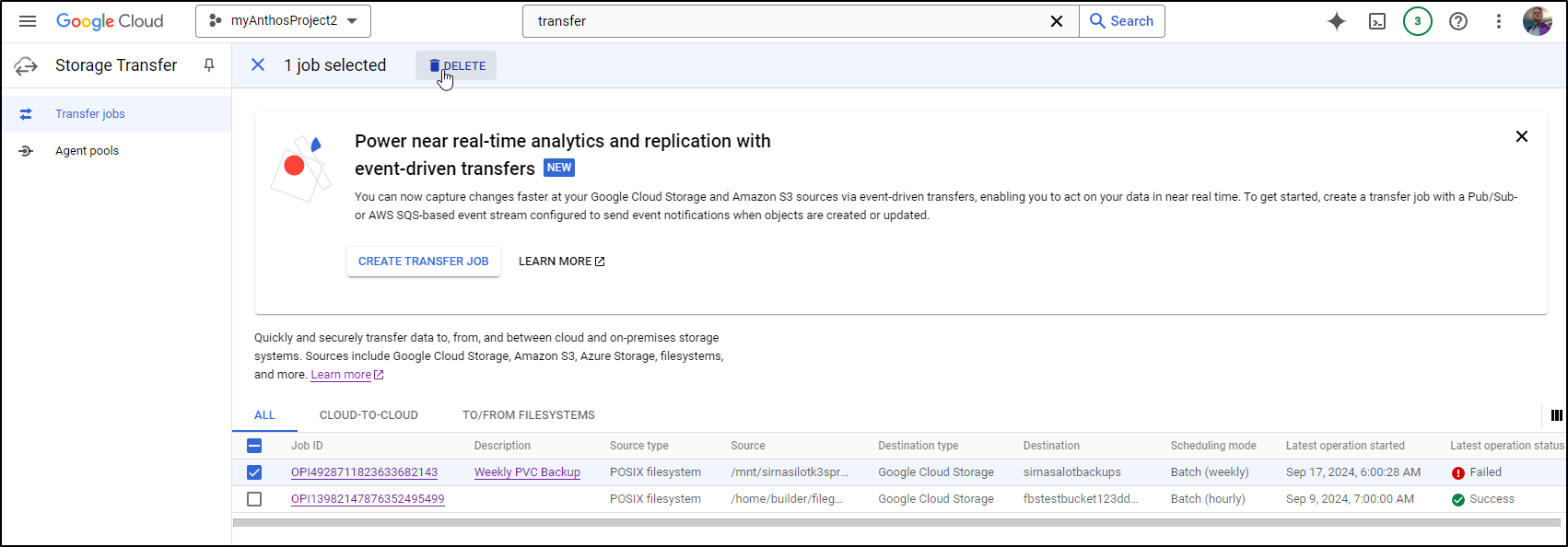
And empty the bucket
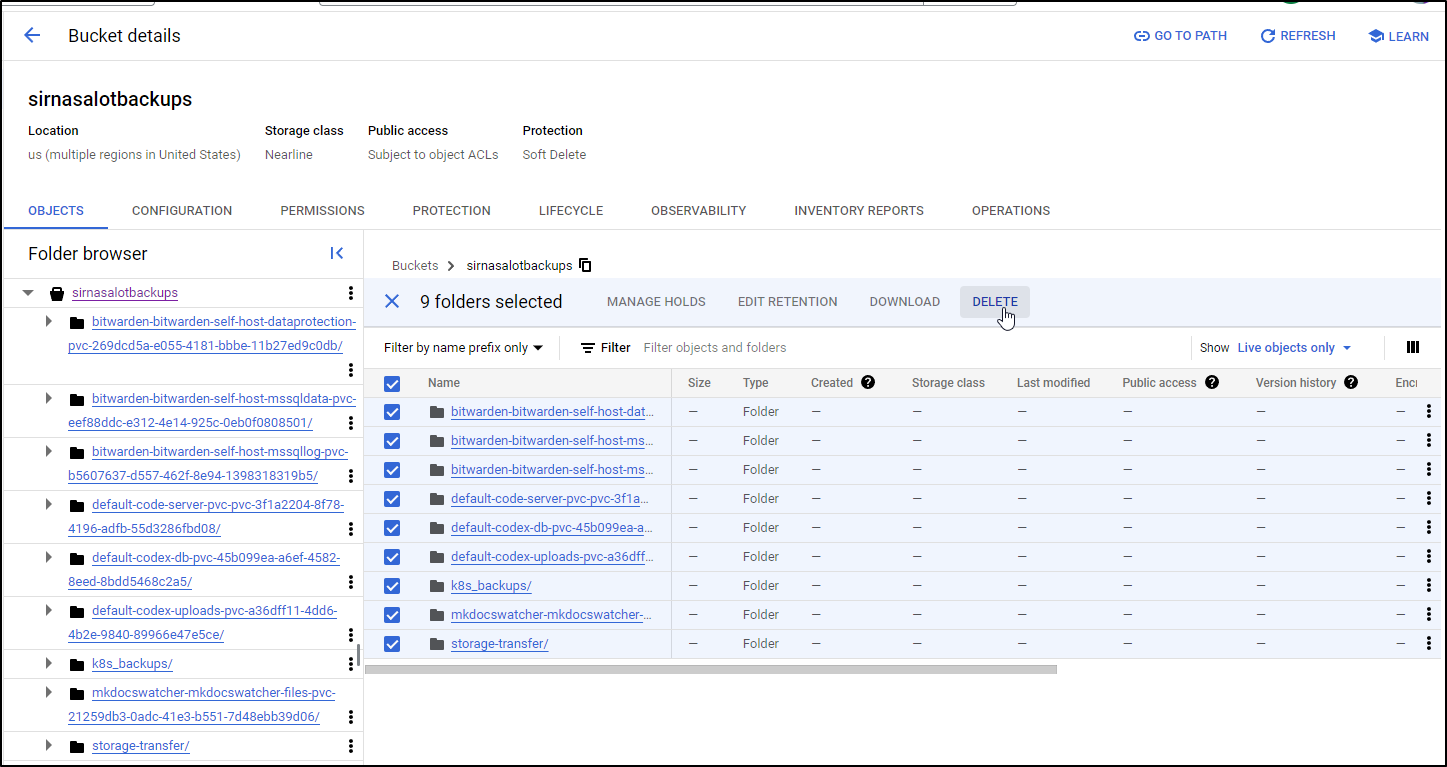
Let’s add this together
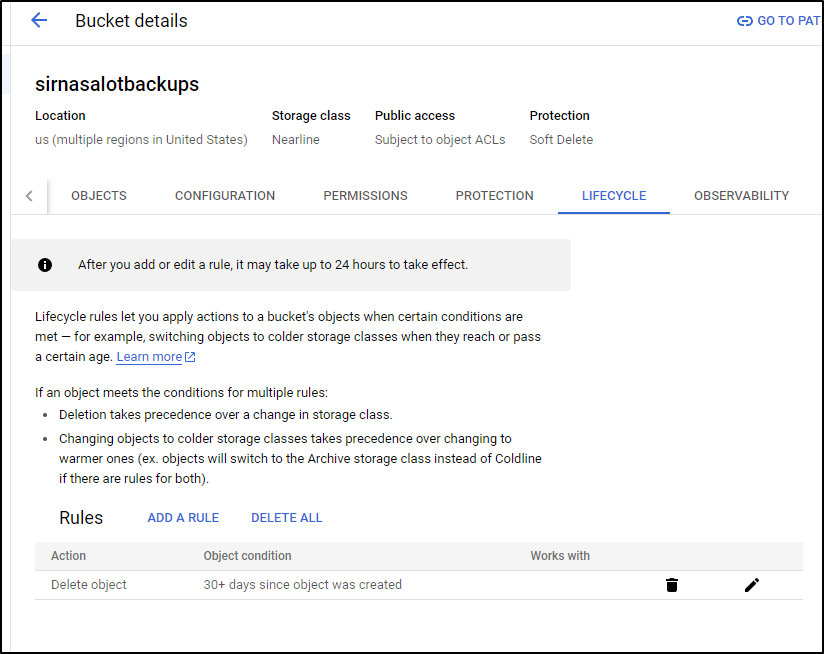
One more step we want to avoid infinitly filling this bucket and that is to set a lifecycle rule to delete old backups
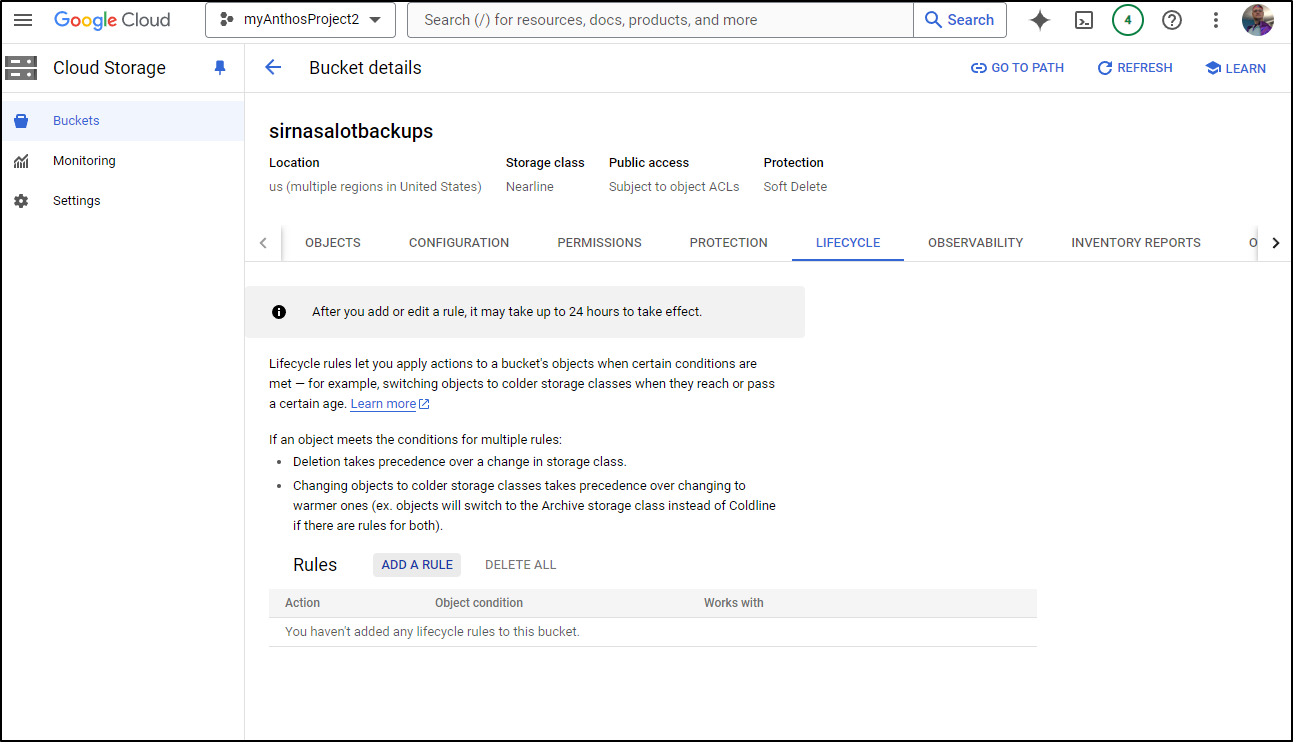
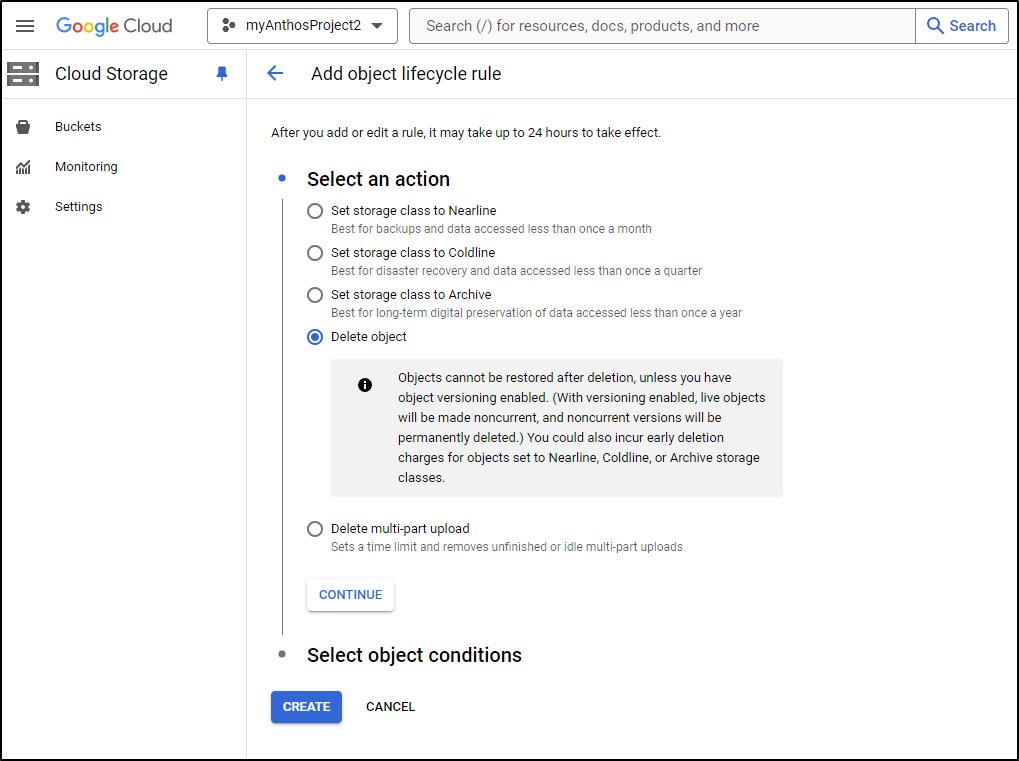
I’ll click Add Rule, then on the first step choose the Delete action
And give them 30 days of life
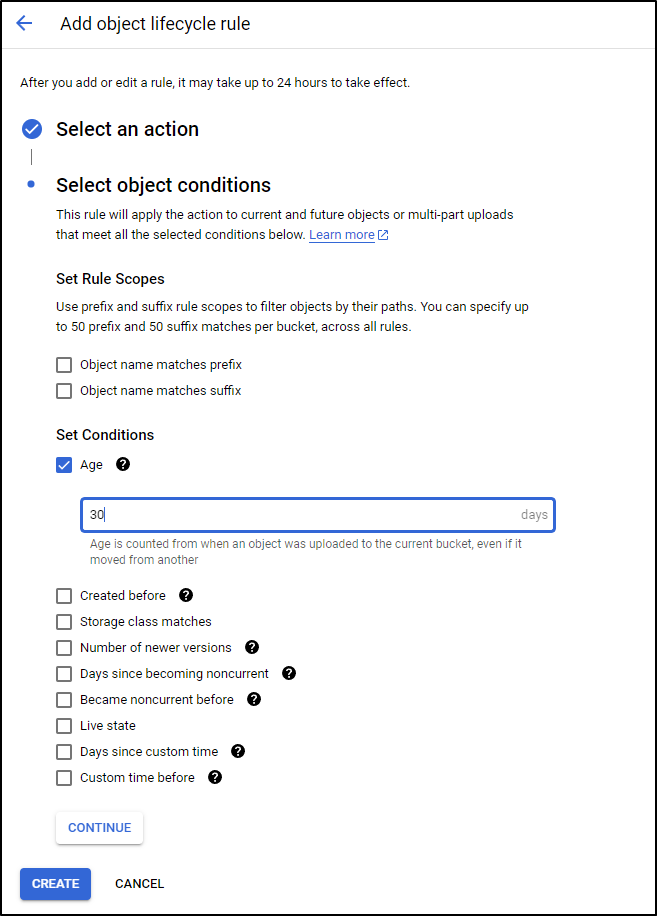
Then click create
And we can see it’s now set
Summary
Hopefully this showed how to avoid cost spikes with PagerDuty and budgets and then more important how we figure out from where our costs are coming. We then figured out how to accomplish the same goal (a backup of a live PVC) using a mix of crontab and Google Transfer Jobs.
These are the kinds of issues I encounter often as a Cloud Solution Architect - cost spikes and remdiations. It’s important that if you claim the role in an enterprise you can find and fix cost spikes. It’s quite easy to do things in GCP or any other cloud that just do not scale in terms of costs and it’s often our role to find and fix those things.
Note: If you want to see how to setup Budgets with AWS, Azure and Google Cloud that tie to PagerDuty, please see Cloud Budgets and Alerts where I cover setting all of that up.
