

Published: Mar 21, 2024 by Isaac Johnson
This is a different kind of Blog post. I started it one day realizing my cluster was simply falling down on resolving DNS to Github. All queries to api.github.com were going to nowhere.
I initially thought it was Github’s fault. But their status page was all good. I then thought it might be my Github Runner. In this writeup we watch as I try more and more things.
As of this writing, the cluster is dead. I’ve had to rebuild it all. I wish I would have backed things up before getting too deep. That said, I hope you enjoy as I desperately try to improve things, yet fail and fail again.
Half way through, you’ll see me pivot to a rebuild and we can cover trying to get data from a crashing cluster.
The start of Issues
I’ve been running the SummerWind Github Actions controller for nearly two years now. Recently, after a cluster crash, by runners would not reconnect
I saw errors about DNS
{"githubConfigUrl": "https://github.com/idjohnson/jekyll-blog"}
2024-02-28T22:12:24Z INFO listener-app getting runner registration token {"registrationTokenURL": "https://api.github.com/repos/idjohnson/jekyll-blog/actions/runners/registration-token"}
2024-02-28T22:12:54Z ERROR listener-app Retryable client error {"error": "Post \"https://api.github.com/repos/idjohnson/jekyll-blog/actions/runners/registration-token\": dial tcp: lookup api.github.com: i/o timeout", "method": "POST", "url": "https://api.github.com/repos/idjohnson/jekyll-blog/actions/runners/registration-token", "error": "request failed"}
I tried moving to my latest runner custom image
$ kubectl edit RunnerDeployment new-jekyllrunner-deployment -o yaml
error: runnerdeployments.actions.summerwind.dev "new-jekyllrunner-deployment" could not be patched: Internal error occurred: failed calling webhook "mutate.runnerdeployment.actions.summerwind.dev": failed to call webhook: Post "https://actions-runner-controller-webhook.actions-runner-system.svc:443/mutate-actions-summerwind-dev-v1alpha1-runnerdeployment?timeout=10s": no endpoints available for service "actions-runner-controller-webhook"
You can run `kubectl replace -f /tmp/kubectl-edit-295327076.yaml` to try this update again.
Just looking at the webhook that fails shows we are at 582d
$ kubectl get mutatingwebhookconfiguration
NAME WEBHOOKS AGE
dapr-sidecar-injector 1 413d
rancher.cattle.io 2 353d
datadog-webhook 3 582d
cert-manager-webhook 1 582d
mutating-webhook-configuration 8 353d
actions-runner-controller-mutating-webhook-configuration 4 582d
vault-agent-injector-cfg 1 372d
The last known good one, while disconnected, at least shows it was there
$ kubectl logs new-jekyllrunner-deployment-6t44l-ncpp2
Defaulted container "runner" out of: runner, docker
2024-02-27 11:12:35.38 NOTICE --- Runner init started with pid 7
2024-02-27 11:12:35.55 DEBUG --- Github endpoint URL https://github.com/
2024-02-27 11:12:42.353 DEBUG --- Passing --ephemeral to config.sh to enable the ephemeral runner.
2024-02-27 11:12:42.361 DEBUG --- Configuring the runner.
--------------------------------------------------------------------------------
| ____ _ _ _ _ _ _ _ _ |
| / ___(_) |_| | | |_ _| |__ / \ ___| |_(_) ___ _ __ ___ |
| | | _| | __| |_| | | | | '_ \ / _ \ / __| __| |/ _ \| '_ \/ __| |
| | |_| | | |_| _ | |_| | |_) | / ___ \ (__| |_| | (_) | | | \__ \ |
| \____|_|\__|_| |_|\__,_|_.__/ /_/ \_\___|\__|_|\___/|_| |_|___/ |
| |
| Self-hosted runner registration |
| |
--------------------------------------------------------------------------------
# Authentication
√ Connected to GitHub
# Runner Registration
√ Runner successfully added
√ Runner connection is good
# Runner settings
√ Settings Saved.
2024-02-27 11:12:47.929 DEBUG --- Runner successfully configured.
{
"agentId": 1983,
"agentName": "new-jekyllrunner-deployment-6t44l-ncpp2",
"poolId": 1,
"poolName": "Default",
"ephemeral": true,
"serverUrl": "https://pipelinesghubeus2.actions.githubusercontent.com/qCliCWldvO6BBBswMSDoRLbsUjSq35ZPPBfSYwyE4OOX7bEFxU/",
"gitHubUrl": "https://github.com/idjohnson/jekyll-blog",
"workFolder": "/runner/_work"
2024-02-27 11:12:47.950 DEBUG --- Docker enabled runner detected and Docker daemon wait is enabled
2024-02-27 11:12:47.952 DEBUG --- Waiting until Docker is available or the timeout of 120 seconds is reached
}CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2024-02-27 11:12:54.655 NOTICE --- WARNING LATEST TAG HAS BEEN DEPRECATED. SEE GITHUB ISSUE FOR DETAILS:
2024-02-27 11:12:54.657 NOTICE --- https://github.com/actions/actions-runner-controller/issues/2056
√ Connected to GitHub
Current runner version: '2.309.0'
2024-02-27 11:12:57Z: Listening for Jobs
Runner update in progress, do not shutdown runner.
Downloading 2.313.0 runner
Waiting for current job finish running.
Generate and execute update script.
Runner will exit shortly for update, should be back online within 10 seconds.
Runner update process finished.
Runner listener exit because of updating, re-launch runner after successful update
Update finished successfully.
Restarting runner...
√ Connected to GitHub
Current runner version: '2.313.0'
2024-02-27 11:13:33Z: Listening for Jobs
2024-02-27 13:04:40Z: Runner connect error: The HTTP request timed out after 00:01:00.. Retrying until reconnected.
Looking into docs, I found they moved on some time ago to “ARC”, or “Actions Runner Controller”.
Custom image
I depend on a lot of things I would rather have baked into my image. This includes Pulumi binaries, OpenTofu and some older Ruby libraries. Ruby, in particular, is a beast to have to install over and over.
My old image was based on the now deprecated ‘summerwind’ image. I would need to build out a new Github Runner using ARC
I’ll spare you the endless back and forth as I discovered differences in the base image, but here is the before:
FROM summerwind/actions-runner:latest
RUN sudo apt update -y \
&& umask 0002 \
&& sudo apt install -y ca-certificates curl apt-transport-https lsb-release gnupg
# Install MS Key
RUN curl -sL https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/microsoft.gpg > /dev/null
# Add MS Apt repo
RUN umask 0002 && echo "deb [arch=amd64] https://packages.microsoft.com/repos/azure-cli/ focal main" | sudo tee /etc/apt/sources.list.d/azure-cli.list
# Install Azure CLI
RUN sudo apt update -y \
&& umask 0002 \
&& sudo apt install -y azure-cli awscli ruby-full
# Install Pulumi
RUN curl -fsSL https://get.pulumi.com | sh
# Install Homebrew
RUN /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# OpenTF
# Install Golang 1.19
RUN eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" \
&& brew install go@1.19
#echo 'export PATH="/home/linuxbrew/.linuxbrew/opt/go@1.19/bin:$PATH"'
RUN eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" \
&& brew install opentofu
RUN sudo cp /home/linuxbrew/.linuxbrew/bin/tofu /usr/local/bin/
RUN sudo chown runner /usr/local/bin
RUN sudo chmod 777 /var/lib/gems/2.7.0
RUN sudo chown runner /var/lib/gems/2.7.0
# Install Expect and SSHPass
RUN sudo apt update -y \
&& umask 0002 \
&& sudo apt install -y sshpass expect
# save time per build
RUN umask 0002 \
&& gem install bundler -v 2.4.22
# Limitations in newer jekyll
RUN umask 0002 \
&& gem install jekyll --version="~> 4.2.0"
RUN sudo rm -rf /var/lib/apt/lists/*
#harbor.freshbrewed.science/freshbrewedprivate/myghrunner:1.1.16
and the new
$ cat Dockerfile
FROM ghcr.io/actions/actions-runner:latest
RUN sudo apt update -y \
&& umask 0002 \
&& sudo apt install -y ca-certificates curl apt-transport-https lsb-release gnupg git build-essential
# Install MS Key
RUN curl -sLS https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor | sudo tee /etc/apt/keyrings/microsoft.gpg > /dev/null
# Add MS Apt repo
RUN umask 0002 && export AZ_DIST=$(lsb_release -cs) && echo "deb [arch=amd64 signed-by=/etc/apt/keyrings/microsoft.gpg] https://packages.microsoft.com/repos/azure-cli/ $AZ_DIST main" | sudo tee /etc/apt/sources.list.d/azure-cli.list
# Install Azure CLI
RUN sudo apt update -y \
&& umask 0002 \
&& sudo apt install -y azure-cli awscli ruby-full
# Install Pulumi
RUN curl -fsSL https://get.pulumi.com | sh
# Install Homebrew
RUN /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# OpenTF
# Install Golang 1.19
RUN eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" \
&& brew install go@1.19
#echo 'export PATH="/home/linuxbrew/.linuxbrew/opt/go@1.19/bin:$PATH"'
RUN eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" \
&& brew install opentofu
RUN sudo cp /home/linuxbrew/.linuxbrew/bin/tofu /usr/local/bin/
RUN sudo chown runner /usr/local/bin
# Ruby RVM
RUN sudo chmod 777 /var/lib/gems/*
RUN sudo chown runner /var/lib/gems/*
# Install Expect and SSHPass
RUN sudo apt update -y \
&& umask 0002 \
&& sudo apt install -y sshpass expect
# save time per build
RUN umask 0002 \
&& gem install bundler -v 2.4.22
# Limitations in newer jekyll
RUN umask 0002 \
&& gem install jekyll --version="~> 4.2.0"
RUN sudo rm -rf /var/lib/apt/lists/*
#harbor.freshbrewed.science/freshbrewedprivate/myghrunner:2.0.0
This is one of the rare cases I push right to main as this is for the runner image
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog/ghRunnerImage$ git add Dockerfile
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog/ghRunnerImage$ git branch --show-current
main
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog/ghRunnerImage$ git commit -m "GH Action Runner for 2.0.0"
[main f55bd73] GH Action Runner for 2.0.0
1 file changed, 9 insertions(+), 7 deletions(-)
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog/ghRunnerImage$ git push
Enumerating objects: 7, done.
Counting objects: 100% (7/7), done.
Delta compression using up to 16 threads
Compressing objects: 100% (4/4), done.
Writing objects: 100% (4/4), 644 bytes | 644.00 KiB/s, done.
Total 4 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
To https://github.com/idjohnson/jekyll-blog
4172b0f..f55bd73 main -> main
It honestly took the better part of a morning (while still doing my day job and checking occasionally) to get the image pushed. In fact, the only way to actually resurrect Harbor and keep it going was to do a helm upgrade (see Harbor section later).
That said, at least the part that pushes to Harbor completed
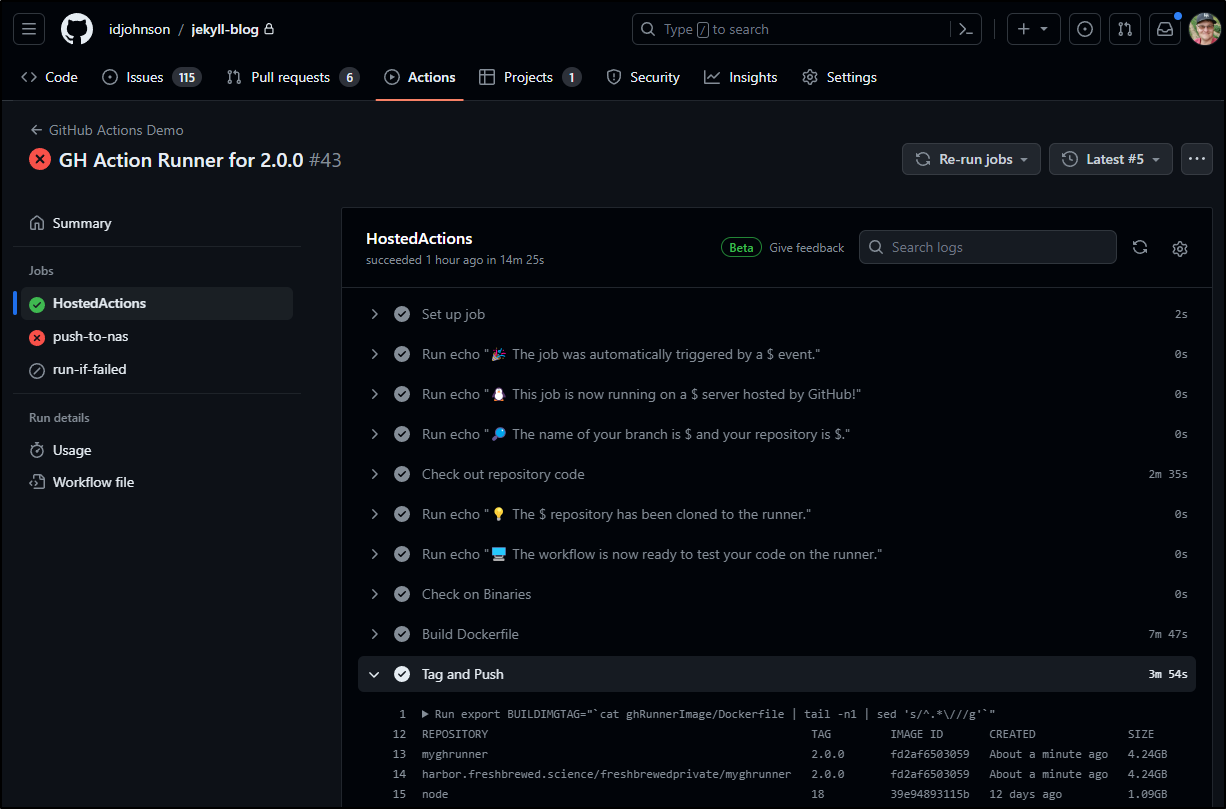
I don’t need to dig into the NAS step too much as I know i have restricted IPs that can upload files and the Docker host (T100) is not one.
Testing on Dev Cluster
As always, let’s first test on the dev cluster.
ARC is based on a provider which we can install with Helm. Luckily, in our more modern world of OCI Charts, we don’t need to add a helm repository, just use the CR directly.
$ helm install arc --namespace "arc-systems" --create-namespace oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set-controller
Pulled: ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set-controller:0.8.3
Digest: sha256:cc604073ea3e64896a86e02ce5c72113a84b81e5a5515758849a660ecfa49eea
NAME: arc
LAST DEPLOYED: Wed Feb 28 15:52:02 2024
NAMESPACE: arc-systems
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Thank you for installing gha-runner-scale-set-controller.
Your release is named arc.
That sets up the provider, just like Summerwind.dev used to do.
The next part is to create a “Runner Scale Set”.
It is here that I care about the runner image.
I set, first, the main variables I’ll need
$ INSTALLATION_NAME="arc-runner-set"
$ NAMESPACE="arc-runners"
$ GITHUB_CONFIG_URL="https://github.com/idjohnson/jekyll-blog"
$ GITHUB_PAT="ghp_ASDFASDFASDFASDFASDAFASDAFASDAAF"
I’m a bit stuck on this next part as their helm chart doesnt actually let me set an ImagePullSecret for the runner container (see here)
I’ll install with the default and circle back on this (Though I wish I could have set --set template.spec.containers[].image=harbor... --set template.spec.containers[].imagePullSecret=myharborreg…)
I ran the helm install
$ helm install "${INSTALLATION_NAME}" --namespace "${NAMESPACE}" --create-namespace --set githubConfigUrl="${GITHUB_CONFIG_URL}" --set githubConfigSecret.github_token="${GITHUB_PAT}" oci://ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set
Pulled: ghcr.io/actions/actions-runner-controller-charts/gha-runner-scale-set:0.8.3
Digest: sha256:83f2f36a07038f120340012352268fcb2a06bbf00b0c2c740500a5383db5f91a
NAME: arc-runner-set
LAST DEPLOYED: Wed Feb 28 16:01:53 2024
NAMESPACE: arc-runners
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Thank you for installing gha-runner-scale-set.
Your release is named arc-runner-set.
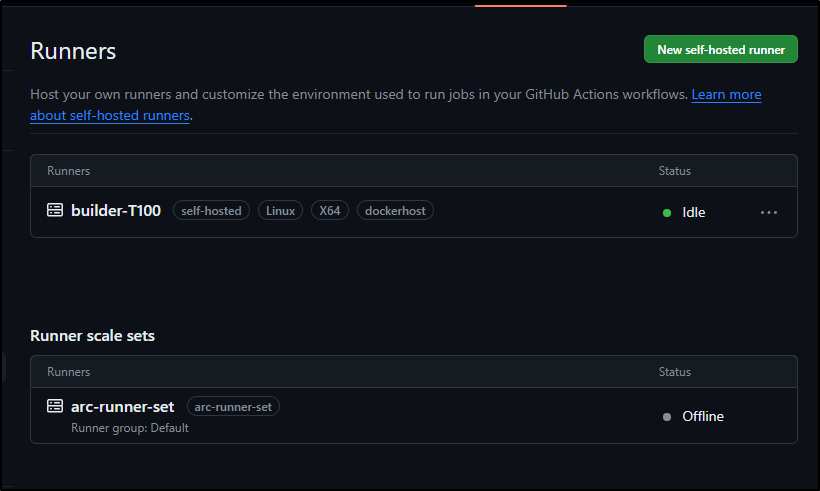
Unlike Summerwind, we won’t see running pods in our namespace, rather a “listener” in teh art-system namespace
$ kubectl get pods -n arc-systems
NAME READY STATUS RESTARTS AGE
arc-gha-rs-controller-7d5f8cbd9b-pcdv6 1/1 Running 0 11m
arc-runner-set-754b578d-listener 1/1 Running 0 102s
Which is now showing in a new section in Github runners
I’ll need to use a new “runs-on” so let’s create a test workflow in .github/workflows/testing-ghrunnerset.yml:
name: Actions Runner Controller Demo
on:
workflow_dispatch:
jobs:
Explore-GitHub-Actions:
# You need to use the INSTALLATION_NAME from the previous step
runs-on: arc-runner-set
steps:
- run: echo "🎉 This job uses runner scale set runners!"
- run: |
set -x
which az
which ruby
which tofu
Once pushed to main i could fire it off, but then it just sat there.
The logs on my Runnerset showed YET AGAIN we could not hit ‘api.github.com’
$ kubectl logs arc-runner-set-754b578d-listener -n arc-systems
2024-02-28T22:12:24Z INFO listener-app app initialized
2024-02-28T22:12:24Z INFO listener-app Starting listener
2024-02-28T22:12:24Z INFO listener-app refreshing token {"githubConfigUrl": "https://github.com/idjohnson/jekyll-blog"}
2024-02-28T22:12:24Z INFO listener-app getting runner registration token {"registrationTokenURL": "https://api.github.com/repos/idjohnson/jekyll-blog/actions/runners/registration-token"}
2024-02-28T22:12:54Z ERROR listener-app Retryable client error {"error": "Post \"https://api.github.com/repos/idjohnson/jekyll-blog/actions/runners/registration-token\": dial tcp: lookup api.github.com: i/o timeout", "method": "POST", "url": "https://api.github.com/repos/idjohnson/jekyll-blog/actions/runners/registration-token", "error": "request failed"}
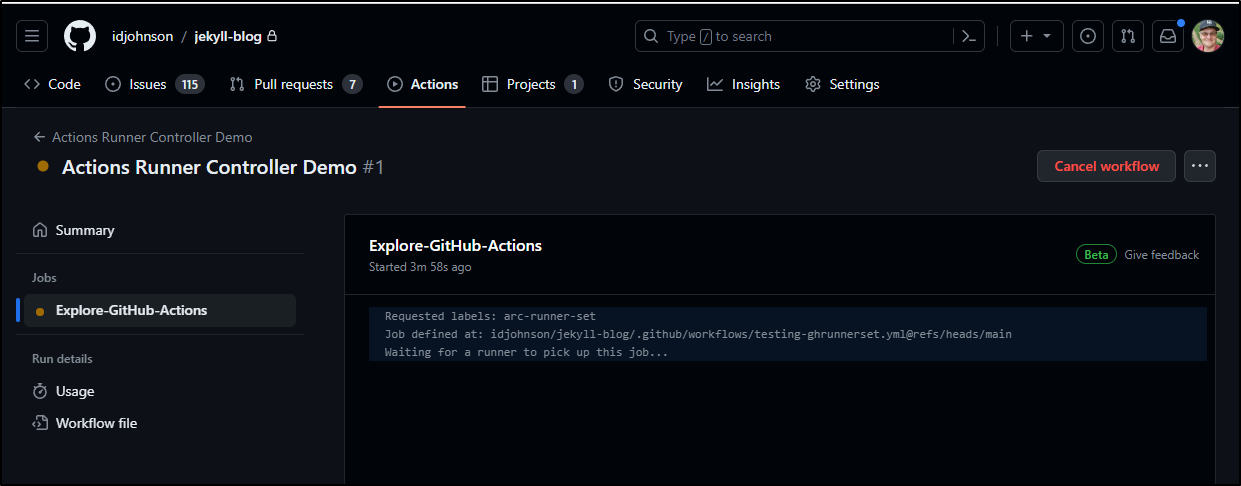
I tried to test with a dnsutils pod
$ kubectl run -it --rm --restart=Never --image=infoblox/dnstools:latest dnstools
If you don't see a command prompt, try pressing enter.
dnstools# host api.github.com
;; connection timed out; no servers could be reached
dnstools# host foxnews.com
;; connection timed out; no servers could be reached
dnstools#
Harbor
Harbor kept crashing. At one point it was my own doing for having dropped a NIC on the master node. But i could not get core and jobservice to stay up
Every 2.0s: kubectl get pods -l app=harbor DESKTOP-QADGF36: Wed Feb 28 13:40:52 2024
NAME READY STATUS RESTARTS AGE
harbor-registry2-exporter-59755fb475-trkqv 1/1 Running 0 129d
harbor-registry2-trivy-0 1/1 Running 0 129d
harbor-registry2-portal-5c45d99f69-nt6sj 1/1 Running 0 129d
harbor-registry2-registry-6fcf6fdf49-glbg2 2/2 Running 0 129d
harbor-registry2-redis-0 1/1 Running 1 (5h26m ago) 5h35m
harbor-registry2-core-5886799cd6-7npv2 1/1 Running 0 5h
harbor-registry2-jobservice-6bf7d6f5d6-wbvf6 0/1 Error 1 (39s ago) 85s
This caused the endless timeouts I alluded to earlier
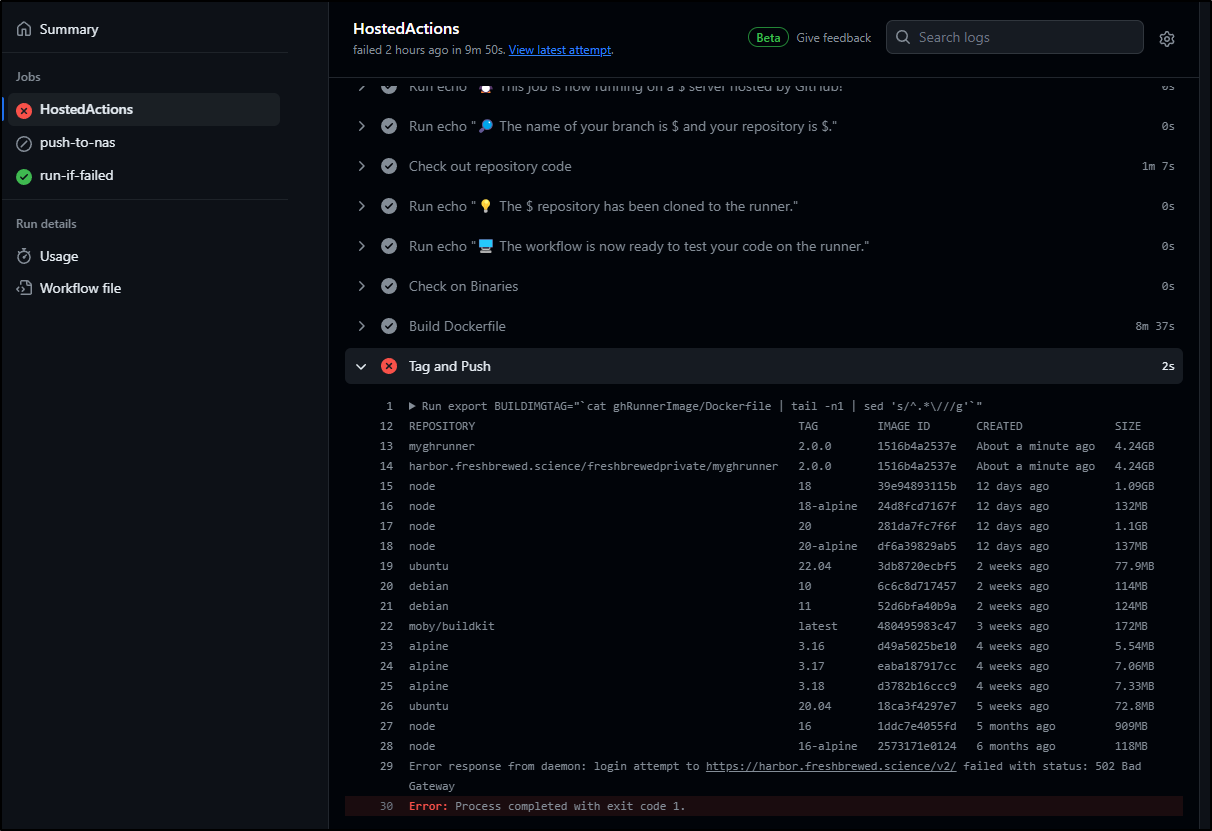
I set aside my existing values
$ helm get values harbor-registry2 -o yaml > harbor-registry2.yaml
$ kubectl get ingress harbor-registry2-ingress -o yaml > ingressbackup
To see a before and after, I looked at my tagged images of the currently running system
$ helm get values harbor-registry2 --all | grep 'tag: '
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
tag: v2.9.0
I then upgraded Harbor (as I did last time to the latest official version using my saved values
$ helm upgrade -f harbor-registry2.yaml harbor-registry2 harbor/harbor
Release "harbor-registry2" has been upgraded. Happy Helming!
NAME: harbor-registry2
LAST DEPLOYED: Wed Feb 28 13:44:09 2024
NAMESPACE: default
STATUS: deployed
REVISION: 4
TEST SUITE: None
NOTES:
Please wait for several minutes for Harbor deployment to complete.
Then you should be able to visit the Harbor portal at https://harbor.freshbrewed.science
For more details, please visit https://github.com/goharbor/harbor
Which eventually worked
kubectl get pods -l app=harbor DESKTOP-QADGF36: Wed Feb 28 13:47:31 2024
NAME READY STATUS RESTARTS AGE
harbor-registry2-portal-657748d5c7-4fhlc 1/1 Running 0 3m10s
harbor-registry2-exporter-6cdf6679b5-g7ntn 1/1 Running 0 3m13s
harbor-registry2-registry-64ff4b97f5-59qwg 2/2 Running 0 3m9s
harbor-registry2-trivy-0 1/1 Running 0 112s
harbor-registry2-redis-0 1/1 Running 0 2m1s
harbor-registry2-core-7568f658cd-xsl46 1/1 Running 0 3m13s
harbor-registry2-jobservice-768fd77d6-v8tk8 1/1 Running 3 (68s ago) 3m13s
And I could sanity check the image tags of the instances to see they were all upgraded
$ helm get values harbor-registry2 --all | grep 'tag: '
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
tag: v2.10.0
Linux Instance
First we make a folder, then download the latest runner
builder@builder-T100:~$ mkdir actions-runner && cd actions-runner
builder@builder-T100:~/actions-runner$ curl -o actions-runner-linux-x64-2.313.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.313.0/actions-runner-linux-x64-2.313.0.tar.gz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 179M 100 179M 0 0 55.4M 0 0:00:03 0:00:03 --:--:-- 65.7M
builder@builder-T100:~/actions-runner$ tar xzf ./actions-runner-linux-x64-2.313.0.tar.gz
Next, we configure (the token is provide in the settings page)
Then I went to launch the GH Runner
builder@builder-T100:~/actions-runner$ ./config.sh --url https://github.com/idjohnson/jekyll-blog --token ASDFASDFASDFASDAFASDASDAFAS
--------------------------------------------------------------------------------
| ____ _ _ _ _ _ _ _ _ |
| / ___(_) |_| | | |_ _| |__ / \ ___| |_(_) ___ _ __ ___ |
| | | _| | __| |_| | | | | '_ \ / _ \ / __| __| |/ _ \| '_ \/ __| |
| | |_| | | |_| _ | |_| | |_) | / ___ \ (__| |_| | (_) | | | \__ \ |
| \____|_|\__|_| |_|\__,_|_.__/ /_/ \_\___|\__|_|\___/|_| |_|___/ |
| |
| Self-hosted runner registration |
| |
--------------------------------------------------------------------------------
# Authentication
√ Connected to GitHub
# Runner Registration
Enter the name of the runner group to add this runner to: [press Enter for Default]
Enter the name of runner: [press Enter for builder-T100]
This runner will have the following labels: 'self-hosted', 'Linux', 'X64'
Enter any additional labels (ex. label-1,label-2): [press Enter to skip] dockerhost
√ Runner successfully added
√ Runner connection is good
# Runner settings
Enter name of work folder: [press Enter for _work]
√ Settings Saved.
I could then run (and make live) interactively
builder@builder-T100:~/actions-runner$ ./run.sh
√ Connected to GitHub
Current runner version: '2.313.0'
2024-02-28 13:18:13Z: Listening for Jobs
2024-02-28 13:18:16Z: Running job: build_deploy_test
2024-02-28 13:20:50Z: Job build_deploy_test completed with result: Failed
^CExiting...
Runner listener exit with 0 return code, stop the service, no retry needed.
Exiting runner...
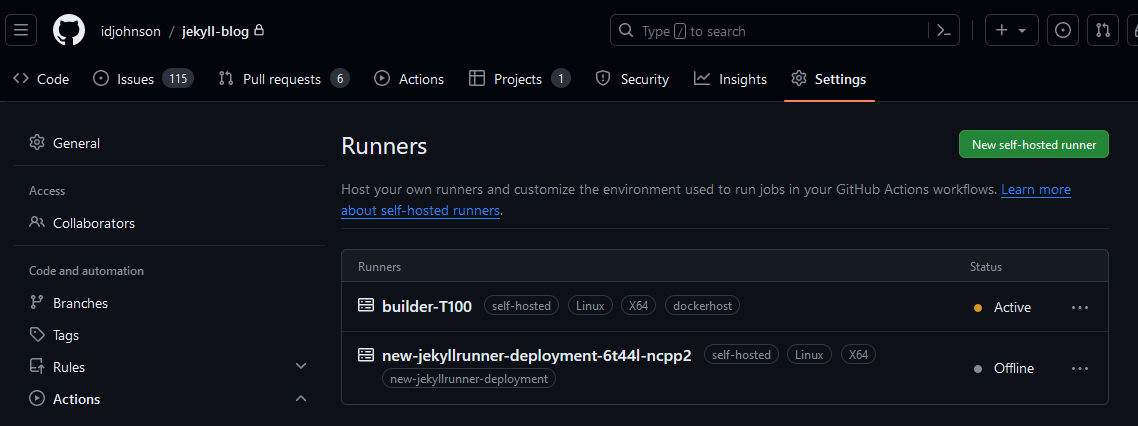
Once I took care of adding a multitude of libraries and missing packages, I could install this as a service (so I would not need to be logged in)
builder@builder-T100:~/actions-runner$ sudo ./svc.sh install
Creating launch runner in /etc/systemd/system/actions.runner.idjohnson-jekyll-blog.builder-T100.service
Run as user: builder
Run as uid: 1000
gid: 1000
Created symlink /etc/systemd/system/multi-user.target.wants/actions.runner.idjohnson-jekyll-blog.builder-T100.service → /etc/systemd/system/actions.runner.idjohnson-jekyll-blog.builder-T100.service.
builder@builder-T100:~/actions-runner$ sudo ./svc.sh start
/etc/systemd/system/actions.runner.idjohnson-jekyll-blog.builder-T100.service
● actions.runner.idjohnson-jekyll-blog.builder-T100.service - GitHub Actions Runner (idjohnson-jekyll-blog.builder-T100)
Loaded: loaded (/etc/systemd/system/actions.runner.idjohnson-jekyll-blog.builder-T100.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2024-02-28 07:37:28 CST; 13ms ago
Main PID: 573545 (runsvc.sh)
Tasks: 2 (limit: 9082)
Memory: 1.0M
CPU: 6ms
CGroup: /system.slice/actions.runner.idjohnson-jekyll-blog.builder-T100.service
├─573545 /bin/bash /home/builder/actions-runner/runsvc.sh
└─573549 ./externals/node16/bin/node ./bin/RunnerService.js
Feb 28 07:37:28 builder-T100 systemd[1]: Started GitHub Actions Runner (idjohnson-jekyll-blog.builder-T100).
Feb 28 07:37:28 builder-T100 runsvc.sh[573545]: .path=/home/builder/.nvm/versions/node/v18.16.0/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin
Feb 28 07:37:28 builder-T100 runsvc.sh[573549]: Starting Runner listener with startup type: service
Feb 28 07:37:28 builder-T100 runsvc.sh[573549]: Started listener process, pid: 573570
Feb 28 07:37:28 builder-T100 runsvc.sh[573549]: Started running service
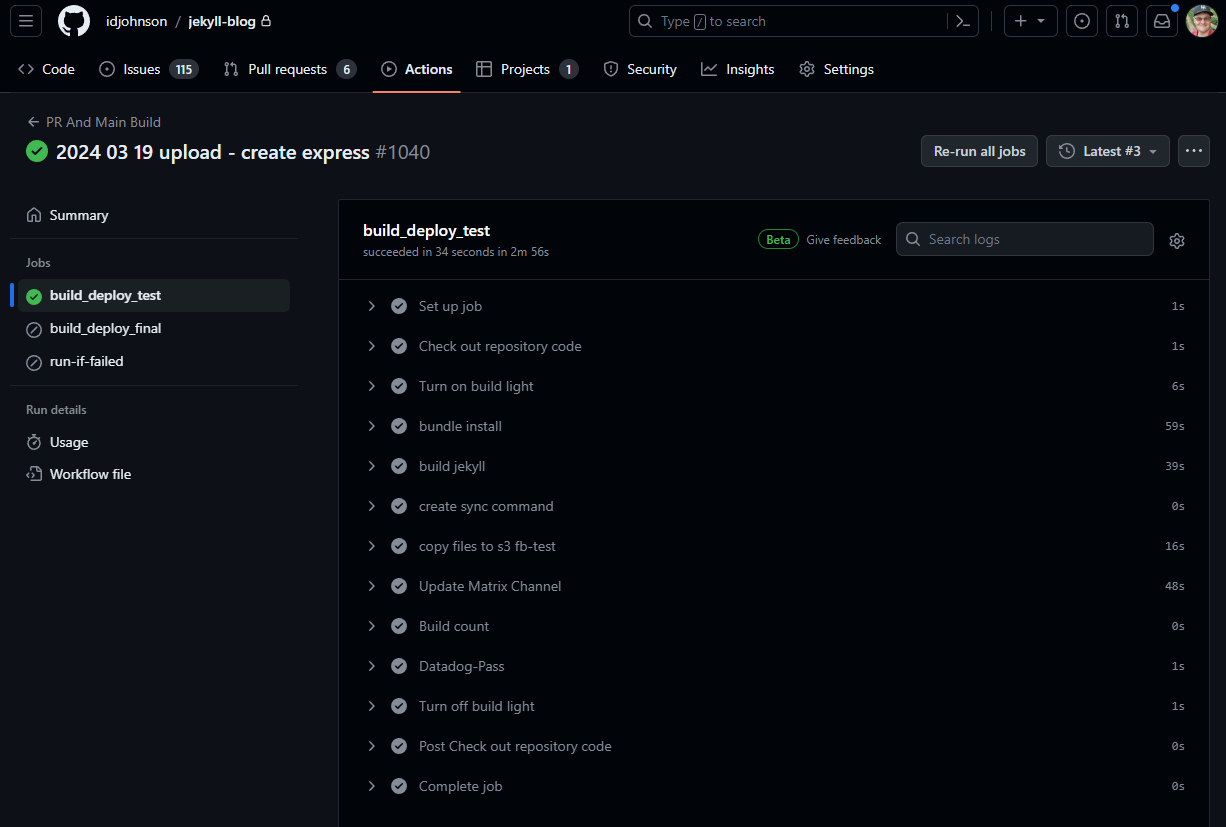
Things are still stuck…
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ kubectl get pods --all-namespaces | grep dns
kube-system coredns-d76bd69b-k57p5 1/1 Running 3 (285d ago) 580d
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ kubectl delete pod coredns-d76bd69b-k57p5 -n kube-system
pod "coredns-d76bd69b-k57p5" deleted
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ kubectl get pods --all-namespaces | grep dns
kube-system coredns-d76bd69b-7cmnh 0/1 ContainerCreating 0 5s
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ kubectl get pods --all-namespaces | grep dns
kube-system coredns-d76bd69b-7cmnh 0/1 ContainerCreating 0 7s
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ kubectl get pods --all-namespaces | grep dns
kube-system coredns-d76bd69b-7cmnh 1/1 Running 0 10s
Rebuild
This sucks. There is no going back now.
Now we rebuild.

Okay, so let’s first start by using the newer NAS for NFS mounts
The old was sassynassy at 192.168.1.129
The new is sirnasilot at 192.168.1.116.
I made the dirs:
mkdir -p /mnt/nfs/k3snfs
mkdir -p /mnt/psqlbackups
mkdir -p /mnt/nfs/snalPrimary01
Then added 3 lines for the mounts
builder@builder-HP-EliteBook-745-G5:~$ cat /etc/fstab
# /etc/fstab: static file system information.
#uilder@builder-HP-EliteBook-745-G5:~$
# Use 'blkid' to print the universally unique identifier for a
# device; this may be used with UUID= as a more robust way to name devices
# that works even if disks are added and removed. See fstab(5).
#
# <file system> <mount point> <type> <options> <dump> <pass>
# / was on /dev/nvme0n1p2 during installation
UUID=f5a264b7-35c9-4a37-a466-634771df4d94 / ext4 errors=remount-ro 0 1
# /boot/efi was on /dev/nvme0n1p1 during installation
UUID=9C7E-4200 /boot/efi vfat umask=0077 0 1
/swapfile none swap sw 0 0
192.168.1.129:/volume1/k3snfs /mnt/nfs/k3snfs nfs auto,nofail,noatime,nolock,intr,tcp,actimeo=1800 0 0
192.168.1.129:/volume1/postgres-prod-dbbackups /mnt/psqlbackups nfs auto,nofail,noatime,nolock,intr,tcp,actimeo=1800 0 0
192.168.1.116:/volume1/k3sPrimary01 /mnt/nfs/snalPrimary01 nfs auto,nofail,noatime,nolock,intr,tcp,actimeo=1800 0 0
I could test on any host by using sudo mount -a and seeing the files
hp@hp-HP-EliteBook-850-G2:~$ sudo mount -a
hp@hp-HP-EliteBook-850-G2:~$ ls -ltra /mnt/nfs/snalPrimary01/
total 4
drwxrwxrwx 1 root root 12 Mar 1 05:56 .
drwxr-xr-x 4 root root 4096 Mar 1 05:57 ..
hp@hp-HP-EliteBook-850-G2:~$ ls -ltra /mnt/nfs/k3snfs/
total 353780
drwxrwxrwx 2 root root 4096 Nov 16 2020 '#recycle'
drwxrwxrwx 2 1026 users 4096 Nov 16 2020 test
drwxrwxrwx 2 1024 users 4096 Nov 18 2020 default-beospvc-pvc-f36c2986-ab0b-4978-adb6-710d4698e170
drwxrwxrwx 2 1024 users 4096 Nov 19 2020 default-beospvc6-pvc-099fe2f3-2d63-4df5-ba65-4c7f3eba099e
drwxrwxrwx 2 1024 users 4096 Nov 19 2020 default-fedorawsiso-pvc-cad0ce95-9af3-4cb4-959d-d8b944de47ce
drwxrwxrwx 3 1024 users 4096 Dec 3 2020 default-data-redis-ha-1605552203-server-0-pvc-35be9319-4b0b-429e-82f6-6fbf3afab721
drwxrwxrwx 3 1024 users 4096 Dec 6 2020 default-data-redis-ha-1605552203-server-2-pvc-728cf90d-b725-44b9-8a2d-73ddae84abfa
drwxrwxrwx 3 1024 users 4096 Dec 17 2020 default-data-redis-ha-1605552203-server-1-pvc-17c79f00-ac73-454f-a664-e02de9158bd5
drwxrwxrwx 2 1024 users 4096 Dec 27 2020 default-redis-data-bitnami-harbor-redis-master-0-pvc-73a7e833-90fb-41ab-b42c-7a1e7fd5aad3
drwxrwxrwx 2 1024 users 4096 Jan 2 2021 default-mongo-release-mongodb-pvc-ecb4cc4f-153e-4eff-a5e7-5972b48e6f37
-rw-r--r-- 1 1024 users 362073000 Dec 6 2021 k3s-backup-master-20211206.tgz
drwxrwxrwx 2 1024 users 4096 Jul 8 2022 default-redis-data-redis-slave-1-pvc-3c569803-3275-443d-9b65-be028ce4481f
drwxrwxrwx 2 1024 users 4096 Jul 8 2022 default-redis-data-redis-master-0-pvc-bdf57f20-661c-4982-aebd-a1bb30b44830
drwxrwxrwx 2 1024 users 4096 Jul 8 2022 default-redis-data-redis-slave-0-pvc-651cdaa3-d321-45a3-adf3-62224c341fba
drwxrwxrwx 2 1024 users 4096 Oct 31 2022 backups
drwxrwxrwx 18 root root 4096 Oct 31 2022 .
drwxrwxrwx 2 1024 users 118784 Mar 1 02:09 postgres-backups
drwxr-xr-x 4 root root 4096 Mar 1 05:57 ..
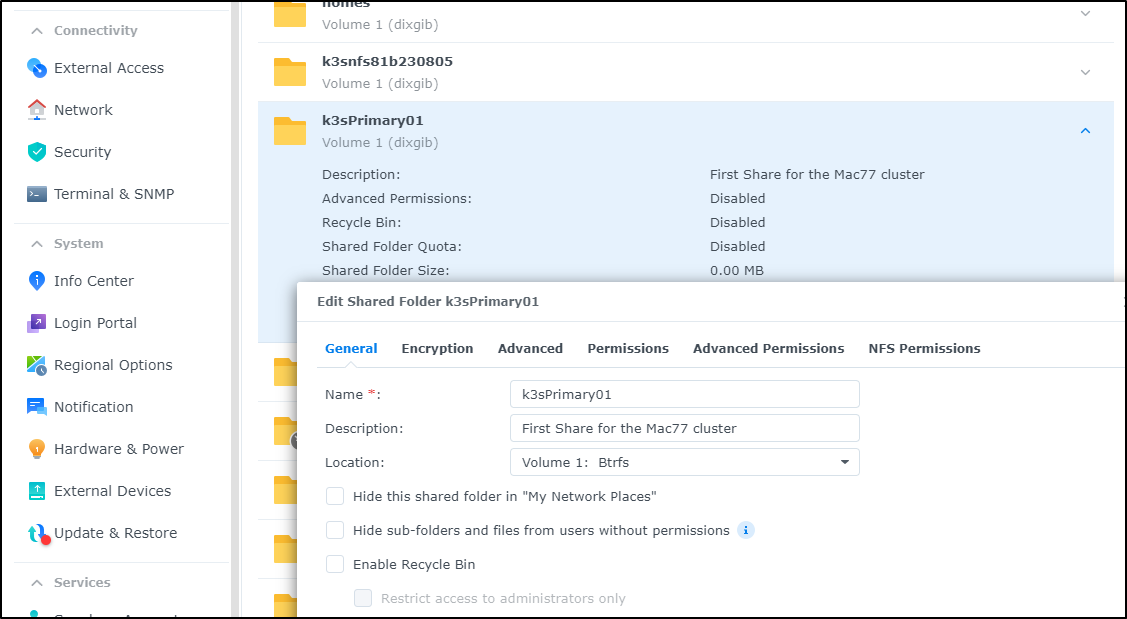
The new mount uses Btrfs which should be more resiliant than the old ext4
For this release, we’ll use the (at present) latest build of 1.26.14: https://github.com/k3s-io/k3s/releases/tag/v1.26.14%2Bk3s1
v1.26.14+k3s1 or v1.26.14%2Bk3s1
Perhaps using
curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION="v1.26.14%2Bk3s1" K3S_KUBECONFIG_MODE="644" INSTALL_K3S_EXEC=" --no-deploy traefik --tls-san 73.242.50.46" sh -
My first try failed
builder@builder-HP-EliteBook-745-G5:~$ curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION="v1.26.14%2Bk3s1" K3S_KUBECONFIG_MODE="644" INSTALL_K3S_EXEC=" --no-deploy traefik --tls-san 73.242.50.46" sh -
[INFO] Using v1.26.14%2Bk3s1 as release
[INFO] Downloading hash https://github.com/k3s-io/k3s/releases/download/v1.26.14%2Bk3s1/sha256sum-amd64.txt
[INFO] Downloading binary https://github.com/k3s-io/k3s/releases/download/v1.26.14%2Bk3s1/k3s
[INFO] Verifying binary download
[INFO] Installing k3s to /usr/local/bin/k3s
[INFO] Skipping installation of SELinux RPM
[INFO] Skipping /usr/local/bin/kubectl symlink to k3s, command exists in PATH at /usr/bin/kubectl
[INFO] Skipping /usr/local/bin/crictl symlink to k3s, command exists in PATH at /usr/bin/crictl
[INFO] Skipping /usr/local/bin/ctr symlink to k3s, command exists in PATH at /usr/bin/ctr
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s.service
[INFO] systemd: Enabling k3s unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service.
[INFO] systemd: Starting k3s
Job for k3s.service failed because the control process exited with error code.
See "systemctl status k3s.service" and "journalctl -xeu k3s.service" for details.
builder@builder-HP-EliteBook-745-G5:~$ systemctl status k3s.service
● k3s.service - Lightweight Kubernetes
Loaded: loaded (/etc/systemd/system/k3s.service; enabled; vendor preset: enabled)
Active: activating (auto-restart) (Result: exit-code) since Fri 2024-03-01 06:16:33 CST; 611ms ago
Docs: https://k3s.io
Process: 47993 ExecStartPre=/bin/sh -xc ! /usr/bin/systemctl is-enabled --quiet nm-cloud-setup.service 2>/dev/null (code=exited, status=0/SUCCESS)
Process: 47995 ExecStartPre=/sbin/modprobe br_netfilter (code=exited, status=0/SUCCESS)
Process: 47996 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS)
Process: 47997 ExecStart=/usr/local/bin/k3s server --no-deploy traefik --tls-san 73.242.50.46 (code=exited, status=1/FAILURE)
Main PID: 47997 (code=exited, status=1/FAILURE)
CPU: 24ms
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --kube-proxy-arg value (agent/flags) Customized flag for kube-proxy process
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --protect-kernel-defaults (agent/node) Kernel tuning behavior. If set, error >
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --secrets-encryption Enable secret encryption at rest
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --enable-pprof (experimental) Enable pprof endpoint on supervisor >
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --rootless (experimental) Run rootless
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --prefer-bundled-bin (experimental) Prefer bundled userspace binaries ov>
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --selinux (agent/node) Enable SELinux in containerd [$K3S_SEL>
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: --lb-server-port value (agent/node) Local port for supervisor client load->
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]:
Mar 01 06:16:33 builder-HP-EliteBook-745-G5 k3s[47997]: time="2024-03-01T06:16:33-06:00" level=fatal msg="flag provided but not defined: -no-deploy"
The error is that last line:
msg="flag provided but not defined: -no-deploy"
Seems the newer way is
curl -sfL https://get.k3s.io | INSTALL_K3S_EXEC="server" sh -s - --disable-traefik
$ curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION="v1.26.14%2Bk3s1" K3S_KUBECONFIG_MODE="644" INSTALL_K3S_EXEC="--
disable-traefik --tls-san 73.242.50.46" sh -
[INFO] Using v1.26.14%2Bk3s1 as release
[INFO] Downloading hash https://github.com/k3s-io/k3s/releases/download/v1.26.14%2Bk3s1/sha256sum-amd64.txt
[INFO] Skipping binary downloaded, installed k3s matches hash
[INFO] Skipping installation of SELinux RPM
[INFO] Skipping /usr/local/bin/kubectl symlink to k3s, command exists in PATH at /usr/bin/kubectl
[INFO] Skipping /usr/local/bin/crictl symlink to k3s, command exists in PATH at /usr/bin/crictl
[INFO] Skipping /usr/local/bin/ctr symlink to k3s, command exists in PATH at /usr/bin/ctr
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s.service
[INFO] systemd: Enabling k3s unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service.
[INFO] No change detected so skipping service start
The new “word” is just “disable”, not “no-deploy”
$ INSTALL_K3S_VERSION="v1.26.14%2Bk3s1" K3S_KUBECONFIG_MODE="644" INSTALL_K3S_EXEC="server" ./k3s.sh --disable traefi
k --tls-san 73.242.50.46
[INFO] Using v1.26.14%2Bk3s1 as release
[INFO] Downloading hash https://github.com/k3s-io/k3s/releases/download/v1.26.14%2Bk3s1/sha256sum-amd64.txt
[INFO] Skipping binary downloaded, installed k3s matches hash
[INFO] Skipping installation of SELinux RPM
[INFO] Skipping /usr/local/bin/kubectl symlink to k3s, command exists in PATH at /usr/bin/kubectl
[INFO] Skipping /usr/local/bin/crictl symlink to k3s, command exists in PATH at /usr/bin/crictl
[INFO] Skipping /usr/local/bin/ctr symlink to k3s, command exists in PATH at /usr/bin/ctr
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s.service
[INFO] systemd: Enabling k3s unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service.
[INFO] systemd: Starting k3s
Still trying
builder@builder-HP-EliteBook-745-G5:~$ curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION="v1.26.14%2Bk3s1" K3S_KUBECONFIG_MODE="644" INSTALL_K3S_EXEC="--disable traefik
--tls-san 73.242.50.46" sh -
[INFO] Using v1.26.14%2Bk3s1 as release
[INFO] Downloading hash https://github.com/k3s-io/k3s/releases/download/v1.26.14%2Bk3s1/sha256sum-amd64.txt
[INFO] Downloading binary https://github.com/k3s-io/k3s/releases/download/v1.26.14%2Bk3s1/k3s
[INFO] Verifying binary download
[INFO] Installing k3s to /usr/local/bin/k3s
[INFO] Skipping installation of SELinux RPM
[INFO] Skipping /usr/local/bin/kubectl symlink to k3s, command exists in PATH at /usr/bin/kubectl
[INFO] Skipping /usr/local/bin/crictl symlink to k3s, command exists in PATH at /usr/bin/crictl
[INFO] Skipping /usr/local/bin/ctr symlink to k3s, command exists in PATH at /usr/bin/ctr
[INFO] Creating killall script /usr/local/bin/k3s-killall.sh
[INFO] Creating uninstall script /usr/local/bin/k3s-uninstall.sh
[INFO] env: Creating environment file /etc/systemd/system/k3s.service.env
[INFO] systemd: Creating service file /etc/systemd/system/k3s.service
[INFO] systemd: Enabling k3s unit
Created symlink /etc/systemd/system/multi-user.target.wants/k3s.service → /etc/systemd/system/k3s.service.
[INFO] systemd: Starting k3s
builder@builder-HP-EliteBook-745-G5:~$ systemctl status k3s.service
● k3s.service - Lightweight Kubernetes
Loaded: loaded (/etc/systemd/system/k3s.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2024-03-01 06:36:42 CST; 7s ago
Docs: https://k3s.io
Process: 2863 ExecStartPre=/bin/sh -xc ! /usr/bin/systemctl is-enabled --quiet nm-cloud-setup.service 2>/dev/null (code=exited, status=0/SUCCESS)
Process: 2865 ExecStartPre=/sbin/modprobe br_netfilter (code=exited, status=0/SUCCESS)
Process: 2866 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS)
Main PID: 2867 (k3s-server)
Tasks: 30
Memory: 553.0M
CPU: 19.107s
CGroup: /system.slice/k3s.service
├─2867 "/usr/local/bin/k3s server" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" ""
└─2894 "containerd " "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" "" >
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.395407 2867 configmap_cafile_content.go:202] "Starting controller" name="client-ca::kube-system:>
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.395410 2867 configmap_cafile_content.go:202] "Starting controller" name="client-ca::kube-system:>
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.395489 2867 secure_serving.go:213] Serving securely on 127.0.0.1:10259
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.395494 2867 shared_informer.go:270] Waiting for caches to sync for client-ca::kube-system::exten>
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.395454 2867 shared_informer.go:270] Waiting for caches to sync for client-ca::kube-system::exten>
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.395569 2867 tlsconfig.go:240] "Starting DynamicServingCertificateController"
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: time="2024-03-01T06:36:49-06:00" level=info msg="Handling backend connection request [builder-hp-elitebook-745-g5]"
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.495856 2867 shared_informer.go:277] Caches are synced for RequestHeaderAuthRequestController
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.496011 2867 shared_informer.go:277] Caches are synced for client-ca::kube-system::extension-apis>
Mar 01 06:36:49 builder-HP-EliteBook-745-G5 k3s[2867]: I0301 06:36:49.496083 2867 shared_informer.go:277] Caches are synced for client-ca::kube-system::exte
I had a bad prior install that messed up the kubeconfig, i fixed that and could see node1
builder@builder-HP-EliteBook-745-G5:~$ cp ~/.kube/config ~/.kube/config-bak
builder@builder-HP-EliteBook-745-G5:~$ cp /etc/rancher/k3s/k3s.yaml ~/.kube/config
builder@builder-HP-EliteBook-745-G5:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
builder-hp-elitebook-745-g5 Ready control-plane,master 98s v1.26.14+k3s1
Adwerx AWX
I managed to pull my values file before it crashed again, enough to get the right Ingress annotations and password.
isaac@isaac-MacBookAir:~$ helm get values -n adwerx adwerxawx
WARNING: Kubernetes configuration file is group-readable. This is insecure. Location: /home/isaac/.kube/config
WARNING: Kubernetes configuration file is world-readable. This is insecure. Location: /home/isaac/.kube/config
USER-SUPPLIED VALUES:
affinity: null
default_admin_password: null
default_admin_user: null
defaultAdminExistingSecret: null
defaultAdminPassword: xxxxxxxxxxxxxxxx
defaultAdminUser: admin
extraConfiguration: '# INSIGHTS_URL_BASE = "https://example.org"'
extraVolumes: []
fullnameOverride: ""
image:
pullPolicy: IfNotPresent
repository: ansible/awx
tag: 17.1.0
ingress:
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
ingress.kubernetes.io/proxy-body-size: "0"
ingress.kubernetes.io/ssl-redirect: "true"
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/proxy-body-size: "0"
nginx.ingress.kubernetes.io/proxy-read-timeout: "600"
nginx.ingress.kubernetes.io/proxy-send-timeout: "600"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.org/client-max-body-size: "0"
nginx.org/proxy-connect-timeout: "600"
nginx.org/proxy-read-timeout: "600"
defaultBackend: true
enabled: true
hosts:
- host: awx.freshbrewed.science
paths:
- /
tls:
- hosts:
- awx.freshbrewed.science
secretName: awx-tls
...
It uses this Adwerx AWX chart
I just did an add and update
$ helm repo add adwerx https://adwerx.github.io/charts
"adwerx" already exists with the same configuration, skipping
$ helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "adwerx" chart repository
...Successfully got an update from the "portainer" chart repository
...Successfully got an update from the "ngrok" chart repository
...Successfully got an update from the "zabbix-community" chart repository
...Successfully got an update from the "novum-rgi-helm" chart repository
...Successfully got an update from the "btungut" chart repository
...Successfully got an update from the "actions-runner-controller" chart repository
...Successfully got an update from the "kuma" chart repository
...Successfully got an update from the "rhcharts" chart repository
...Successfully got an update from the "akomljen-charts" chart repository
...Successfully got an update from the "kubecost" chart repository
...Successfully got an update from the "openproject" chart repository
...Successfully got an update from the "castai-helm" chart repository
...Successfully got an update from the "lifen-charts" chart repository
...Successfully got an update from the "elastic" chart repository
...Successfully got an update from the "datadog" chart repository
...Successfully got an update from the "nginx-stable" chart repository
...Successfully got an update from the "jetstack" chart repository
...Successfully got an update from the "signoz" chart repository
...Successfully got an update from the "uptime-kuma" chart repository
...Successfully got an update from the "incubator" chart repository
...Successfully got an update from the "grafana" chart repository
...Successfully got an update from the "gitlab" chart repository
...Unable to get an update from the "freshbrewed" chart repository (https://harbor.freshbrewed.science/chartrepo/library):
failed to fetch https://harbor.freshbrewed.science/chartrepo/library/index.yaml : 404 Not Found
...Unable to get an update from the "myharbor" chart repository (https://harbor.freshbrewed.science/chartrepo/library):
failed to fetch https://harbor.freshbrewed.science/chartrepo/library/index.yaml : 404 Not Found
...Successfully got an update from the "nfs" chart repository
...Successfully got an update from the "kube-state-metrics" chart repository
...Successfully got an update from the "opencost-charts" chart repository
...Successfully got an update from the "dapr" chart repository
...Successfully got an update from the "jfelten" chart repository
...Successfully got an update from the "opencost" chart repository
...Successfully got an update from the "confluentinc" chart repository
...Successfully got an update from the "azure-samples" chart repository
...Successfully got an update from the "ingress-nginx" chart repository
...Successfully got an update from the "openfunction" chart repository
...Successfully got an update from the "sonarqube" chart repository
...Successfully got an update from the "longhorn" chart repository
...Successfully got an update from the "spacelift" chart repository
...Successfully got an update from the "rook-release" chart repository
...Successfully got an update from the "hashicorp" chart repository
...Successfully got an update from the "harbor" chart repository
...Successfully got an update from the "kiwigrid" chart repository
...Successfully got an update from the "openzipkin" chart repository
...Successfully got an update from the "gitea-charts" chart repository
...Successfully got an update from the "sumologic" chart repository
...Successfully got an update from the "crossplane-stable" chart repository
...Successfully got an update from the "ananace-charts" chart repository
...Successfully got an update from the "open-telemetry" chart repository
...Successfully got an update from the "makeplane" chart repository
...Unable to get an update from the "epsagon" chart repository (https://helm.epsagon.com):
Get "https://helm.epsagon.com/index.yaml": dial tcp: lookup helm.epsagon.com on 172.22.64.1:53: server misbehaving
...Successfully got an update from the "argo-cd" chart repository
...Successfully got an update from the "rancher-latest" chart repository
...Successfully got an update from the "newrelic" chart repository
...Successfully got an update from the "prometheus-community" chart repository
...Successfully got an update from the "bitnami" chart repository
Update Complete. ⎈Happy Helming!⎈
Then install
$ helm install -n adwerxawx --create-namespace adwerxawx -f ./adwerx.awx.values adwerx/awx
NAME: adwerxawx
LAST DEPLOYED: Sun Mar 3 16:02:10 2024
NAMESPACE: adwerxawx
STATUS: deployed
REVISION: 1
To rebuild, I just followed our guide from August 2022.
I never wrote how to make an Org using a Kubernetes Job there, so here is that example:
$ cat awx_createorg.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: awxcreateorg2
namespace: adwerxawx
spec:
backoffLimit: 4
template:
spec:
containers:
- name: test
image: alpine
envFrom:
- secretRef:
name: adwerxawx
command:
- bin/sh
- -c
- |
apk --no-cache add curl
apk --no-cache add jq
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/organizations/ --data "{ \"name\": \"onprem\", \"description\": \"on prem hosts\", \"max_hosts\": 0, \"custom_virtualenv\": null }"
curl --silent --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X GET -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/organizations/ | jq '.results[] | select(.name=="onprem") | .id' > ./ORGID
cat ./ORGID
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X GET -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/organizations/ | jq
restartPolicy: Never
Then we apply
$ kubectl apply -f awx_createorg.yaml -n adwerxawx
job.batch/awxcreateorg2 created
And results
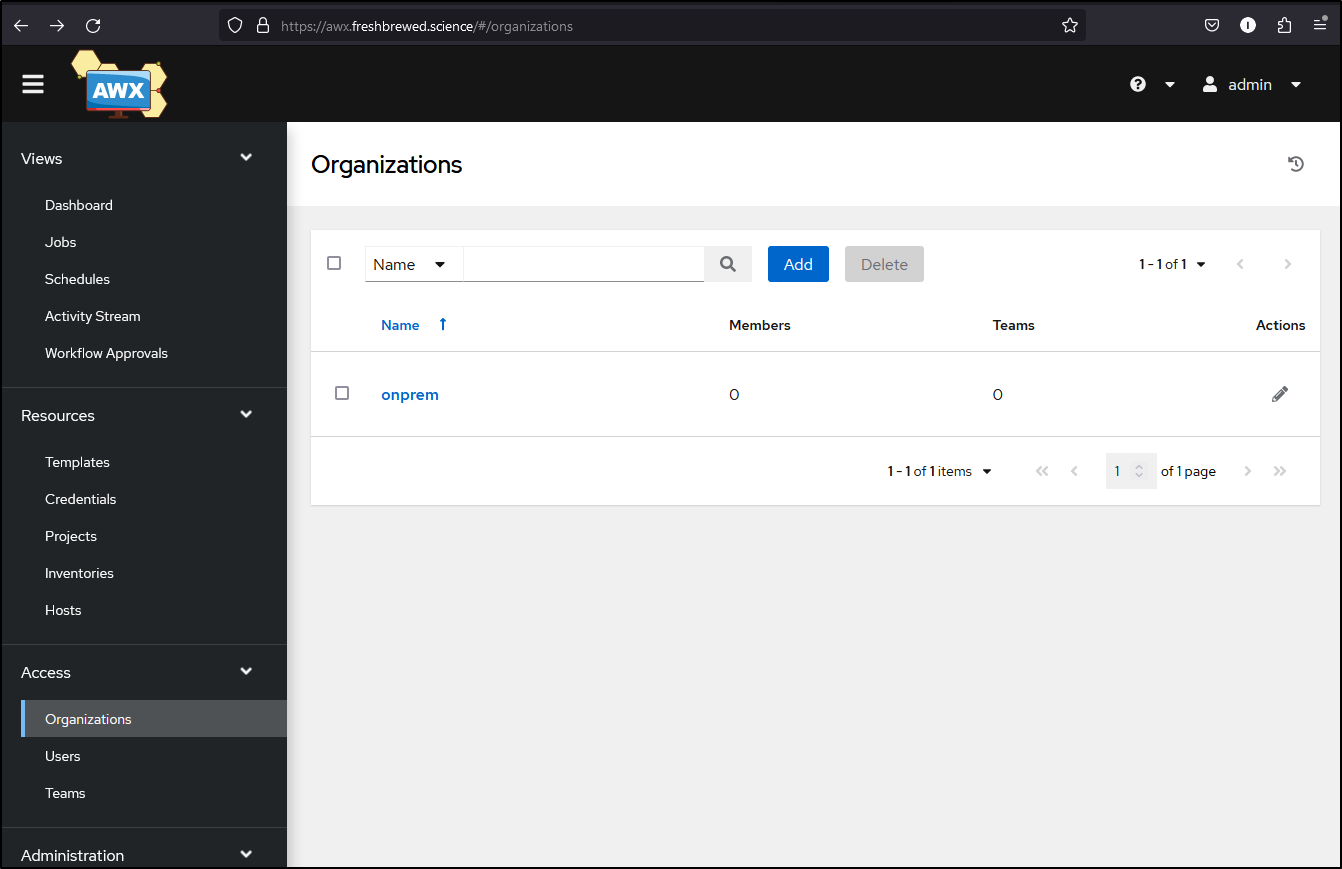
I need a credential type to create the GH credential - namely “SCM” which is usually 2
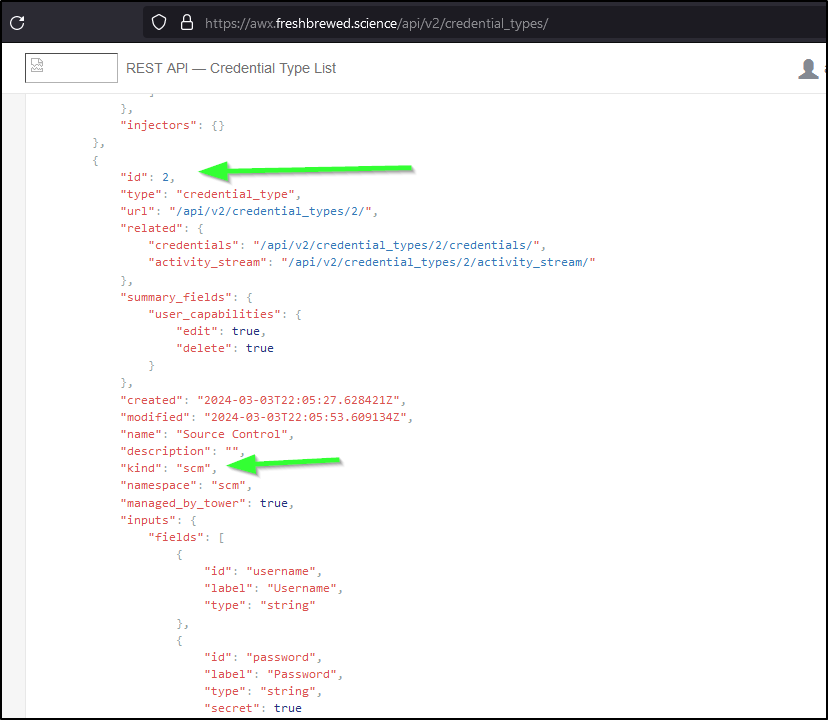
It also works for a local curl
$ curl --silent -X GET -H "Content-Type: application/json" --user admin:asdfsadfasdfasdf https://awx.freshbr
ewed.science/api/v2/credential_types/ | jq '.results[] | select(.kind=="scm") | .id'
2
I’ll apply the other AWX jobs and when done
$ kubectl get jobs -n adwerxawx
NAME COMPLETIONS DURATION AGE
awxcreateorg1 1/1 8s 32m
awxcreateorg2 1/1 8s 24m
awxcreatescm1 1/1 8s 35s
awxcreateproj1 1/1 9s 17s
I’ll then have Orgs, a working SCM and lastly a setup project
Creating the Inventories and hosts was a breeze
$ cat awx_createk3shosts.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: awxcreatek8hosts5
namespace: adwerxawx
spec:
backoffLimit: 4
template:
spec:
containers:
- name: test
image: alpine
envFrom:
- secretRef:
name: adwerxawx
command:
- bin/sh
- -c
- |
apk --no-cache add curl
apk --no-cache add jq
set -x
# Org ID for final curl
curl --silent --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X GET -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/organizations/ | jq '.results[] | select(.name=="onprem") | .id' > ./ORGID
export ORGID=`cat ./ORGID | tr -d '\n'`
# Create Kubernetes Nodes Inv
# curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/inventories/ --data "{\"name\": \"Kubernetes Nodes\",\"description\": \"Kubernetes On Prem Nodes\", \"organization\": $ORGID, \"variables\": \"---\" }"
# Inv ID for final curl
curl --silent --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X GET -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/inventories/ | jq '.results[] | select(.name=="Kubernetes Nodes") | .id' > ./INVID
export INVID=`cat ./INVID | tr -d '\n'`
# Anna MBAir
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/hosts/ --data "{ \"name\": \"AnnaMacbook\", \"description\": \"Annas Macbook Air (primary)\", \"inventory\": $INVID, \"enabled\": true, \"variables\": \"---\nansible_host: 192.168.1.81\nansible_connection: ssh\"}"
# builder-MacBookPro2
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/hosts/ --data "{ \"name\": \"builder-MacBookPro2\", \"description\": \"builder-MacBookPro2 (worker)\", \"inventory\": $INVID, \"enabled\": true, \"variables\": \"---\nansible_host: 192.168.1.159\nansible_connection: ssh\"}"
# isaac-macbookpro
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/hosts/ --data "{ \"name\": \"isaac-macbookpro\", \"description\": \"isaac-macbookpro (worker)\", \"inventory\": $INVID, \"enabled\": true, \"variables\": \"---\nansible_host: 192.168.1.74\nansible_connection: ssh\"}"
# builder-hp-elitebook-745-g5
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/hosts/ --data "{ \"name\": \"builder-hp-elitebook-745-g5\", \"description\": \"builder-hp-elitebook-745-g5 (primary)\", \"inventory\": $INVID, \"enabled\": true, \"variables\": \"---\nansible_host: 192.168.1.33\nansible_connection: ssh\"}"
# builder-hp-elitebook-850-g1
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/hosts/ --data "{ \"name\": \"builder-hp-elitebook-850-g1\", \"description\": \"builder-hp-elitebook-850-g1 (worker)\", \"inventory\": $INVID, \"enabled\": true, \"variables\": \"---\nansible_host: 192.168.1.36\nansible_connection: ssh\"}"
# hp-hp-elitebook-850-g2
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/hosts/ --data "{ \"name\": \"hp-hp-elitebook-850-g2\", \"description\": \"hp-hp-elitebook-850-g2 (worker) - bad battery\", \"inventory\": $INVID, \"enabled\": true, \"variables\": \"---\nansible_host: 192.168.1.57\nansible_connection: ssh\"}"
# builder-HP-EliteBook-850-G2
curl --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/hosts/ --data "{ \"name\": \"builder-HP-EliteBook-850-G2\", \"description\": \"builder-HP-EliteBook-850-G2 (worker) - bad fan\", \"inventory\": $INVID, \"enabled\": true, \"variables\": \"---\nansible_host: 192.168.1.215\nansible_connection: ssh\"}"
restartPolicy: Never
After applying:
$ kubectl apply -n adwerxawx -f ./awx_createk3shosts.yaml
job.batch/awxcreatek8hosts5 created
I created the Credentials I would need
$ cat awx_createhostpw.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: awxcreatehostpw2
namespace: adwerxawx
spec:
backoffLimit: 4
template:
spec:
containers:
- name: test
image: alpine
envFrom:
- secretRef:
name: adwerxawx
command:
- bin/sh
- -c
- |
apk --no-cache add curl
apk --no-cache add jq
# Org ID for final curl
curl --silent --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X GET -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/organizations/ | jq '.results[] | select(.name=="onprem") | .id' > ./ORGID
export ORGID=`cat ./ORGID | tr -d '\n'`
# Get Machine ID (usually 1)
curl --silent -X GET -H "Content-Type: application/json" --user admin:Redliub\$1 http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/credential_types/ | jq '.results[] | select(.name=="Machine") | .id' > ./HOSTTYPEID
export HOSTTYPEID=`cat ./HOSTTYPEID | tr -d '\n'`
# Standard Builder User
curl --silent --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/credentials/ --data "{\"credential_type\": $HOSTTYPEID, \"inputs\": { \"username\": \"builder\", \"password\": \"xxxpasswordxxx\" }, \"name\": \"Builder Credential\", \"organization\": $ORGID}"
# hp builder
curl --silent --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/credentials/ --data "{\"credential_type\": $HOSTTYPEID, \"inputs\": { \"username\": \"hp\", \"password\": \"xxxpasswordxxx\" }, \"name\": \"HP Credential\", \"organization\": $ORGID}"
# Isaac user
curl --silent --user $AWX_ADMIN_USER:$AWX_ADMIN_PASSWORD -X POST -H "Content-Type: application/json" http://$ADWERXAWX_SERVICE_HOST:$ADWERXAWX_SERVICE_PORT_HTTP/api/v2/credentials/ --data "{\"credential_type\": $HOSTTYPEID, \"inputs\": { \"username\": \"isaac\", \"password\": \"xxxpasswordxxx\" }, \"name\": \"Isaac Credential\", \"organization\": $ORGID}"
restartPolicy: Never
THen tested using a shell pwd command
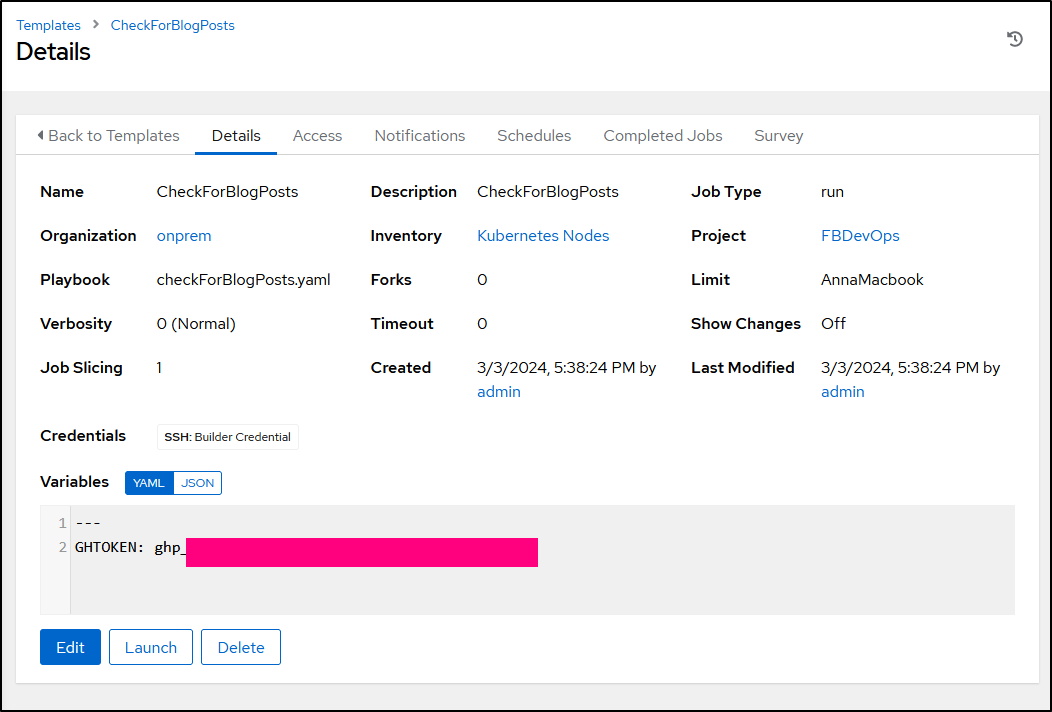
I recreated the Nightly Blog Post check
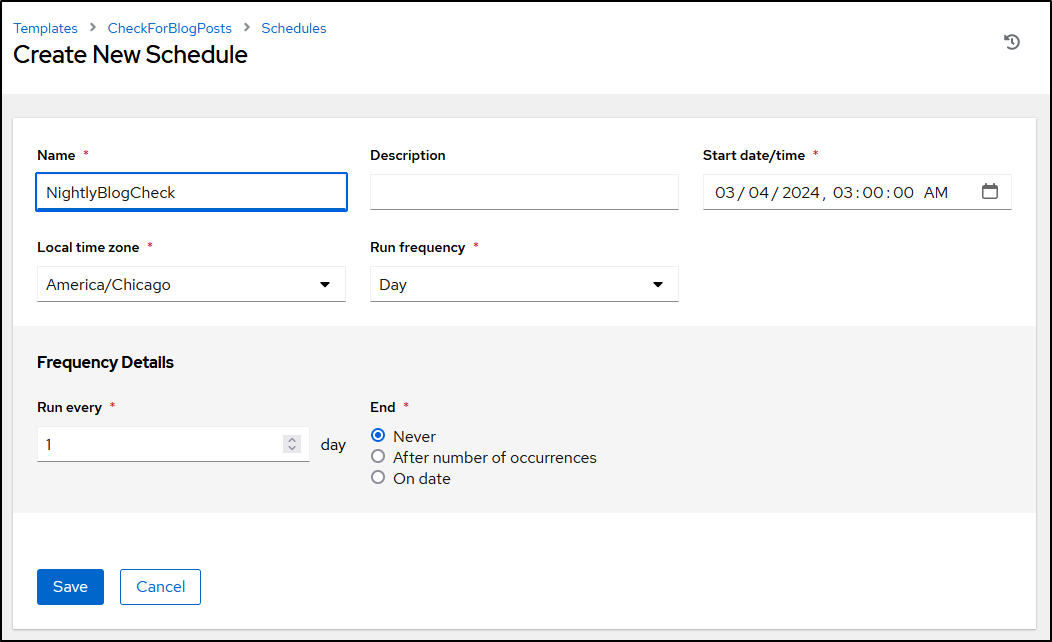
Then set a schedule
Forgejo
I was hoping it might be true - I had setup Forgejo using a MySQL backend hosted on the HA NAS.
The values files were still local, so launching it again was as easy as a helm install
$ helm upgrade --install -n forgejo --create-namespace forgejo -f /home/builder/forgego.values oci://codeberg.org/forgejo-contrib/forgejo
Release "forgejo" does not exist. Installing it now.
Pulled: codeberg.org/forgejo-contrib/forgejo:4.0.1
Digest: sha256:a1a403f7fa30ff1353a50a86aa7232faa4a5a219bc2fba4cae1c69c878c4f7af
NAME: forgejo
LAST DEPLOYED: Sun Mar 3 18:23:53 2024
NAMESPACE: forgejo
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:
echo "Visit http://127.0.0.1:3000 to use your application"
kubectl --namespace forgejo port-forward svc/forgejo-http 3000:3000
And the ingress was noted in the original blog article
So I just recreated that
$ cat forgejo.ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
cert-manager.io/cluster-issuer: letsencrypt-prod
ingress.kubernetes.io/proxy-body-size: "0"
ingress.kubernetes.io/ssl-redirect: "true"
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/proxy-body-size: "0"
nginx.ingress.kubernetes.io/proxy-read-timeout: "600"
nginx.ingress.kubernetes.io/proxy-send-timeout: "600"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
nginx.org/client-max-body-size: "0"
nginx.org/proxy-connect-timeout: "600"
nginx.org/proxy-read-timeout: "600"
generation: 1
labels:
app: forgejo
app.kubernetes.io/instance: forgejo
app.kubernetes.io/name: forgejo
name: forgejo
spec:
rules:
- host: forgejo.freshbrewed.science
http:
paths:
- backend:
service:
name: forgejo-http
port:
number: 3000
path: /
pathType: ImplementationSpecific
tls:
- hosts:
- forgejo.freshbrewed.science
secretName: forgejo-tls
$ kubectl apply -f forgejo.ingress.yaml -n forgejo
ingress.networking.k8s.io/forgejo created
While Forgejo did come up, the repos behind it were missing. It seems the data for the repos were in PVCs now lost.
Weeks later
I actually took a break from blogging for a while.
To get Github runners working again, I used my dockerhost
1164 mkdir githubrunner
1165 cd githubrunner/
1166 ls
1167 cd ..
1168 mkdir actions-runner && cd actions-runner
1169 curl -o actions-runner-linux-x64-2.313.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.313.0/actions-runner-linux-x64-2.313.0.tar.gz
1170 ./config.sh --url https://github.com/idjohnson/jekyll-blog --token asdfasdfasdfasdfasdfadsf
1171 ./run.sh
1172 ls
1173 cat svc.sh
1174 ls
1175 sudo apt update && sudo apt install -y ca-certificates curl apt-transport-https lsb-release gnupg
1176 umask 0002 && echo "deb [arch=amd64] https://packages.microsoft.com/repos/azure-cli/ focal main" | sudo tee /etc/apt/sources.list.d/azure-cli.list
1177 sudo apt update -y && umask 0002 && sudo apt install -y azure-cli awscli ruby-full
1178 curl -fsSL https://get.pulumi.com | sh
1179 eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" && brew install go@1.19
1180 eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)" && brew install opentofu
1181 sudo cp /home/linuxbrew/.linuxbrew/bin/tofu /usr/local/bin/
1182 sudo chmod 777 /var/lib/gems/*
1183 sudo chown runner /var/lib/gems/*
1184 sudo apt update -y && umask 0002 && sudo apt install -y sshpass expect
1185 umask 0002 && gem install bundler -v 2.4.22
1186 umask 0002 && sudo gem install bundler -v 2.4.22
1187 sudo gem install jekyll --version="~> 4.2.0"
1188 history
1189 sudo apt update && sudo apt install -y gnupg git build-essential
1190 sudo ./svc.sh install
1191 sudo ./svc.sh start
And later a missing python lib was needed
1339 pip install --upgrade urllib3 --user
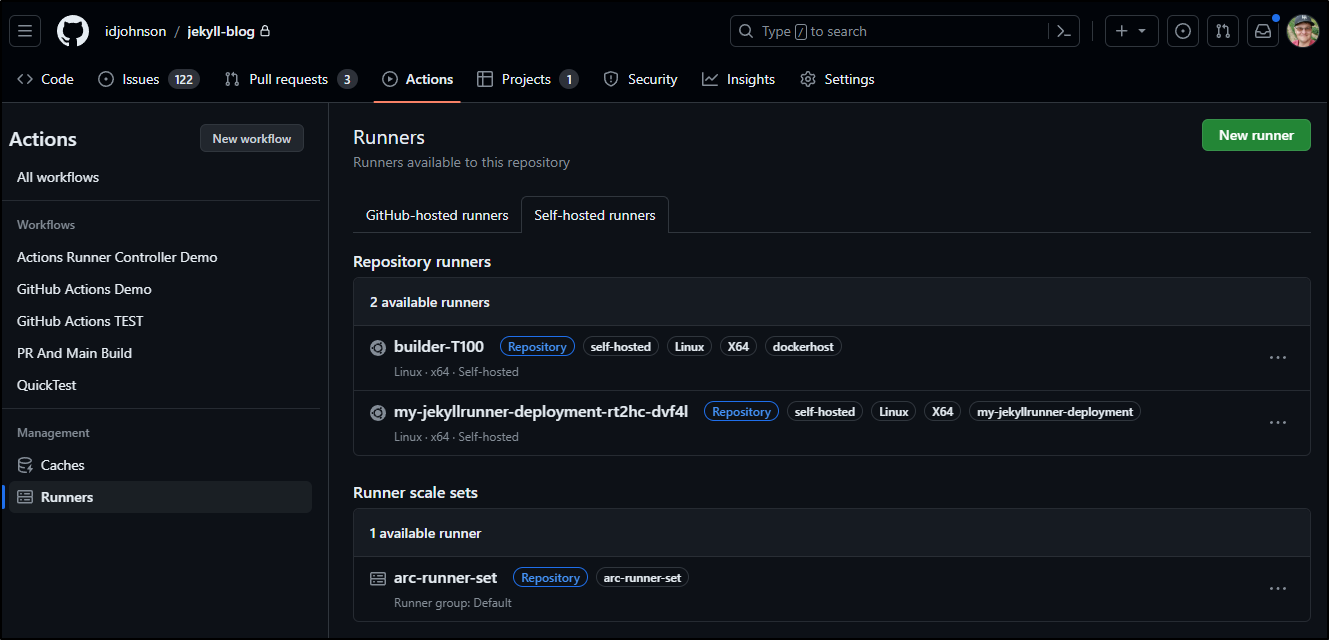
In time, with the new replacement cluster, I launched a fresh Actions Runner system:
builder@DESKTOP-QADGF36:~$ helm list -n actions-runner-system
NAME NAMESPACE REVISION UPDATED STATUS CHART
APP VERSION
actions-runner-controller actions-runner-system 1 2024-03-04 18:58:01.415392351 -0600 CST deployed actions-runner-controller-0.23.7 0.27.6
builder@DESKTOP-QADGF36:~$ helm get values actions-runner-controller -n actions-runner-system
USER-SUPPLIED VALUES:
authSecret:
create: true
github_token: ghp_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
After I set some AWS Secrets, I could use the RunnerDeployment
builder@DESKTOP-QADGF36:~$ kubectl get runnerdeployment my-jekyllrunner-deployment
NAME ENTERPRISE ORGANIZATION REPOSITORY GROUP LABELS DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
my-jekyllrunner-deployment idjohnson/jekyll-blog ["my-jekyllrunner-deployment"] 1 1 1 1 15d
builder@DESKTOP-QADGF36:~$ kubectl get runnerdeployment my-jekyllrunner-deployment -o yaml
apiVersion: actions.summerwind.dev/v1alpha1
kind: RunnerDeployment
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"actions.summerwind.dev/v1alpha1","kind":"RunnerDeployment","metadata":{"annotations":{},"name":"my-jekyllrunner-deployment","namespace":"default"},"spec":{"template":{"spec":{"dockerEnabled":true,"env":[{"name":"AWS_DEFAULT_REGION","value":"us-east-1"},{"name":"AWS_ACCESS_KEY_ID","valueFrom":{"secretKeyRef":{"key":"USER_NAME","name":"awsjekyll"}}},{"name":"AWS_SECRET_ACCESS_KEY","valueFrom":{"secretKeyRef":{"key":"PASSWORD","name":"awsjekyll"}}}],"image":"harbor.freshbrewed.science/freshbrewedprivate/myghrunner:1.1.16","imagePullPolicy":"IfNotPresent","imagePullSecrets":[{"name":"myharborreg"}],"labels":["my-jekyllrunner-deployment"],"repository":"idjohnson/jekyll-blog"}}}}
creationTimestamp: "2024-03-05T01:07:10Z"
generation: 19
name: my-jekyllrunner-deployment
namespace: default
resourceVersion: "2598657"
uid: 5f767ec8-2b9d-4f37-b042-b30078872f0e
spec:
effectiveTime: null
replicas: 1
selector: null
template:
metadata: {}
spec:
dockerEnabled: true
dockerdContainerResources: {}
env:
- name: AWS_DEFAULT_REGION
value: us-east-1
- name: AWS_ACCESS_KEY_ID
valueFrom:
secretKeyRef:
key: USER_NAME
name: awsjekyll
- name: AWS_SECRET_ACCESS_KEY
valueFrom:
secretKeyRef:
key: PASSWORD
name: awsjekyll
image: harbor.freshbrewed.science/freshbrewedprivate/myghrunner:1.1.16
imagePullPolicy: IfNotPresent
imagePullSecrets:
- name: myharborreg
labels:
- my-jekyllrunner-deployment
repository: idjohnson/jekyll-blog
resources: {}
status:
availableReplicas: 1
desiredReplicas: 1
readyReplicas: 1
replicas: 1
updatedReplicas: 1
I kept at the old server, powering it on for a few minutes, before it crashed, managed to do helm list and getting values for charts. Fetching secrets and the like.
I would tgz and stuff them onto the PVC NFS mount
Today
Today I have “Int33” to replace it.
The Master node is now a surprisingly nimble HP EliteBook 745 with a Ryzen 5 CPU.
It’s been running for 20 days without issue.
I think the last course of action here is to “graduate” it to profession monitoring. My Datadog has been offline since the cluster was finally terminated March 11th
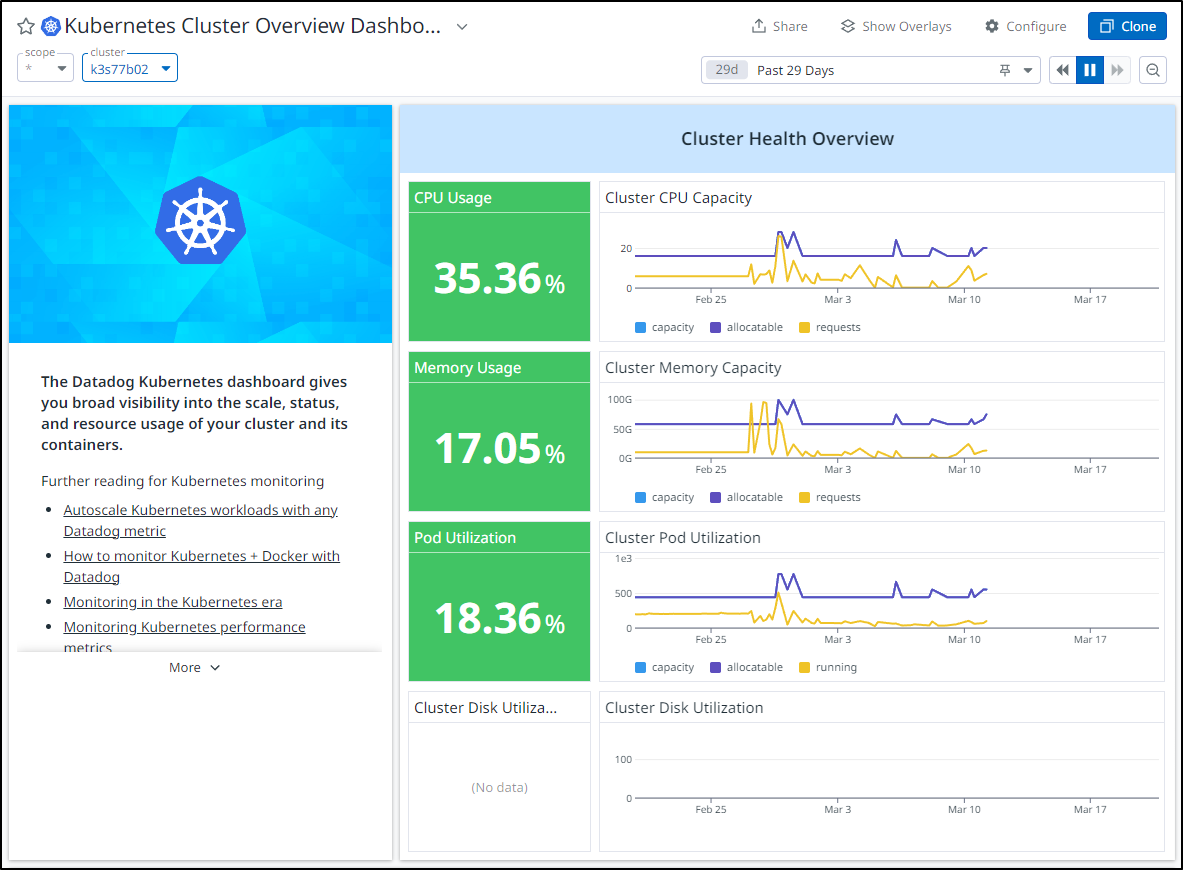
I’m going to follow the latest guide here.
I need to add the Datadog Helm repo and update
builder@DESKTOP-QADGF36:~$ helm repo add datadog https://helm.datadoghq.com
"datadog" already exists with the same configuration, skipping
builder@DESKTOP-QADGF36:~$ helm repo update
Hang tight while we grab the latest from your chart repositories...
...Unable to get an update from the "myharbor" chart repository (https://harbor.freshbrewed.science/chartrepo/library):
failed to fetch https://harbor.freshbrewed.science/chartrepo/library/index.yaml : 404 Not Found
...Unable to get an update from the "freshbrewed" chart repository (https://harbor.freshbrewed.science/chartrepo/library):
failed to fetch https://harbor.freshbrewed.science/chartrepo/library/index.yaml : 404 Not Found
...Successfully got an update from the "azure-samples" chart repository
...Successfully got an update from the "confluentinc" chart repository
...Successfully got an update from the "opencost" chart repository
...Successfully got an update from the "actions-runner-controller" chart repository
...Successfully got an update from the "hashicorp" chart repository
...Successfully got an update from the "adwerx" chart repository
...Successfully got an update from the "jfelten" chart repository
...Successfully got an update from the "akomljen-charts" chart repository
...Successfully got an update from the "opencost-charts" chart repository
...Successfully got an update from the "dapr" chart repository
...Successfully got an update from the "gitea-charts" chart repository
...Successfully got an update from the "spacelift" chart repository
...Successfully got an update from the "lifen-charts" chart repository
...Successfully got an update from the "makeplane" chart repository
...Successfully got an update from the "sonarqube" chart repository
...Successfully got an update from the "openfunction" chart repository
...Successfully got an update from the "openproject" chart repository
...Successfully got an update from the "harbor" chart repository
...Unable to get an update from the "epsagon" chart repository (https://helm.epsagon.com):
Get "https://helm.epsagon.com/index.yaml": dial tcp: lookup helm.epsagon.com on 172.22.64.1:53: server misbehaving
...Successfully got an update from the "rancher-latest" chart repository
...Successfully got an update from the "crossplane-stable" chart repository
...Successfully got an update from the "newrelic" chart repository
...Successfully got an update from the "gitlab" chart repository
...Successfully got an update from the "prometheus-community" chart repository
...Successfully got an update from the "portainer" chart repository
...Successfully got an update from the "nfs" chart repository
...Successfully got an update from the "ngrok" chart repository
...Successfully got an update from the "kuma" chart repository
...Successfully got an update from the "kube-state-metrics" chart repository
...Successfully got an update from the "btungut" chart repository
...Successfully got an update from the "zabbix-community" chart repository
...Successfully got an update from the "rhcharts" chart repository
...Successfully got an update from the "ingress-nginx" chart repository
...Successfully got an update from the "novum-rgi-helm" chart repository
...Successfully got an update from the "longhorn" chart repository
...Successfully got an update from the "nginx-stable" chart repository
...Successfully got an update from the "kubecost" chart repository
...Successfully got an update from the "elastic" chart repository
...Successfully got an update from the "castai-helm" chart repository
...Successfully got an update from the "rook-release" chart repository
...Successfully got an update from the "sumologic" chart repository
...Successfully got an update from the "kiwigrid" chart repository
...Successfully got an update from the "jetstack" chart repository
...Successfully got an update from the "signoz" chart repository
...Successfully got an update from the "openzipkin" chart repository
...Successfully got an update from the "datadog" chart repository
...Successfully got an update from the "argo-cd" chart repository
...Successfully got an update from the "uptime-kuma" chart repository
...Successfully got an update from the "ananace-charts" chart repository
...Successfully got an update from the "incubator" chart repository
...Successfully got an update from the "grafana" chart repository
...Successfully got an update from the "open-telemetry" chart repository
...Successfully got an update from the "bitnami" chart repository
Update Complete. ⎈Happy Helming!⎈
Next, I create a secret with my Datadog API Key and App Keys
$ kubectl create secret generic datadog-secret --from-literal api-key=xxxxxxxxxxxxxxxxxxxxxxxxxxbb2 --from-literal app-key=xxxxxxxxxxxxxxxxxxxxb31
secret/datadog-secret created
And a basic values file to reference the secrets
$ cat datadog-values.yaml
datadog:
apiKeyExistingSecret: datadog-secret
appKeyExistingSecret: datadog-secret
site: datadoghq.com
I can then install as a daemonset using those values
$ helm install my-datadog-release -f datadog-values.yaml --set targetSystem=linux datadog/datadog
NAME: my-datadog-release
LAST DEPLOYED: Wed Mar 20 20:06:12 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Datadog agents are spinning up on each node in your cluster. After a few
minutes, you should see your agents starting in your event stream:
https://app.datadoghq.com/event/explorer
You disabled creation of Secret containing API key, therefore it is expected
that you create Secret named 'datadog-secret' which includes a key called 'api-key' containing the API key.
###################################################################################
#### WARNING: Cluster-Agent should be deployed in high availability mode ####
###################################################################################
The Cluster-Agent should be in high availability mode because the following features
are enabled:
* Admission Controller
To run in high availability mode, our recommendation is to update the chart
configuration with:
* set `clusterAgent.replicas` value to `2` replicas .
* set `clusterAgent.createPodDisruptionBudget` to `true`.
I want logs and network monitoring.
The best way, I have found, to update that is to pull the latest values and edit them
$ helm get values my-datadog-release --all -o yaml > datadog-values.yaml.old
$ helm get values my-datadog-release --all -o yaml > datadog-values.yaml
$ vi datadog-values.yaml
I can now change those to true where I desire
$ diff -C5 datadog-values.yaml datadog-values.yaml.old
*** datadog-values.yaml 2024-03-20 20:08:31.391061041 -0500
--- datadog-values.yaml.old 2024-03-20 20:08:34.741063092 -0500
***************
*** 426,439 ****
logLevel: INFO
logs:
autoMultiLineDetection: false
containerCollectAll: false
containerCollectUsingFiles: true
! enabled: true
namespaceLabelsAsTags: {}
networkMonitoring:
! enabled: true
networkPolicy:
cilium:
dnsSelector:
toEndpoints:
- matchLabels:
--- 426,439 ----
logLevel: INFO
logs:
autoMultiLineDetection: false
containerCollectAll: false
containerCollectUsingFiles: true
! enabled: false
namespaceLabelsAsTags: {}
networkMonitoring:
! enabled: false
networkPolicy:
cilium:
dnsSelector:
toEndpoints:
- matchLabels:
***************
*** 468,478 ****
processCollection: false
processDiscovery: true
stripProcessArguments: false
prometheusScrape:
additionalConfigs: []
! enabled: enabled
serviceEndpoints: false
version: 2
remoteConfiguration:
enabled: true
sbom:
--- 468,478 ----
processCollection: false
processDiscovery: true
stripProcessArguments: false
prometheusScrape:
additionalConfigs: []
! enabled: false
serviceEndpoints: false
version: 2
remoteConfiguration:
enabled: true
sbom:
Then re-feed to the agent to enable them
$ helm upgrade --install my-datadog-release -f datadog-values.yaml --set targetSystem=linux datadog
/datadog
Release "my-datadog-release" has been upgraded. Happy Helming!
NAME: my-datadog-release
LAST DEPLOYED: Wed Mar 20 20:09:57 2024
NAMESPACE: default
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
Datadog agents are spinning up on each node in your cluster. After a few
minutes, you should see your agents starting in your event stream:
https://app.datadoghq.com/event/explorer
You disabled creation of Secret containing API key, therefore it is expected
that you create Secret named 'datadog-secret' which includes a key called 'api-key' containing the API key.
###################################################################################
#### WARNING: Cluster-Agent should be deployed in high availability mode ####
###################################################################################
The Cluster-Agent should be in high availability mode because the following features
are enabled:
* Admission Controller
To run in high availability mode, our recommendation is to update the chart
configuration with:
* set `clusterAgent.replicas` value to `2` replicas .
* set `clusterAgent.createPodDisruptionBudget` to `true`.
The first time up, i saw errors in the logs about invalid keys
2024-03-21 01:11:46 UTC | CORE | INFO | (pkg/api/healthprobe/healthprobe.go:75 in healthHandler) | Healthcheck failed on: [forwarder]
2024-03-21 01:11:52 UTC | CORE | ERROR | (comp/forwarder/defaultforwarder/transaction/transaction.go:366 in internalProcess) | API Key invalid, dropping transaction for https://7-51-0-app.agent.datadoghq.com/api/v1/check_run
2024-03-21 01:11:52 UTC | CORE | ERROR | (comp/forwarder/defaultforwarder/transaction/transaction.go:366 in internalProcess) | API Key invalid, dropping transaction for https://7-51-0-app.agent.datadoghq.com/api/v2/series
I had flip-flopped APP and API keys (darf!)
I edited the secret and deleted the existing pods to get them to rotate and take on fresh secrets
$ kubectl edit secret datadog-secret
secret/datadog-secret edited
$ kubectl get pods --all-namespaces | grep -i dog
default my-datadog-release-pmlgs 3/4 Running 0 3m59s
default my-datadog-release-txhnd 3/4 Running 0 3m59s
default my-datadog-release-crgfj 3/4 Running 0 3m59s
default my-datadog-release-cluster-agent-78d889c7c7-z8nn6 1/1 Running 0 4m
$ kubectl delete pod my-datadog-release-pmlgs & kubectl delete pod my-datadog-release-cluster-agent-78d889c7c7-z8nn6 & kubectl delete pod my-datadog-release-txhnd & kubectl delete pod my-datadog-release-crgfj
[1] 5374
[2] 5375
[3] 5376
pod "my-datadog-release-crgfj" deleted
pod "my-datadog-release-pmlgs" deleted
pod "my-datadog-release-cluster-agent-78d889c7c7-z8nn6" deleted
pod "my-datadog-release-txhnd" deleted
[1] Done kubectl delete pod my-datadog-release-pmlgs
[2]- Done kubectl delete pod my-datadog-release-cluster-agent-78d889c7c7-z8nn6
I almost immediately saw data streaming in
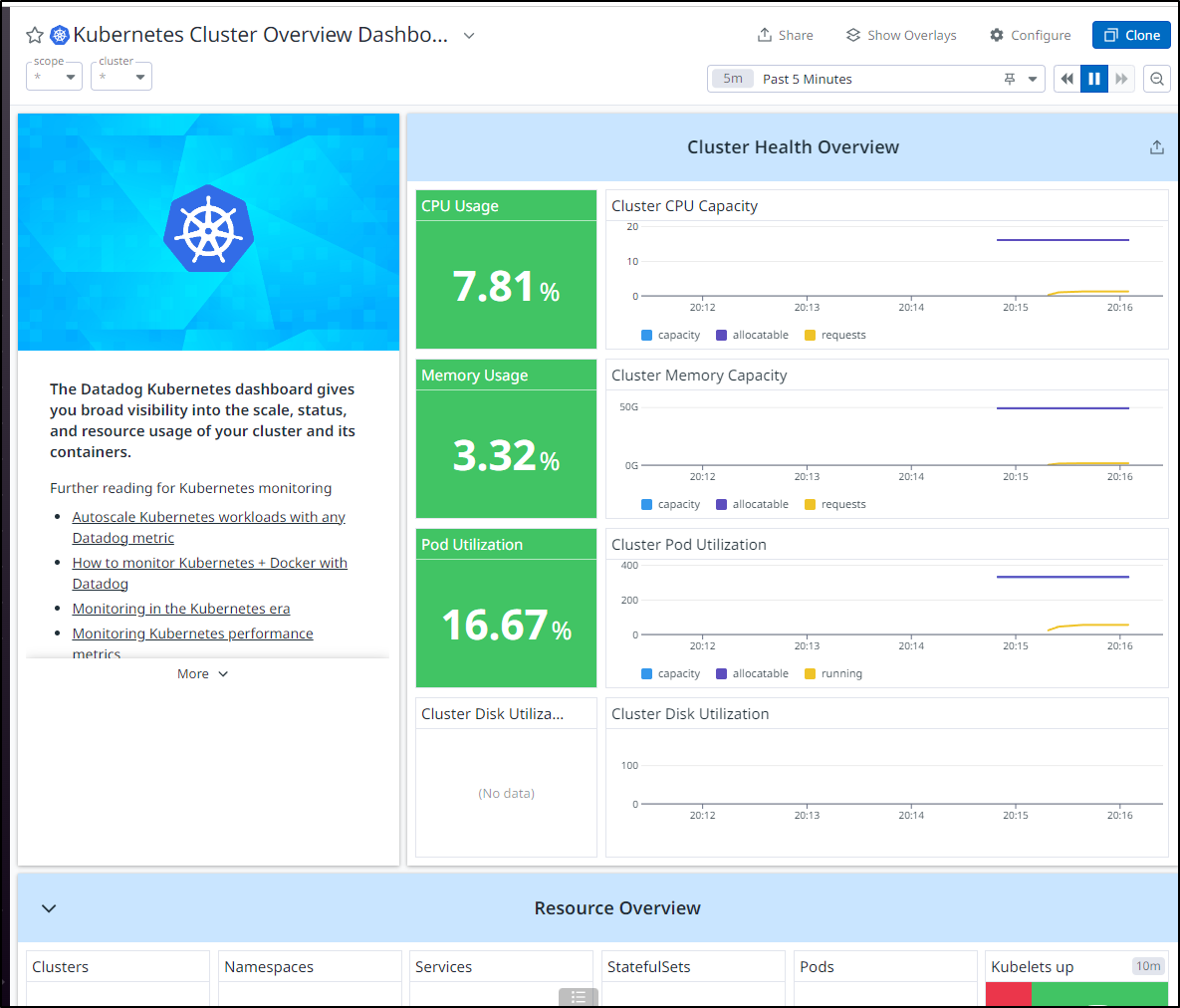
Overall, things look healthy
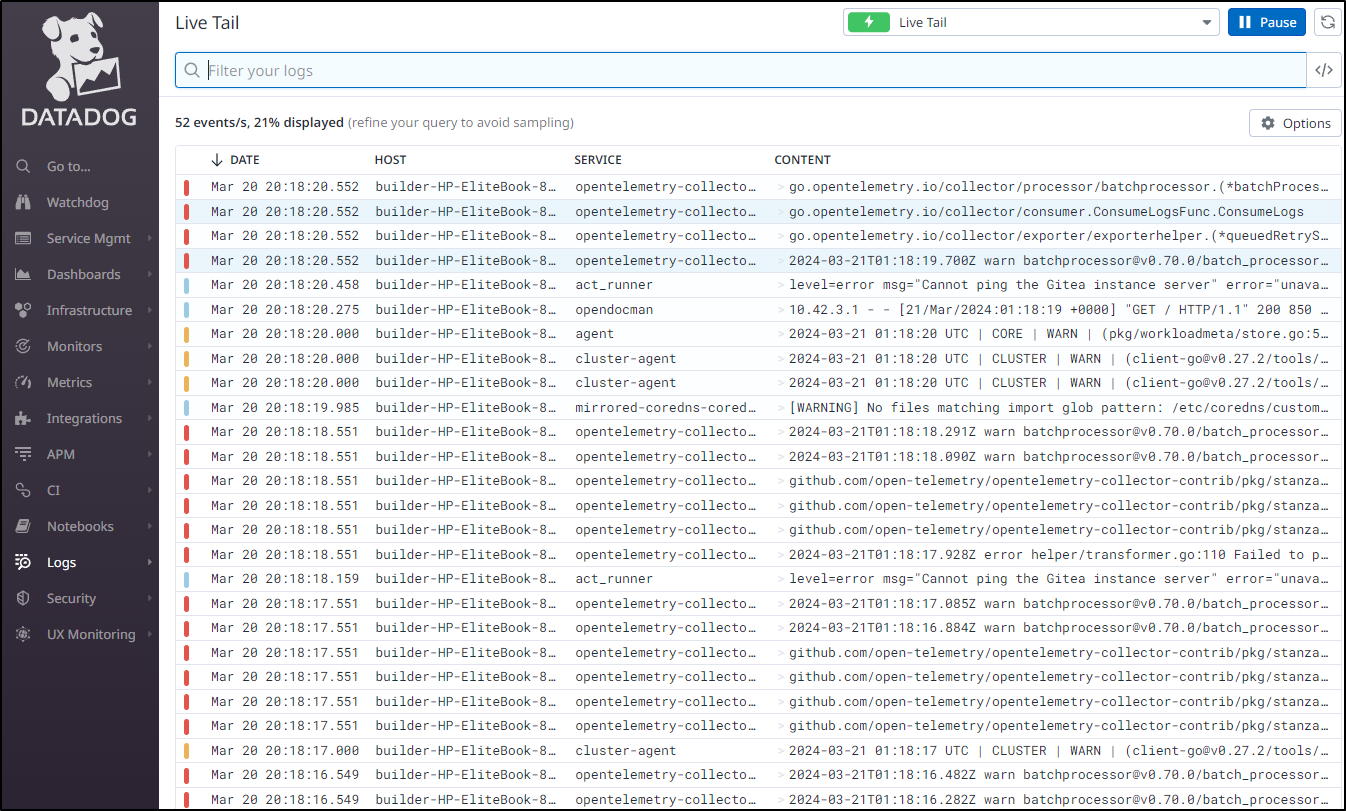
A live tail of logs show that is working just fine
In pains me a bit to see the Pod metrics as I’m in a place today for work where a Datadog cluster agent that can expose memory consumption would be so helpful
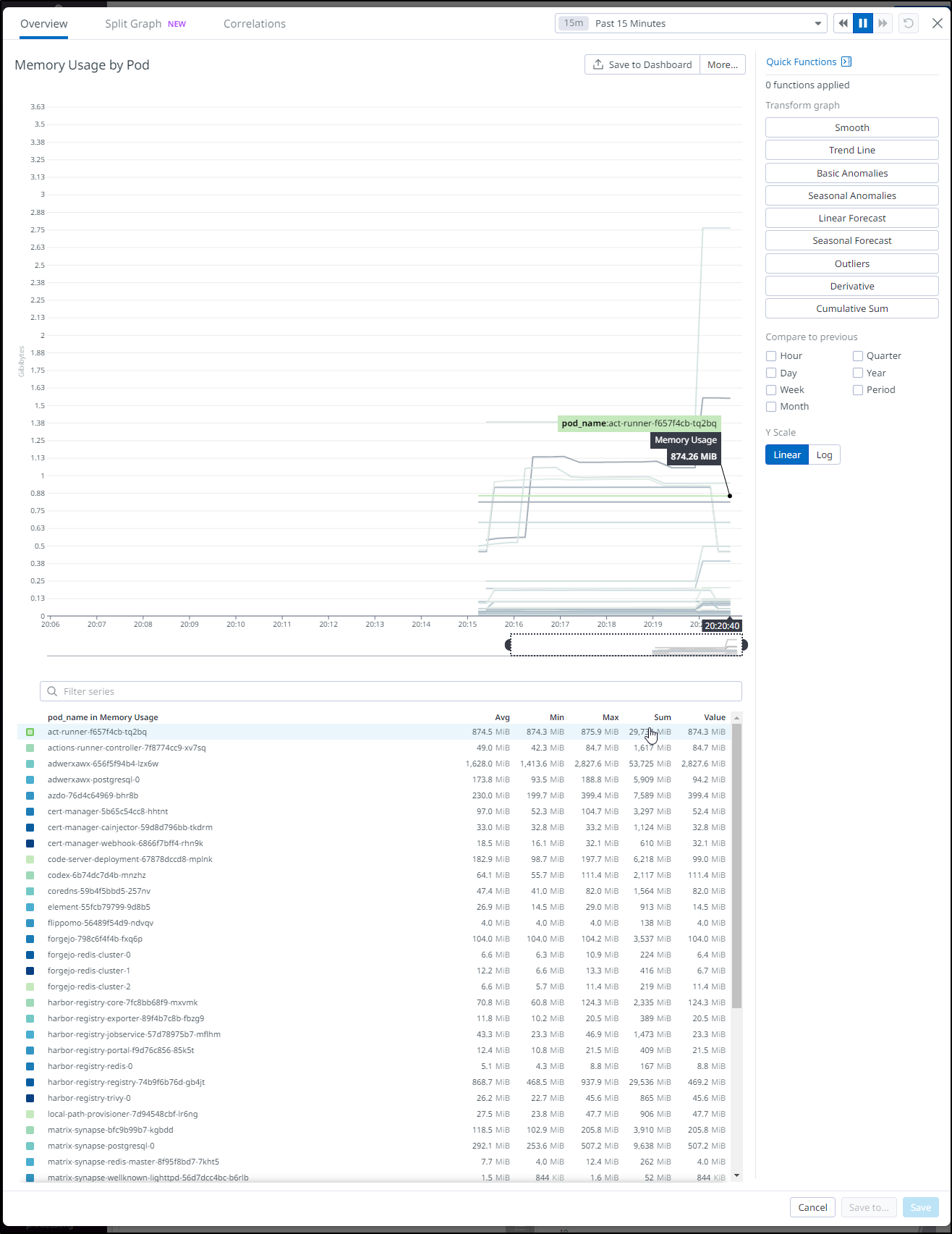
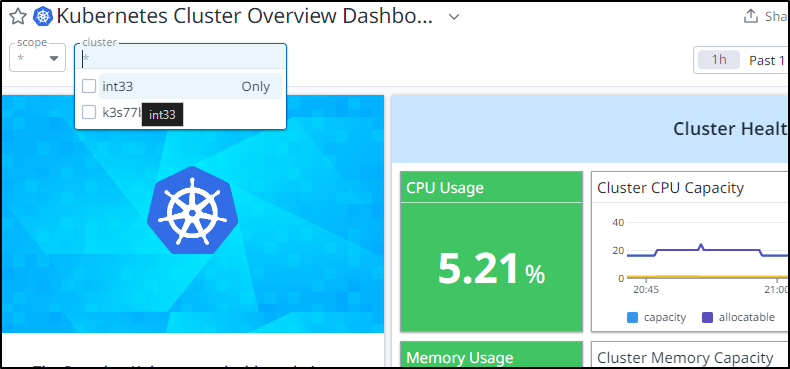
One thing I realized was the “cluster” field was set to “N/A” on my workloads.
Setting ‘datadog.clusterName’ in the helm chart fixed that.
Summary
Honestly, I’m not sure what we learned here. It could be that things don’t last forever, or that a distributed master is really the only want to keep a cluster going forever. Maybe it’s “always take a backup” should be a way of life, or “replicate. replicate. replicate”.
I thought on changing Kubernetes providers to RKE. I thought of setting up a distributed master (actually, I started down that path only to find it required at least three hosts for quorum and I couldn’t get three to agree).
I think for now, there is value in replication. There is value in backups. There is value in documenting work. The fact I pulled it together in a few days from, frankly, this actual blog (as my historical crib) and from values set aside. I replicated key containers so I wasn’t dead in the water.
Overall, it was a learning experience and if anything, I hope you enjoyed it as I documented the wild ride through to the end.
