

Published: Sep 16, 2025 by Isaac Johnson
I can handle power blips. I can even handle a few hours out; between the laptops that serve as nodes and my variety of APC battery backups - it can go a while. But 7 hours, which is how long yesterday’s power outage went, does tend to take the whole damn thing down.
Even worse, in powering up, all my IPs swapped up and even my external ingress IP - which has lasted well over a year, has changed.
I had hoped, by some miracle, that going to bed and getting up would give enough time for k3s to just sort it all out on its own.
However, this morning, i checked and none of the nodes were rejoining
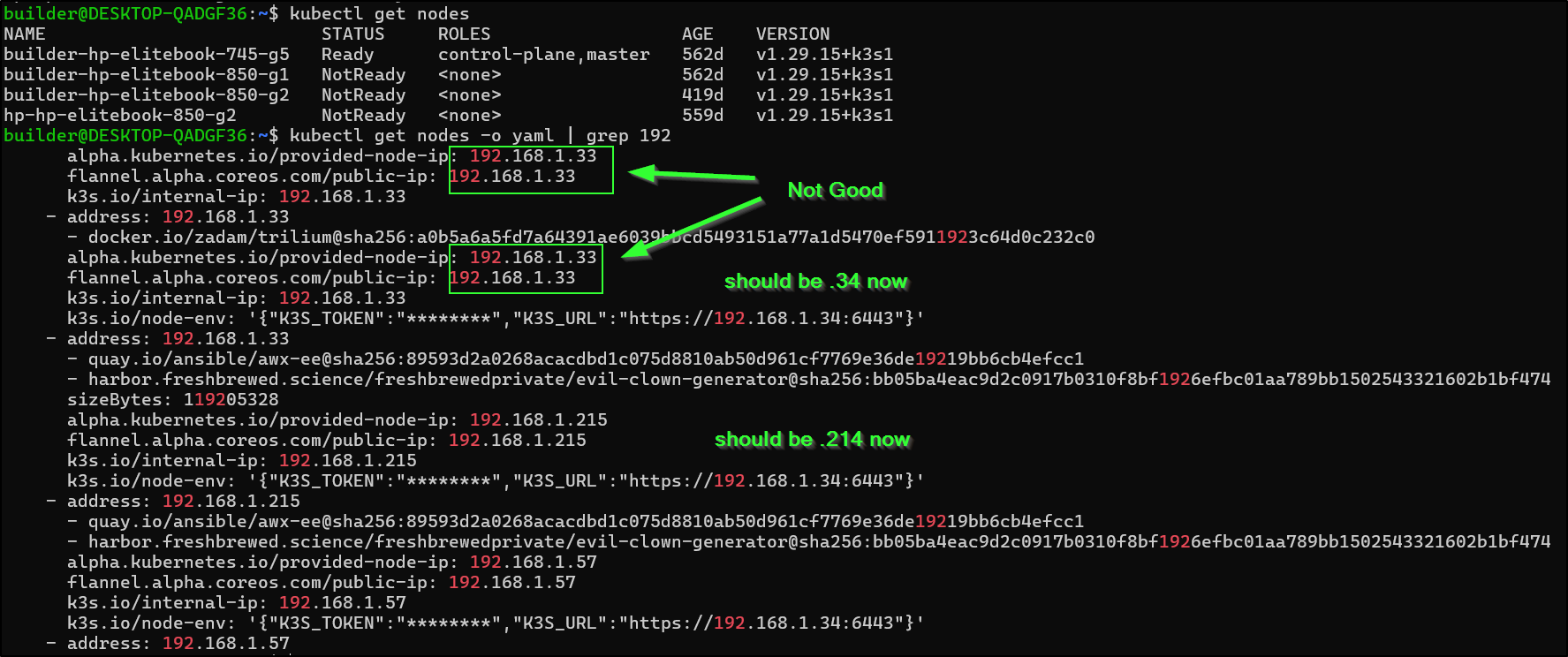
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
builder-hp-elitebook-745-g5 Ready control-plane,master 562d v1.29.15+k3s1
builder-hp-elitebook-850-g1 NotReady <none> 562d v1.29.15+k3s1
builder-hp-elitebook-850-g2 NotReady <none> 419d v1.29.15+k3s1
hp-hp-elitebook-850-g2 NotReady <none> 559d v1.29.15+k3s1
I think this is because the master/control-plane host swapped from 192.168.1.34 back to 1.33 and the g1 was using that before.
I will start with the conflicting IP server first “builder-hp-elitebook-850-g1”
First, I stopped the service and fixed the target URL in the k3s-agent.service.env file
builder@builder-HP-EliteBook-850-G1:~$ sudo systemctl stop k3s-agent.service
[sudo] password for builder:
builder@builder-HP-EliteBook-850-G1:~$ sudo vi /etc/systemd/system/k3s-agent.service.env
builder@builder-HP-EliteBook-850-G1:~$ sudo cat /etc/systemd/system/k3s-agent.service.env
K3S_TOKEN='K10ef48ebf2c2adb1da135c5fd0ad3fa4966ac35da5d6d941de7ecaa52d48993605::server:ed854070980c4560bbba49f8217363d4'
K3S_URL='https://192.168.1.33:6443'
builder@builder-HP-EliteBook-850-G1:~$ echo "fixed to .33 from .34"
fixed to .33 from .34
I removed the node from the cluster
builder@DESKTOP-QADGF36:~$ kubectl delete node builder-hp-elitebook-850-g1
node "builder-hp-elitebook-850-g1" deleted
I decided to just try and start it back up by way of the service to see if it would just magically rejoin
builder@builder-HP-EliteBook-850-G1:~$ sudo systemctl start k3s-agent.service
builder@builder-HP-EliteBook-850-G1:~$
Indeed it did
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
builder-hp-elitebook-745-g5 Ready control-plane,master 562d v1.29.15+k3s1
builder-hp-elitebook-850-g1 Ready <none> 12s v1.29.15+k3s1
builder-hp-elitebook-850-g2 NotReady <none> 419d v1.29.15+k3s1
hp-hp-elitebook-850-g2 NotReady <none> 559d v1.29.15+k3s1
The describe clues me in to two things, the pressures are checked and are now good
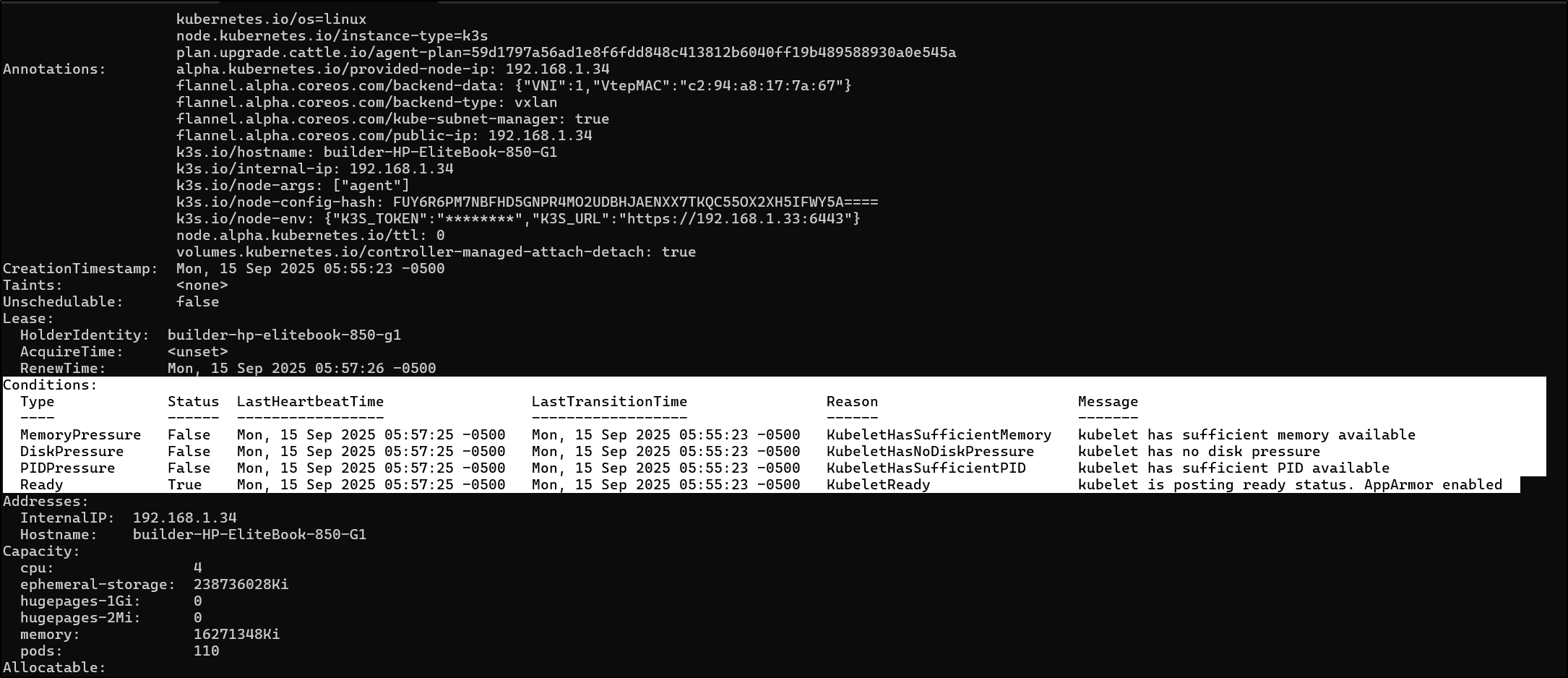
and it would seem the workloads stayed put during the process
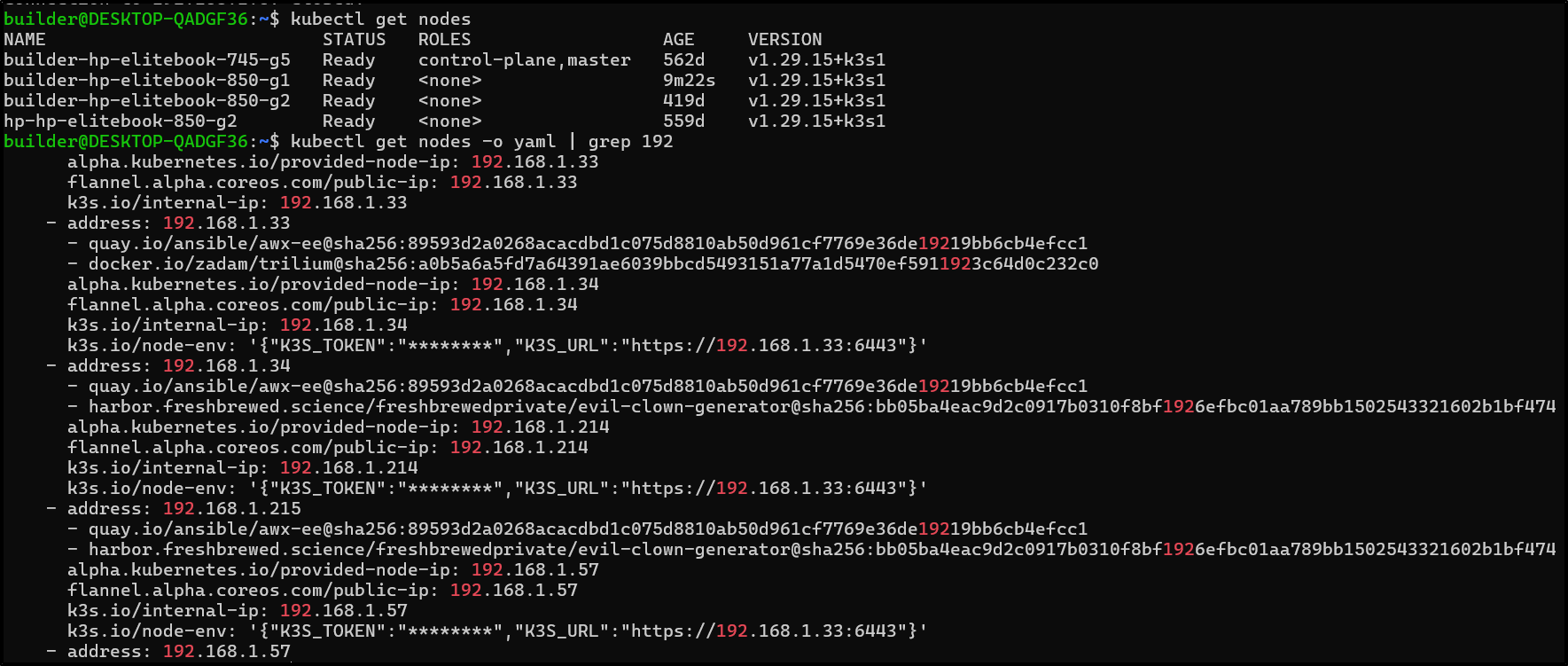
A quick check of IPs shows it has properly updated
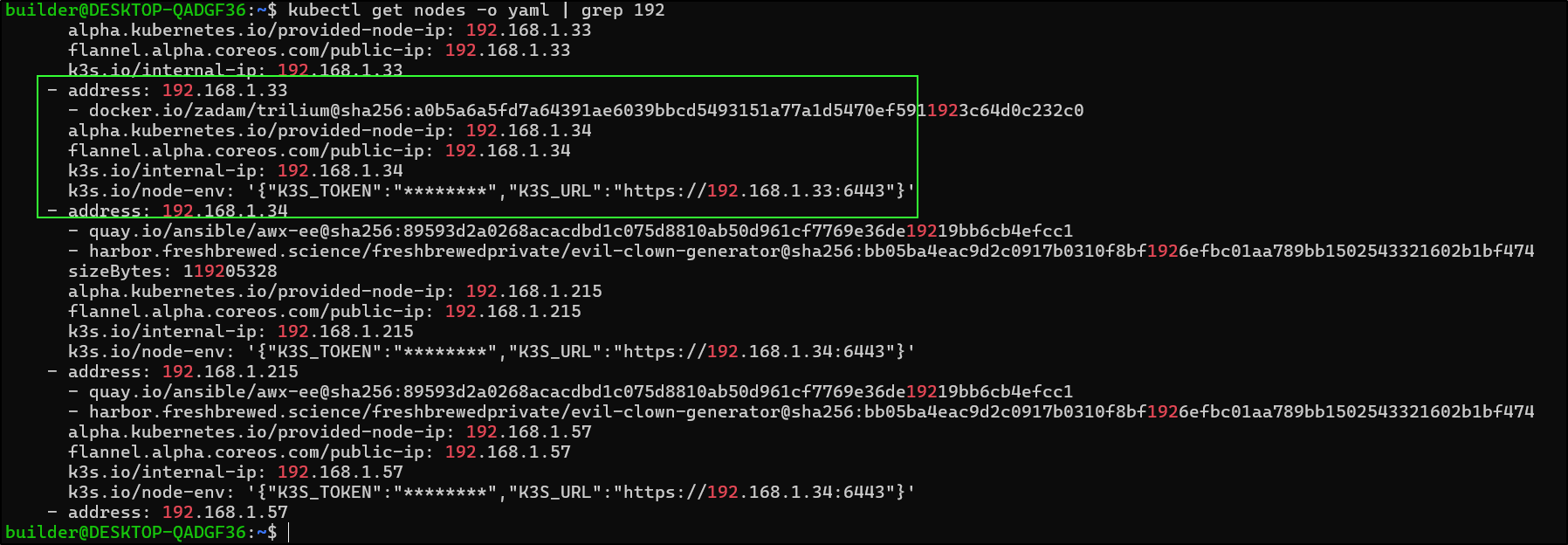
The host who hadn’t changed IPs was easier. I just had to correct the destination IP in the service.env and start it back up (change from .34 to .33)
hp@hp-HP-EliteBook-850-G2:~$ sudo systemctl stop k3s-agent.service
[sudo] password for hp:
hp@hp-HP-EliteBook-850-G2:~$ sudo vi /etc/systemd/system/k3s-agent.service.env
hp@hp-HP-EliteBook-850-G2:~$ sudo systemctl start k3s-agent.service
hp@hp-HP-EliteBook-850-G2:~$ sudo cat /etc/systemd/system/k3s-agent.service.env
K3S_TOKEN='K10ef48ebf2c2adb1da135c5fd0ad3fa4966ac35da5d6d941de7ecaa52d48993605::server:ed854070980c4560bbba49f8217363d4'
K3S_URL='https://192.168.1.33:6443'

For my last test, I tried just fixing the service.env and seeing if it would fix the IP on rejoin. That is, unlike that first (g1) host, do I really need to “delete” the node to fix a moved IP.
I fixed the IP on the hosts env file and stopped/started it
builder@builder-HP-EliteBook-850-G2:~$ sudo systemctl stop k3s-agent.service
builder@builder-HP-EliteBook-850-G2:~$ sudo systemctl start k3s-agent.service
builder@builder-HP-EliteBook-850-G2:~$ sudo cat /etc/systemd/system/k3s-agent.service.env
K3S_TOKEN='K10ef48ebf2c2adb1da135c5fd0ad3fa4966ac35da5d6d941de7ecaa52d48993605::server:ed854070980c4560bbba49f8217363d4'
K3S_URL='https://192.168.1.33:6443'
It came up without issue and I see the new .214 (from .215) IP in the node list
Next, I need to deal with the pods that are failing
$ kubectl get pods --all-namespaces --field-selector=status.phase!=Running,status.phase!=Succeeded -o=jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{"\n"}{end}' | xargs -n 2 kubectl get pod -n
NAME READY STATUS RESTARTS AGE
logingest-logingest-87b969469-jfmzb 0/1 ImagePullBackOff 0 9m40s
NAME READY STATUS RESTARTS AGE
evil-clown-generator-7f75df9d6c-g9s7r 0/1 ImagePullBackOff 0 14h
NAME READY STATUS RESTARTS AGE
evil-clown-generator-7f75df9d6c-sdzf8 0/1 ImagePullBackOff 0 14h
NAME READY STATUS RESTARTS AGE
medama-deployment-55f5fdf5f4-r56tn 0/1 ImagePullBackOff 0 14h
NAME READY STATUS RESTARTS AGE
meet-db-migrate-k2qr6 0/1 Pending 0 30d
NAME READY STATUS RESTARTS AGE
nextbeats-675f7d7557-m2ddl 0/1 ImagePullBackOff 0 9m46s
NAME READY STATUS RESTARTS AGE
pybsposter-7c5764db94-8mvqc 0/1 ImagePullBackOff 0 14h
NAME READY STATUS RESTARTS AGE
pyrestforpipelines-7c9cc7bc47-zwzcg 0/1 ImagePullBackOff 0 14h
NAME READY STATUS RESTARTS AGE
spacedeck-deployment-5b684f4576-877vz 0/1 ImagePullBackOff 0 9m45s
I can rotate the lot of them
$ kubectl get pods --all-namespaces --field-selector=status.phase!=Running,status.phase!=Succeeded -o=jsonpath='{range .items[*]}{.metadata.namespace}{" "}{.metadata.name}{"\n"}{end}' | xargs -n 2 kubectl delete pod -n
pod "logingest-logingest-87b969469-jfmzb" deleted
pod "evil-clown-generator-7f75df9d6c-g9s7r" deleted
pod "evil-clown-generator-7f75df9d6c-sdzf8" deleted
pod "medama-deployment-55f5fdf5f4-r56tn" deleted
pod "meet-db-migrate-k2qr6" deleted
pod "nextbeats-675f7d7557-m2ddl" deleted
pod "pybsposter-7c5764db94-8mvqc" deleted
pod "pyrestforpipelines-7c9cc7bc47-zwzcg" deleted
pod "spacedeck-deployment-5b684f4576-877vz" deleted
Ingress
Another issue is due to the large outage, my ingress IP from my terrible ISP changed as well
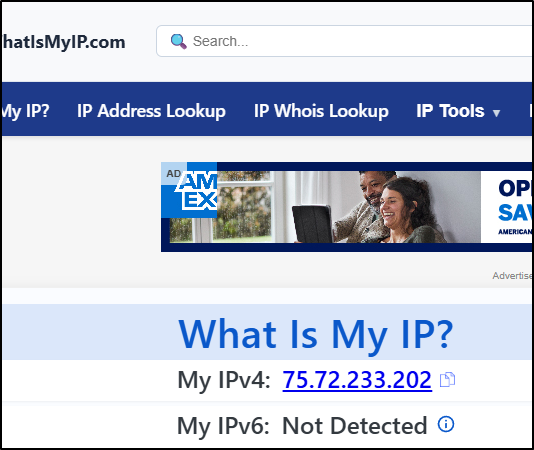
That really stinks because I’ve kind of gone nuts with the A records lately.
Azure
The first is my tpk.pw which has a lot of records. I can get away with updating AWS and Google by hand if I had to, but Azure DNS.. way too many.
I worked this a few ways. Most of the AI assistants had the syntax wrong or tried to filter on ipV4 the wrong way.
In the end, this is the working script:
$ cat ./updateAz.sh
#!/bin/bash
rm o.txt || true
# Get all the A records that are OLD
az network dns record-set a list --zone-name tpk.pw --resource-group idjdnsrg -o json | \
jq -r '.[] | select(.ARecords[].ipv4Address == "75.73.224.240") | "\(.name)"' | tee o.txt
# For each, update them
while IFS= read -r WORD; do
if [ -n "$WORD" ]; then
echo "Updating record: $WORD"
az network dns record-set a remove-record -g idjdnsrg -z tpk.pw --record-set-name "$WORD" --ipv4-address 75.73.224.240 && \
az network dns record-set a add-record -g idjdnsrg -z tpk.pw -a 75.72.233.202 -n "$WORD"
fi
done < o.txt
I can spot check in the portal
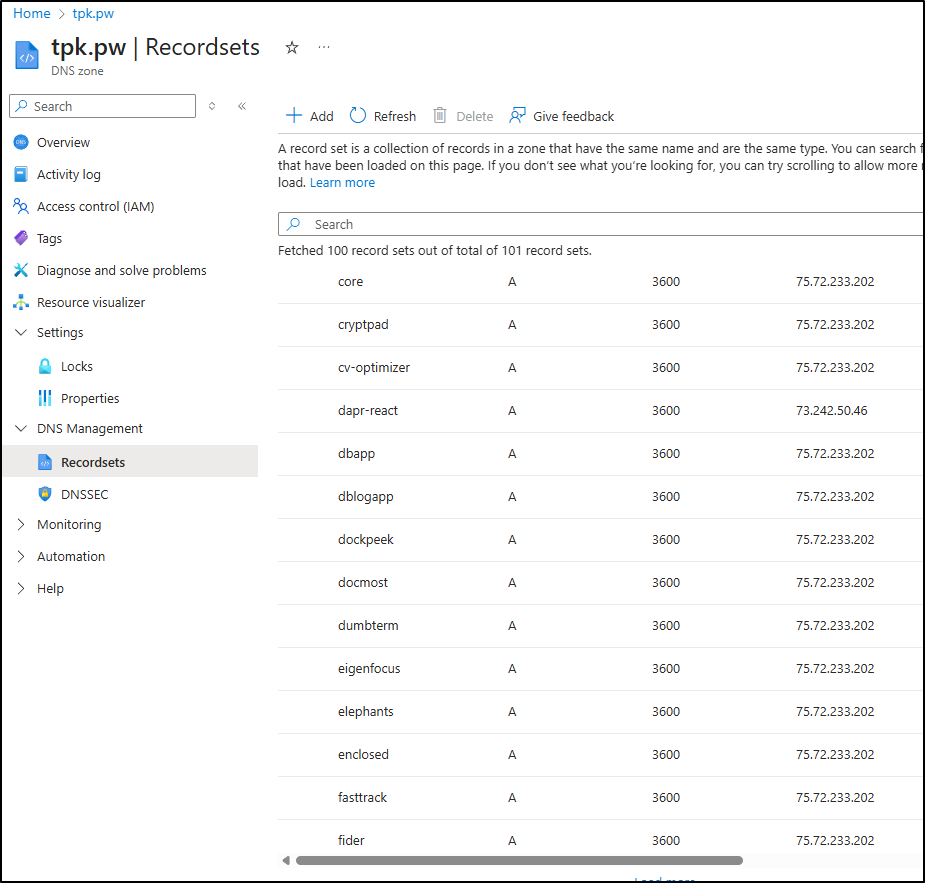
GCP / Google Cloud DNS
Next, we need to tackle the “steeped.space” entries.
I now have a pattern with Azure I can use with gcloud
$ cat ./gcloud.sh
#!/bin/bash
rm -f g.txt
gcloud dns --project=myanthosproject2 record-sets list --zone="steepedspace" | grep 75.73.224.240 | sed 's/ .*//' | tee g.txt
# For each, update them
while IFS= read -r WORD; do
if [ -n "$WORD" ]; then
echo "Updating record: $WORD"
gcloud dns record-sets update $WORD --rrdatas=75.72.233.202 --type=A --ttl=300 --zone="steepedspace" --project=myanthosproject2
fi
done < g.txt
I can now spot check in the Cloud Console and see the old records are updated (and things that did not point to my cluster were left alone)
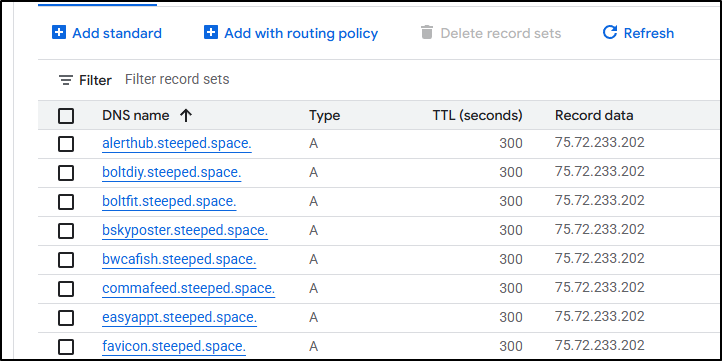
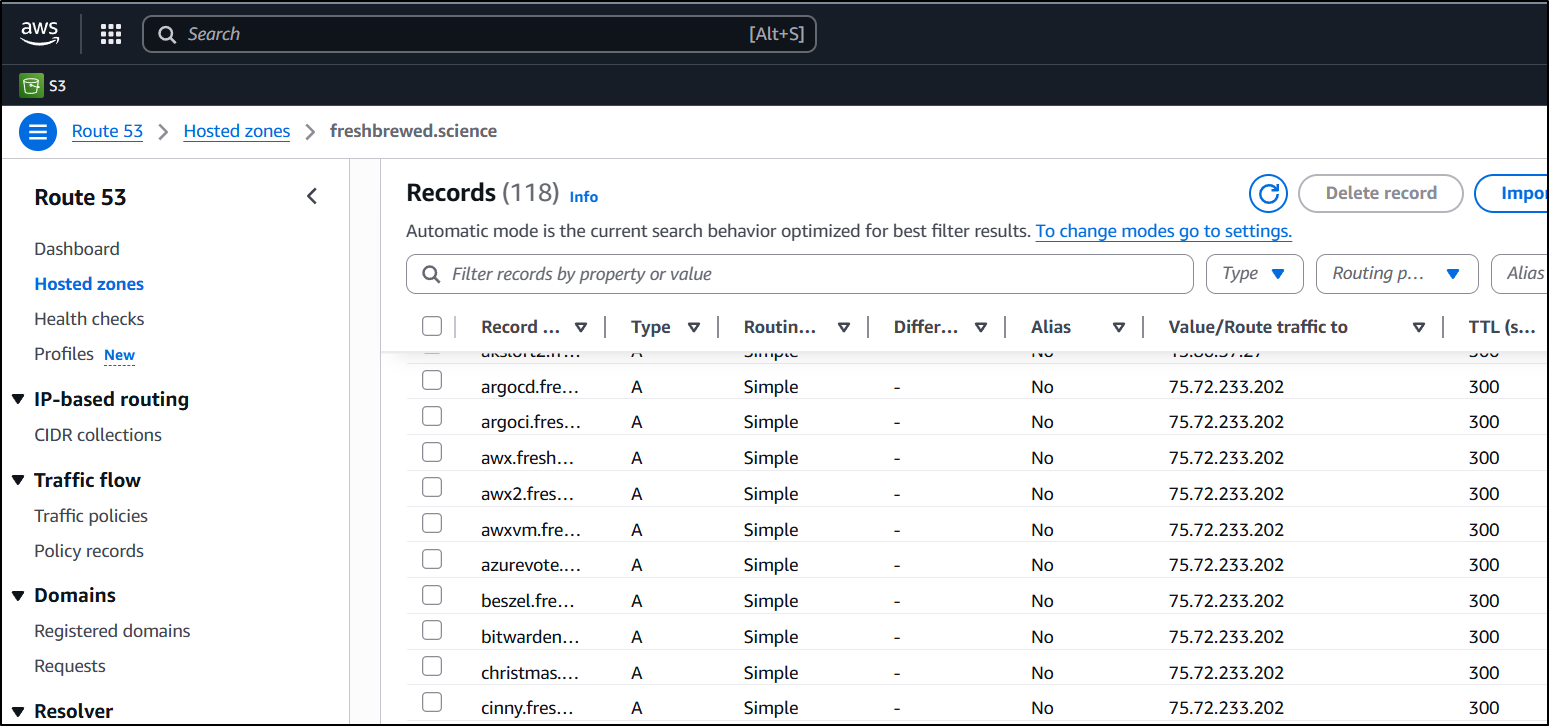
AWS
AWS Route53 needed updates as well. This is my permanent production domain of freshbrewed.science so I’m a bit more careful here.
I did each part as steps - first getting my records then forming a list of domain entries, one per line. I then would iterate through and create update records (in AWS they are “UPSERT”). Lastly, I echoed the lines first so I could test, then I took out echo to actually run the aws route53 change-record-sets command
$ cat ./awsdns.sh
#!/bin/bash
rm -f aws.json || true
aws route53 list-resource-record-sets --hosted-zone-id Z39E8QFU0F9PZP > aws.json
rm -f awstofix.txt || true
jq -r '.ResourceRecordSets[] | select(.ResourceRecords[]?.Value == "75.73.224.240") | .Name' aws.json | sed 's/\.$//' | tee awstofix.txt
rm -rf ./tmpaws || true
mkdir -p tmpaws || true
# For each, update them
while IFS= read -r WORD; do
if [ -n "$WORD" ]; then
echo "creating JSON record in ./tmpaws: $WORD"
cat >./tmpaws/$WORD.json <<EOL
{
"Comment": "UPDATE $WORD fb.s A record ",
"Changes": [
{
"Action": "UPSERT",
"ResourceRecordSet": {
"Name": "$WORD",
"Type": "A",
"TTL": 300,
"ResourceRecords": [
{
"Value": "75.72.233.202"
}
]
}
}
]
}
EOL
fi
done < awstofix.txt
echo "Now applying"
while IFS= read -r WORD; do
if [ -n "$WORD" ]; then
echo "creating JSON record in ./tmpaws: $WORD"
aws route53 change-resource-record-sets --hosted-zone-id Z39E8QFU0F9PZP --change-batch file://./tmpaws/$WORD.json
fi
done < awstofix.txt
Just a snippet
$ ls -l ./tmpaws/
total 324
-rw-r--r-- 1 builder builder 422 Sep 15 07:44 argoci.freshbrewed.science.json
-rw-r--r-- 1 builder builder 416 Sep 15 07:44 awx.freshbrewed.science.json
-rw-r--r-- 1 builder builder 418 Sep 15 07:44 awx2.freshbrewed.science.json
-rw-r--r-- 1 builder builder 420 Sep 15 07:44 awxvm.freshbrewed.science.json
-rw-r--r-- 1 builder builder 428 Sep 15 07:44 azurevote.freshbrewed.science.json
-rw-r--r-- 1 builder builder 422 Sep 15 07:44 beszel.freshbrewed.science.json
-rw-r--r-- 1 builder builder 428 Sep 15 07:44 bitwarden.freshbrewed.science.json
-rw-r--r-- 1 builder builder 428 Sep 15 07:44 christmas.freshbrewed.science.json
-rw-r--r-- 1 builder builder 420 Sep 15 07:44 cinny.freshbrewed.science.json
-rw-r--r-- 1 builder builder 438 Sep 15 07:44 cloudcustodian.freshbrewed.science.json
-rw-r--r-- 1 builder builder 418 Sep 15 07:44 code.freshbrewed.science.json
-rw-r--r-- 1 builder builder 420 Sep 15 07:44 codex.freshbrewed.science.json
-rw-r--r-- 1 builder builder 418 Sep 15 07:44 core.freshbrewed.science.json
-rw-r--r-- 1 builder builder 432 Sep 15 07:44 core.harbor.freshbrewed.science.json
-rw-r--r-- 1 builder builder 432 Sep 15 07:44 disabledsvc.freshbrewed.science.json
-rw-r--r-- 1 builder builder 430 Sep 15 07:44 docusaurus.freshbrewed.science.json
-rw-r--r-- 1 builder builder 424 Sep 15 07:44 dokemon.freshbrewed.science.json
-rw-r--r-- 1 builder builder 418 Sep 15 07:44 dufs.freshbrewed.science.json
-rw-r--r-- 1 builder builder 424 Sep 15 07:44 element.freshbrewed.science.json
-rw-r--r-- 1 builder builder 432 Sep 15 07:44 filebrowser.freshbrewed.science.json
-rw-r--r-- 1 builder builder 430 Sep 15 07:44 fluffychat.freshbrewed.science.json
-rw-r--r-- 1 builder builder 418 Sep 15 07:44 foo2.freshbrewed.science.json
-rw-r--r-- 1 builder builder 418 Sep 15 07:44 foo4.freshbrewed.science.json
-rw-r--r-- 1 builder builder 418 Sep 15 07:44 foo5.freshbrewed.science.json
-rw-r--r-- 1 builder builder 424 Sep 15 07:44 forgejo.freshbrewed.science.json
-rw-r--r-- 1 builder builder 424 Sep 15 07:44 gbwebui.freshbrewed.science.json
-rw-r--r-- 1 builder builder 420 Sep 15 07:44 gitea.freshbrewed.science.json
... snip ...
And, for example, what a record looks like
builder@DESKTOP-QADGF36:~$ cat ./tmpaws/argoci.freshbrewed.science.json
{
"Comment": "UPDATE argoci.freshbrewed.science fb.s A record ",
"Changes": [
{
"Action": "UPSERT",
"ResourceRecordSet": {
"Name": "argoci.freshbrewed.science",
"Type": "A",
"TTL": 300,
"ResourceRecords": [
{
"Value": "75.72.233.202"
}
]
}
}
]
}
Lastly, a snippet of the output when run
$ ./updateAz.sh
rm: cannot remove 'o.txt': No such file or directory
1dev
airstation
audioshelf
... snip ...
Updating record: 1dev
{
"ARecords": [
{
"ipv4Address": "75.72.233.202"
}
],
"TTL": 3600,
"etag": "fe5d766f-1d1b-4462-9d8c-2827f534ab47",
"fqdn": "1dev.tpk.pw.",
"id": "/subscriptions/d955c0ba-13dc-44cf-a29a-8fed74cbb22d/resourceGroups/idjdnsrg/providers/Microsoft.Network/dnszones/tpk.pw/A/1dev",
"name": "1dev",
"provisioningState": "Succeeded",
"resourceGroup": "idjdnsrg",
"targetResource": {},
"trafficManagementProfile": {},
"type": "Microsoft.Network/dnszones/A"
}
I did a spot check to test
Firewall
I need to update my Asus router now since it’s routing all 80/443 to a node, yes, but not the control plane node

I changed those to .33 as well as the external k3s ingress I use for the control plane access.
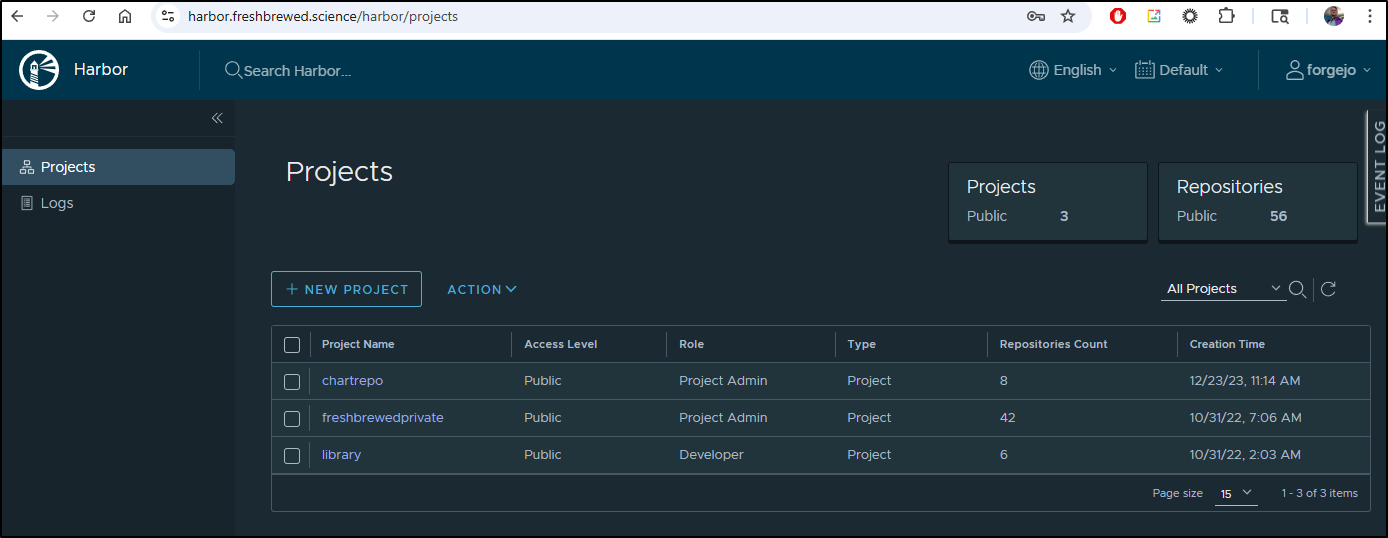
Harbor
Harbor seems stuck with the wrong IP for the database
$ kubectl get po | grep harbor
harbor-registry-core-7fc8bb68f9-zbbmc 0/1 CrashLoopBackOff 5 (34s ago) 9m46s
$ kubectl logs harbor-registry-core-7fc8bb68f9-zbbmc | tail -n 10
2025-09-15T13:29:43Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:45Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:47Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:49Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:51Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:53Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:55Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:57Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:29:59Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:30:01Z [FATAL] [/core/main.go:184]: failed to initialize database: failed to connect to tcp:192.168.1.34:5432 after 60 seconds
My helm values are correct
$ kubectl get ingress harbor-registry-ingress -o yaml > harbor-registry-ingress.yaml
$ cat harbor-registry.yaml
database:
external:
host: 192.168.1.33
But it seems the CM is the problem
$ kubectl get cm harbor-registry-core -o yaml | grep -i POSTGRES
DATABASE_TYPE: postgresql
POSTGRESQL_DATABASE: registry
POSTGRESQL_HOST: 192.168.1.34
POSTGRESQL_MAX_IDLE_CONNS: "100"
POSTGRESQL_MAX_OPEN_CONNS: "900"
POSTGRESQL_PORT: "5432"
POSTGRESQL_SSLMODE: disable
POSTGRESQL_USERNAME: harbor
I’ll first try just an inline edit and rotate
$ kubectl edit cm harbor-registry-core
configmap/harbor-registry-core edited
$ kubectl get cm harbor-registry-core -o yaml | grep -i POSTGRES
DATABASE_TYPE: postgresql
POSTGRESQL_DATABASE: registry
POSTGRESQL_HOST: 192.168.1.33
POSTGRESQL_MAX_IDLE_CONNS: "100"
POSTGRESQL_MAX_OPEN_CONNS: "900"
POSTGRESQL_PORT: "5432"
POSTGRESQL_SSLMODE: disable
POSTGRESQL_USERNAME: harbor
$ kubectl delete po harbor-registry-core-7fc8bb68f9-zbbmc
pod "harbor-registry-core-7fc8bb68f9-zbbmc" deleted
That fixed core and job service, but not exporter
$ kubectl get po | grep harbor
harbor-registry-core-7fc8bb68f9-zmcc9 1/1 Running 0 114s
harbor-registry-exporter-89f4b7c8b-hhmsj 0/1 CrashLoopBackOff 5 (2m44s ago) 12m
harbor-registry-jobservice-57d78975b7-mdg42 1/1 Running 7 (6m4s ago) 11m
harbor-registry-portal-f9d76c856-85k5t 1/1 Running 29 (12h ago) 561d
harbor-registry-redis-0 1/1 Running 14 (12h ago) 30d
harbor-registry-registry-74b9f6b76d-q9bhp 2/2 Running 0 16h
harbor-registry-trivy-0 1/1 Running 3 (12h ago) 7d22h
$ kubectl delete po harbor-registry-exporter-89f4b7c8b-hhmsj
pod "harbor-registry-exporter-89f4b7c8b-hhmsj" deleted
seems exporter must have a bad setting too
$ kubectl logs harbor-registry-exporter-89f4b7c8b-5gztw
Appending internal tls trust CA to ca-bundle ...
find: '/etc/harbor/ssl': No such file or directory
Internal tls trust CA appending is Done.
2025-09-15T13:33:01Z [INFO] [/common/dao/base.go:67]: Registering database: type-PostgreSQL host-192.168.1.34 port-5432 database-registry sslmode-"disable"
2025-09-15T13:33:01Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:33:03Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:33:05Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:33:07Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:33:09Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
2025-09-15T13:33:11Z [ERROR] [/common/utils/utils.go:108]: failed to connect to tcp://192.168.1.34:5432, retry after 2 seconds :dial tcp 192.168.1.34:5432: connect: connection refused
Indeed it does
$ kubectl get cm harbor-registry-exporter-env -o yaml | grep DATABASE
HARBOR_DATABASE_DBNAME: registry
HARBOR_DATABASE_HOST: 192.168.1.34
HARBOR_DATABASE_MAX_IDLE_CONNS: "100"
HARBOR_DATABASE_MAX_OPEN_CONNS: "900"
HARBOR_DATABASE_PORT: "5432"
HARBOR_DATABASE_SSLMODE: disable
HARBOR_DATABASE_USERNAME: harbor
Once I fixed and rotated
$ kubectl edit cm harbor-registry-exporter-env
configmap/harbor-registry-exporter-env edited
$ kubectl delete po harbor-registry-exporter-89f4b7c8b-5gztw
pod "harbor-registry-exporter-89f4b7c8b-5gztw" deleted
I could see all my harbor pods were happy again
$ kubectl get po | grep harbor
harbor-registry-core-7fc8bb68f9-zmcc9 1/1 Running 0 14m
harbor-registry-exporter-89f4b7c8b-brzvb 1/1 Running 0 10m
harbor-registry-jobservice-57d78975b7-mdg42 1/1 Running 7 (19m ago) 24m
harbor-registry-portal-f9d76c856-85k5t 1/1 Running 29 (12h ago) 561d
harbor-registry-redis-0 1/1 Running 14 (12h ago) 30d
harbor-registry-registry-74b9f6b76d-q9bhp 2/2 Running 0 17h
harbor-registry-trivy-0 1/1 Running 3 (12h ago) 7d22h
And harbor showed itself to be alive
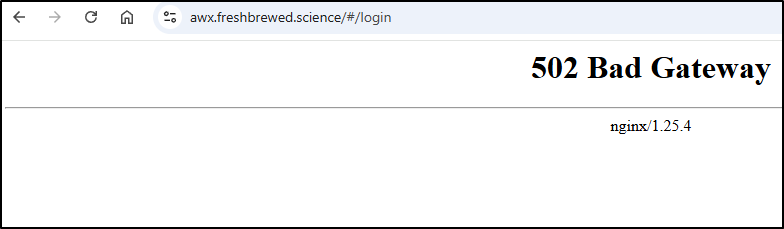
AWX
When it came time to post this, I was suprised to see the AWX system failed to complete the PR.
I checked and to my suprise, AWX was down
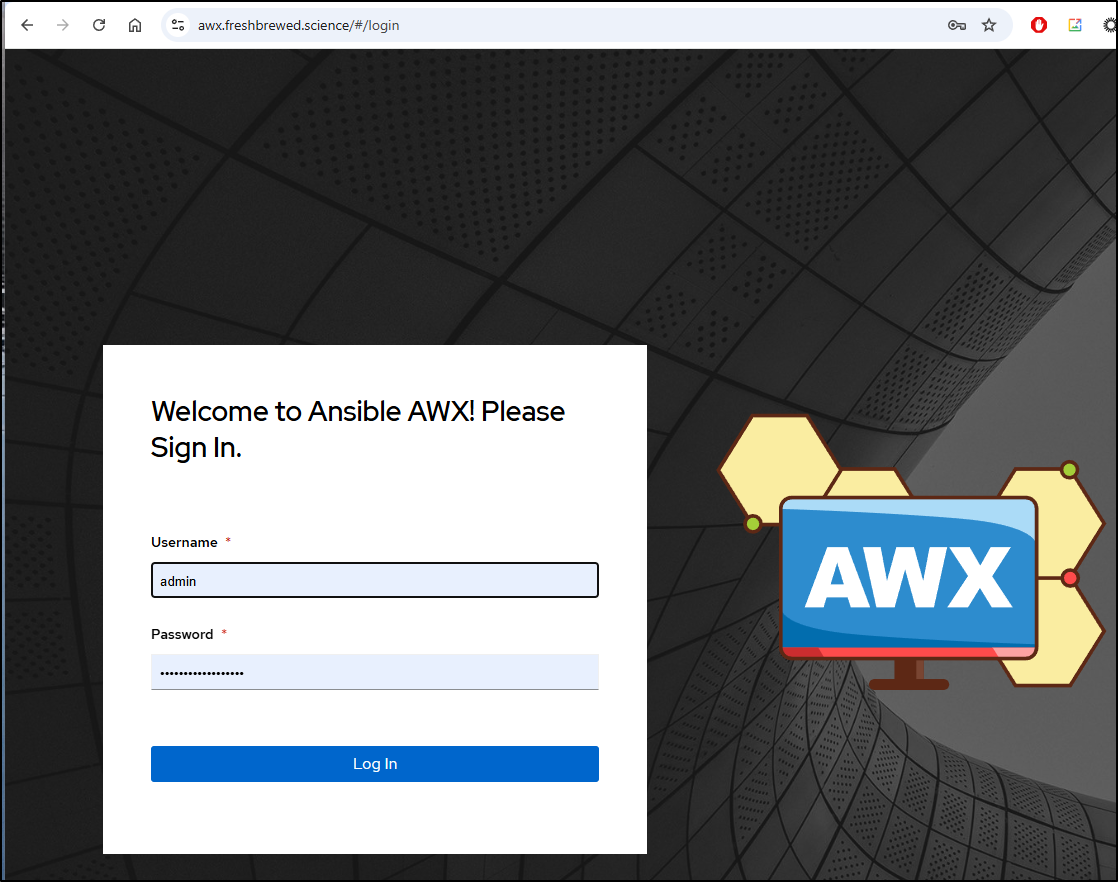
The database was showing up and healthy
$ kubectl logs adwerxawx-postgresql-0 -n adwerxawx
postgresql 10:55:32.94
postgresql 10:55:32.94 Welcome to the Bitnami postgresql container
postgresql 10:55:32.94 Subscribe to project updates by watching https://github.com/bitnami/bitnami-docker-postgresql
postgresql 10:55:32.95 Submit issues and feature requests at https://github.com/bitnami/bitnami-docker-postgresql/issues
postgresql 10:55:32.95
postgresql 10:55:33.02 INFO ==> ** Starting PostgreSQL setup **
postgresql 10:55:33.08 INFO ==> Validating settings in POSTGRESQL_* env vars..
postgresql 10:55:33.09 INFO ==> Loading custom pre-init scripts...
postgresql 10:55:33.12 INFO ==> Initializing PostgreSQL database...
postgresql 10:55:33.18 INFO ==> pg_hba.conf file not detected. Generating it...
postgresql 10:55:33.19 INFO ==> Generating local authentication configuration
postgresql 10:55:33.22 INFO ==> Deploying PostgreSQL with persisted data...
postgresql 10:55:33.33 INFO ==> Configuring replication parameters
postgresql 10:55:33.42 INFO ==> Configuring fsync
postgresql 10:55:33.44 INFO ==> Configuring synchronous_replication
postgresql 10:55:33.53 INFO ==> Loading custom scripts...
postgresql 10:55:33.55 INFO ==> Enabling remote connections
postgresql 10:55:33.59 INFO ==> ** PostgreSQL setup finished! **
postgresql 10:55:33.64 INFO ==> ** Starting PostgreSQL **
LOG: pgaudit extension initialized
LOG: database system was shut down at 2025-09-14 22:03:40 GMT
LOG: MultiXact member wraparound protections are now enabled
LOG: database system is ready to accept connections
LOG: autovacuum launcher started
But, for some reason, the App was stuck at 2/3 containers started and was failing to connect to PostgreSQL
$ kubectl logs adwerxawx-656f5f94b4-x6nsj -n adwerxawx
Defaulted container "task" out of: task, web, redis
Using /etc/ansible/ansible.cfg as config file
127.0.0.1 | FAILED! => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/libexec/platform-python"
},
"changed": false,
"elapsed": 301,
"msg": "Timeout when waiting for 10.42.1.153:5432"
}
Using /etc/ansible/ansible.cfg as config file
An exception occurred during task execution. To see the full traceback, use -vvv. The error was: TCP/IP connections on port 5432?
127.0.0.1 | FAILED! => {
"ansible_facts": {
"discovered_interpreter_python": "/usr/libexec/platform-python"
},
"changed": false,
"msg": "unable to connect to database: could not connect to server: No route to host\n\tIs the server running on host \"10.42.1.153\" and accepting\n\tTCP/IP connections on port 5432?\n"
}
It would seem that I must have used a PodIP or direct service IP at some point in the past (back when KubeDNS was being a pain).
I first tried the new IP for the Service
$ kubectl get svc -n adwerxawx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
adwerxawx ClusterIP 10.43.147.109 <none> 8080/TCP 83d
adwerxawx-postgresql ClusterIP 10.43.235.175 <none> 5432/TCP 561d
adwerxawx-postgresql-headless ClusterIP None <none> 5432/TCP 561d
which lives in the secrets as “DATABASE_HOST”
$ kubectl get secrets -n adwerxawx adwerxawx -o yaml
apiVersion: v1
data:
AWX_ADMIN_PASSWORD: xxxxxxxxx
AWX_ADMIN_USER: xxxxxxx
DATABASE_ADMIN_PASSWORD: xxxxxxxx
DATABASE_HOST: MTAuNDIuMS4xNTM=
DATABASE_NAME: YXd4
DATABASE_PASSWORD: xxxxxxxxx
DATABASE_PORT: NTQzMg==
DATABASE_USER: YXd4
SECRET_KEY: xxxxxxxxxxx
... snip ...
I got the new IP base64’ed
$ echo '10.43.235.175' | tr -d '\n' | base64
MTAuNDMuMjM1LjE3NQ==
and just pasted it in during an inline edit
$ kubectl edit secrets -n adwerxawx adwerxawx
secret/adwerxawx edited
I then rotated the pod
$ kubectl get po -n adwerxawx
NAME READY STATUS RESTARTS AGE
adwerxawx-656f5f94b4-x6nsj 2/3 Running 0 10m
... snip ...
$ kubectl delete po adwerxawx-656f5f94b4-x6nsj -n adwerxawx
pod "adwerxawx-656f5f94b4-x6nsj" deleted
And it came back up
Summary
Today - well, this morning to be precise - I dealt with the aftermath of an extended power outage. I still do not know the cause, but what I do know is that the incessant beeping of the APC units drives my family crazy and 5 hours is about the longest my largest battery backup will last.
I tackled the re-ip’ing of a fleet of physical laptops (with overlaps) to restore a k3s cluster, the fixing of firewall rules (to point 80/443 to the correct host) and lastly the sorting out of DNS records.
I hope that block catches some of the search engines because I should would have liked to find the bash to fix AWS, Azure and GCP in one fell swoop and the AIs are all generally wrong on the steps there.
One takeaway I had is that my workloads that live in Docker and are just fronted by NGinx+cert-manager did best. They just come right back up and if anything, I have to tweak my “Endpoints” in k8s to hit the updated IPs. That’s a lot easier than zombie pods and busted local-path PVCs. Something I’ll need to stew on for future production work.
As an aside, while I didn’t write about it above, my 2nd cluster (test cluster) with a stack of Macs (MacBook air as master and some old MacBook Pros as workers) came up without a hitch. Not sure if they just have better onboard batteries or more solid NICs.
Quick note: that photo is NOT AI generated. I took that near butterfly beach in Santa Barabara, CA around 2006 after a huge storm with my old Canon EOS Rebel T2.

