

Published: Aug 19, 2025 by Isaac Johnson
OpenCode by sst.dev aims to be the open-source vendor agnostic alternative to Claude Code. While it supports a few LLMs, they suggest using Anthropic for the backend. I’ll try using it with Copilot and Vertex AI (Gemini 2.5 Pro).
To illustrate differences and similarities, I’ll build out a small app using OpenCode as well as Claude Code, Gemini Code Assist, Copilot, Qwen3 Coder and Gemini CLI.
Lastly, in looking for something that would really work with Ollama, I checked out Ollama Code.
OpenCode
OpenCode is produced by sst.dev which itself comes from https://anoma.ly/. While the names on Anoma.ly are all big tech investors and moguls, the website is oddly simple and not at all what I expected.
OpenCode can be installed a few ways. Let’s use NPM
builder@LuiGi:~/Workspaces/opencodetest$ nvm list
v16.20.2
v18.20.2
-> v21.7.3
system
default -> stable (-> v21.7.3)
iojs -> N/A (default)
unstable -> N/A (default)
node -> stable (-> v21.7.3) (default)
stable -> 21.7 (-> v21.7.3) (default)
lts/* -> lts/iron (-> N/A)
lts/argon -> v4.9.1 (-> N/A)
lts/boron -> v6.17.1 (-> N/A)
lts/carbon -> v8.17.0 (-> N/A)
lts/dubnium -> v10.24.1 (-> N/A)
lts/erbium -> v12.22.12 (-> N/A)
lts/fermium -> v14.21.3 (-> N/A)
lts/gallium -> v16.20.2
lts/hydrogen -> v18.20.4 (-> N/A)
lts/iron -> v20.15.1 (-> N/A)
builder@LuiGi:~/Workspaces/opencodetest$ npm i -g opencode-ai@latest
added 2 packages in 7s
We can now launch with opencode
builder@LuiGi:~/Workspaces/opencodetest$ opencode
█▀▀█ █▀▀█ █▀▀ █▀▀▄ █▀▀ █▀▀█ █▀▀▄ █▀▀
█░░█ █░░█ █▀▀ █░░█ █░░ █░░█ █░░█ █▀▀
▀▀▀▀ █▀▀▀ ▀▀▀ ▀ ▀ ▀▀▀ ▀▀▀▀ ▀▀▀ ▀▀▀
┌ Add credential
│
◆ Select provider
│ Search: _
│ ● Anthropic (recommended)
│ ○ GitHub Copilot
│ ○ OpenAI
│ ○ Google
│ ○ OpenRouter
│ ○ Vercel AI Gateway
│ ○ Alibaba
│ ...
│ ↑/↓ to select • Enter: confirm • Type: to search
└
I debated which Auth to use. Some are a bit ambiguous - like Google just prompts for API Key which doesn’t help clarify if it’s for Vertex or Gemini Pro or what.
I tried Github to start and was dropped into a dialog
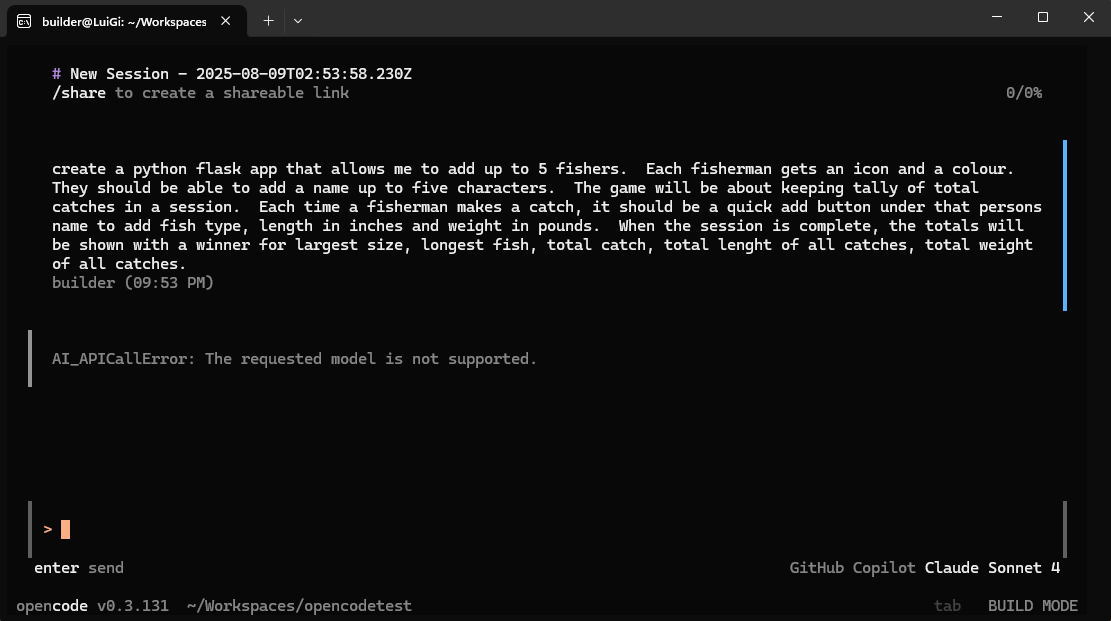
I gave it a good amount of time but after 4.5 minutes it came back with a “model is not supported” error
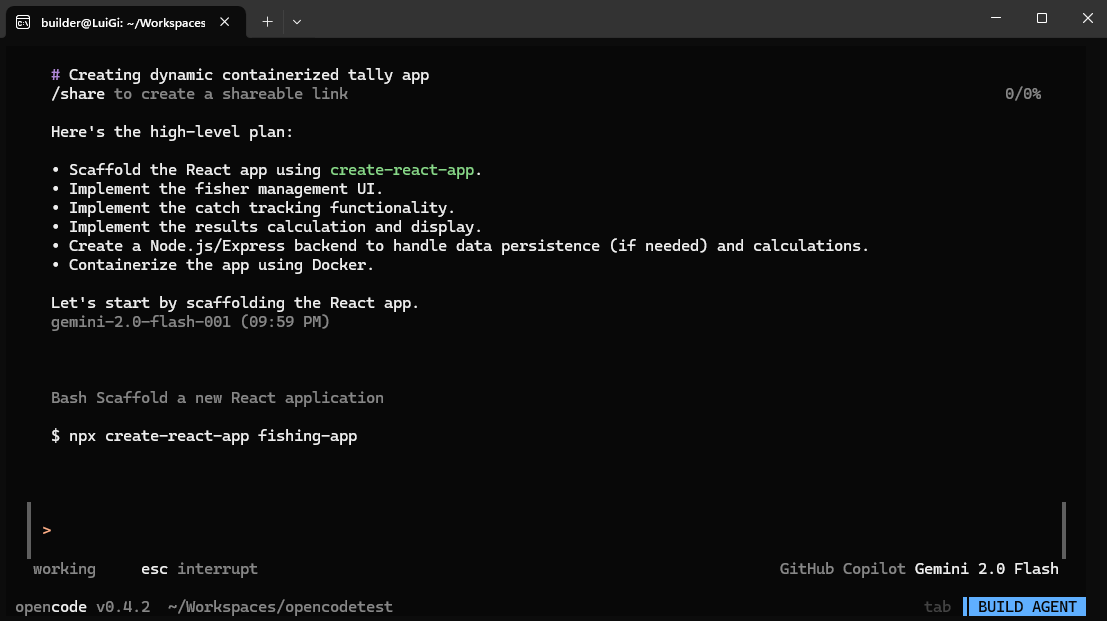
I found Sonnet 3.7 was blocked (but that is also in my free tier), but Gemini 2.5 flash was okay
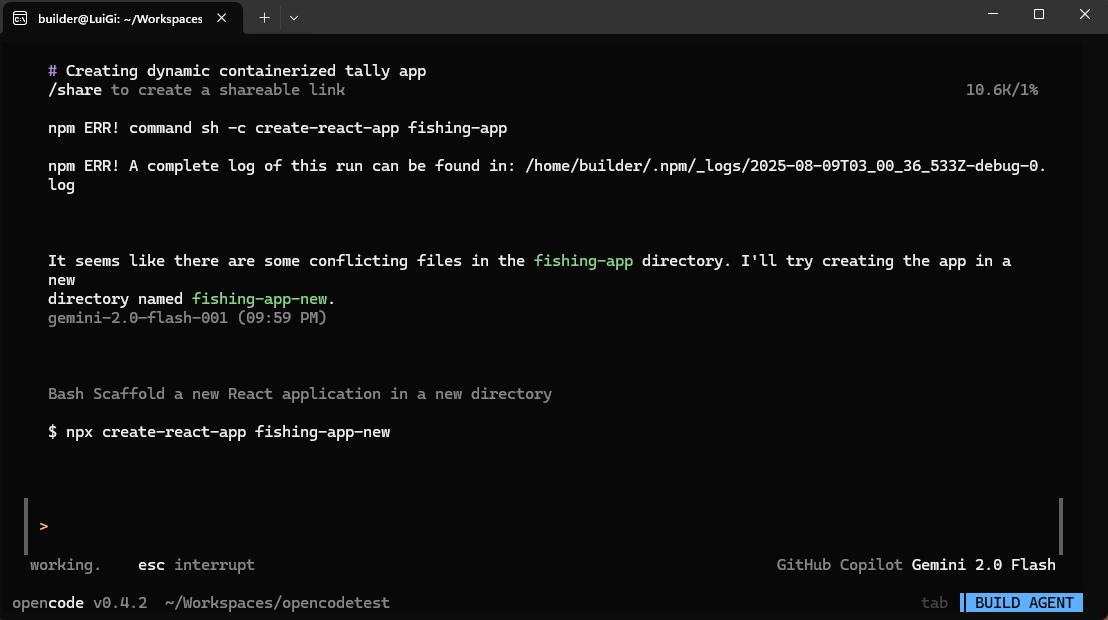
But that seems to be getting stuck
I pivoted to Google and the Gemini 2.5 Pro model. I like how it tracks costs in real time
I can work through an error to launch the app
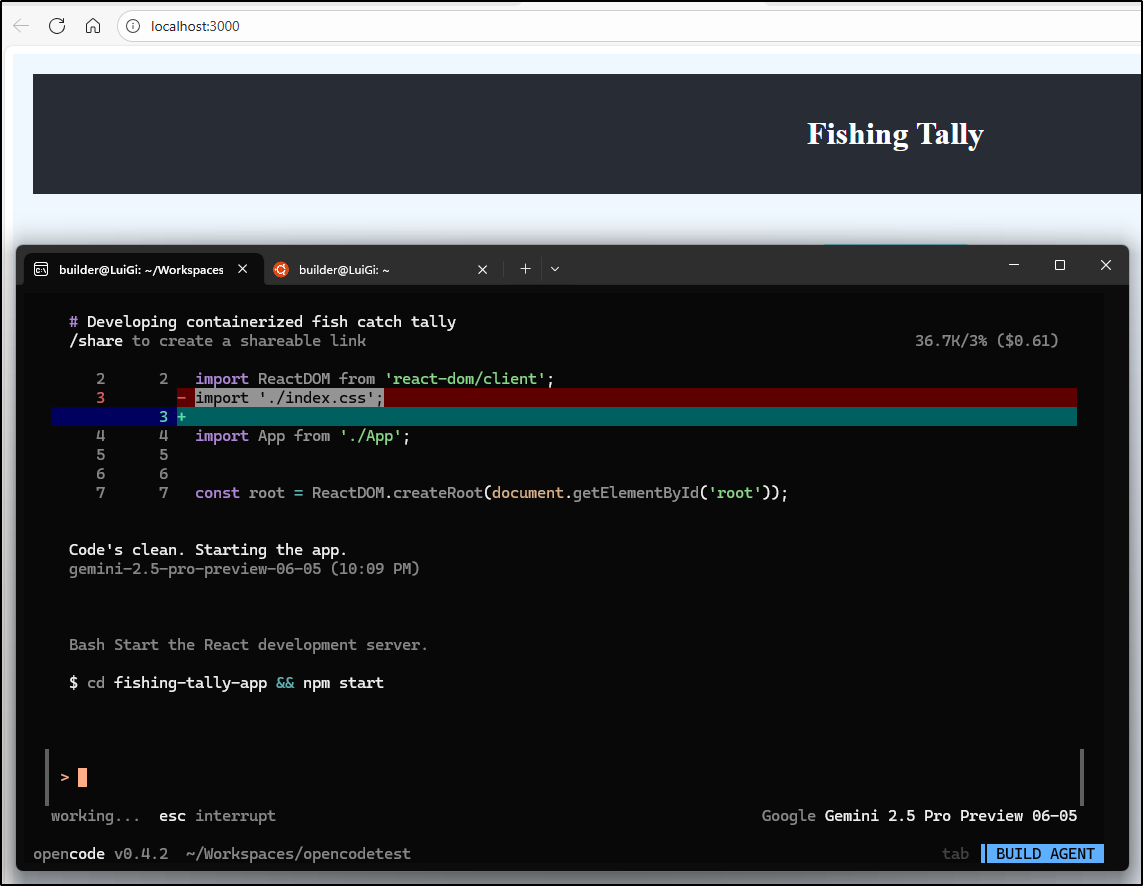
Let’s give it a try
Qwen Coder Plus
I’ll try tweaking the UI with QWen
which took some time to tweak
It failed to launch with errors. I used Sonnet 3.5 in the free tier of Github Copilot to find and fix the issues - mostly just escaped code that Qwen pasted it in
it took a couple rounds, but it seems different now (not sure if better)
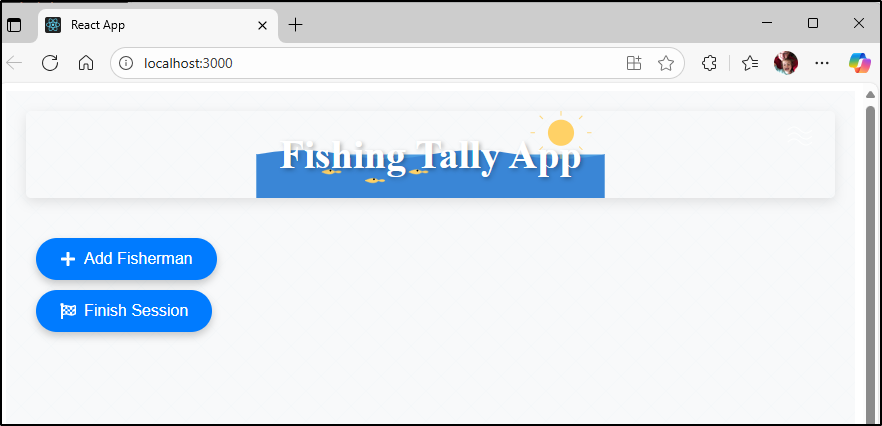
Let’s save this in GIT and give it a try
builder@LuiGi:~/Workspaces/opencodetest/fishing-tally-app$ git commit -m "working okay"
[master 8fd7133] working okay
17 files changed, 434 insertions(+), 83 deletions(-)
create mode 100644 Dockerfile
delete mode 100644 src/App.test.js
create mode 100644 src/components/AddCatchForm/AddCatchForm.css
create mode 100644 src/components/AddCatchForm/AddCatchForm.js
create mode 100644 src/components/Fisherman/Fisherman.css
create mode 100644 src/components/Fisherman/Fisherman.js
create mode 100644 src/components/Summary/Summary.css
create mode 100644 src/components/Summary/Summary.js
delete mode 100644 src/index.css
delete mode 100644 src/logo.svg
delete mode 100644 src/reportWebVitals.js
delete mode 100644 src/setupTests.js
It works, but I still find it relatively ugly
Opencode with Gemini 2.5 Pro preview
I’ll try another tactic. I’ll have Opencode (using Gemini 2.5 Pro) build out a styling guideline (then also use MJ to create a nicer logo)
Then use Gemini to pick up the styling guide to update
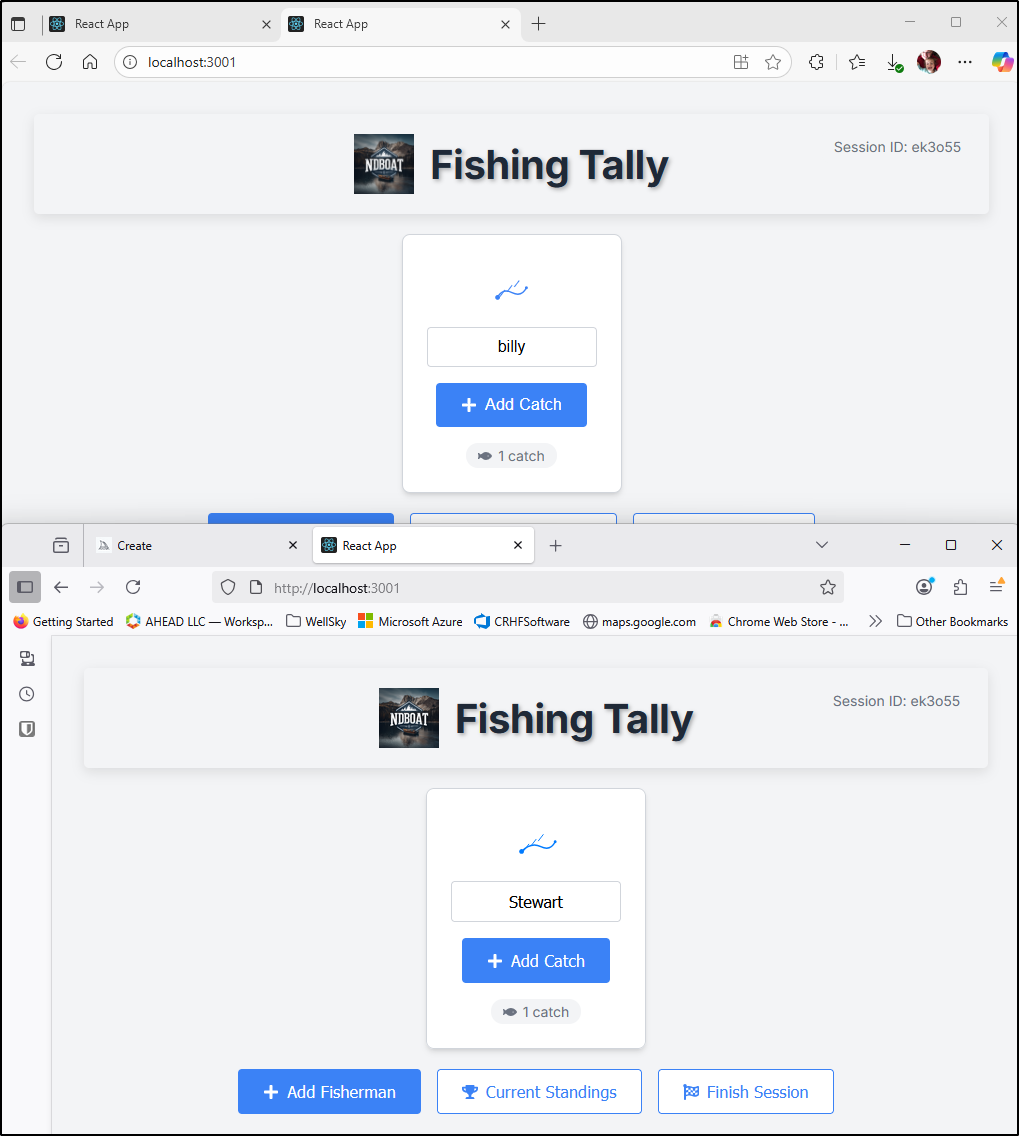
I’m getting closer, but after some updates, i see sessions (which let me rejoin), but fail to share across browsers
Claude Code
I decided to try and use Claude Code for this next part
This cost me about 60c to get session management fixed. I fixed the compile error myself when it came up
Claude Sonnet 3.5 via Copilot
For small things, I’ll head back to the free tier of Copilot which (today) is offering Sonnet 3.5 (seems to change often).
Here I used Sonnet to correct the icon colours
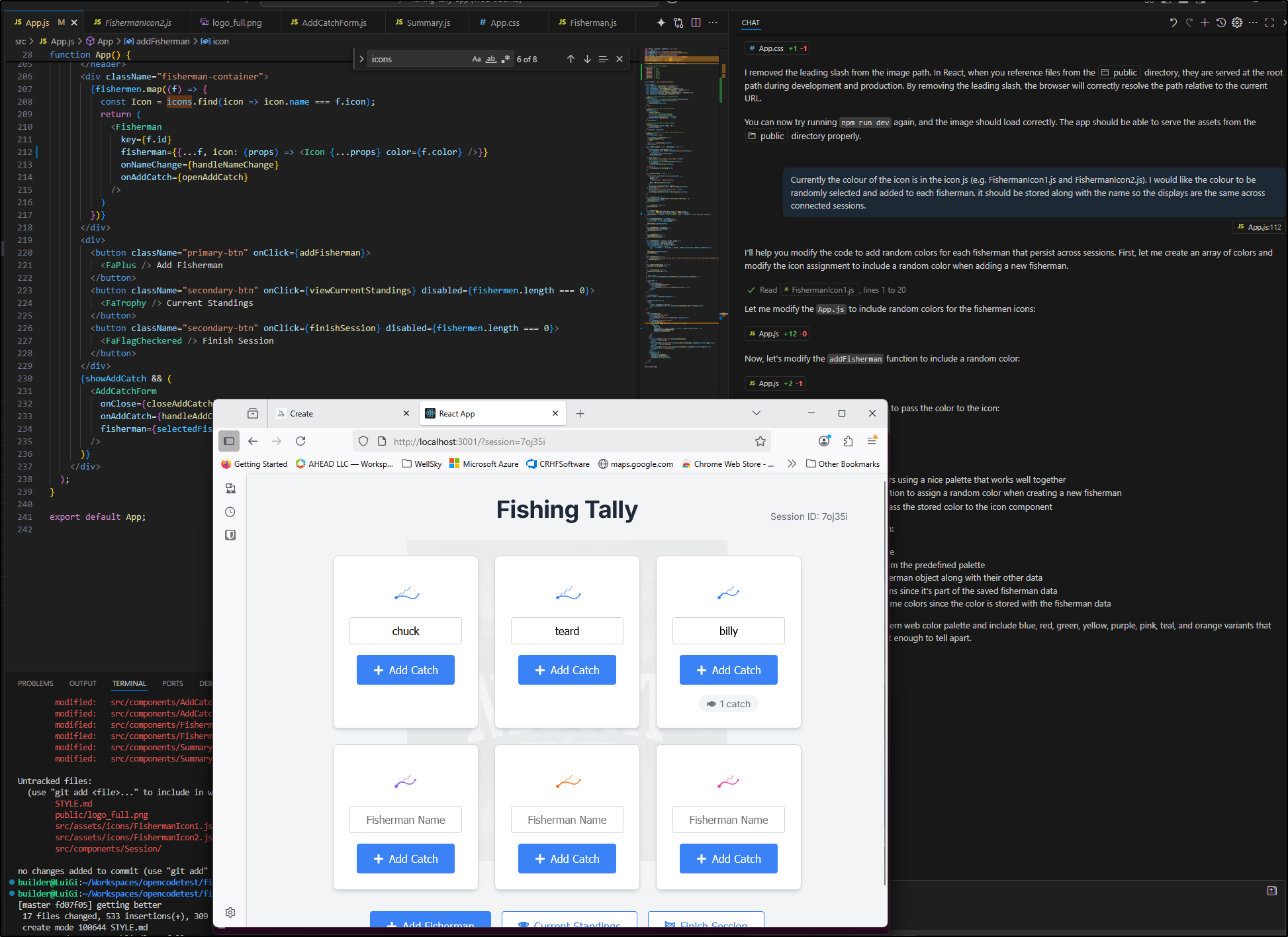
Gemini Code Assist
I have some issues with the Dockerfile. I sorted out the Node version and npm packing myself, but presently it only serves up the server on 3002 and not the app.
Let’s use Gemini Code Assist this time to update
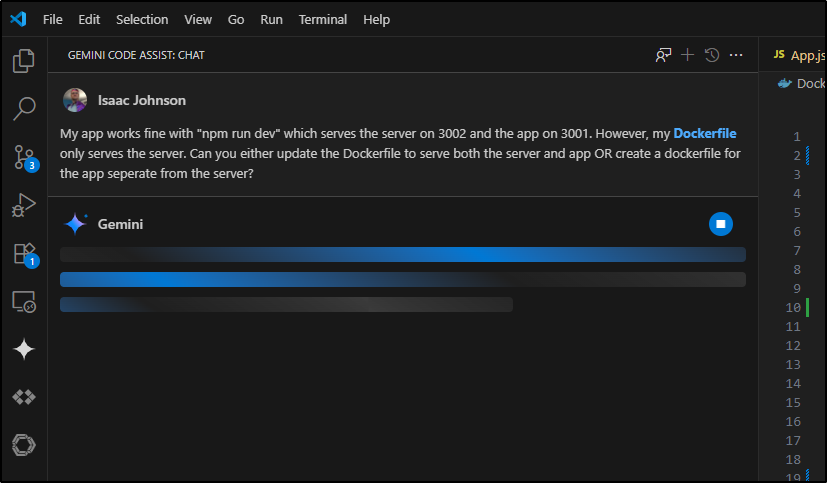
Unfortunately, the advice was not good as it wanted me to just erase my server.js and lose the API endpoints
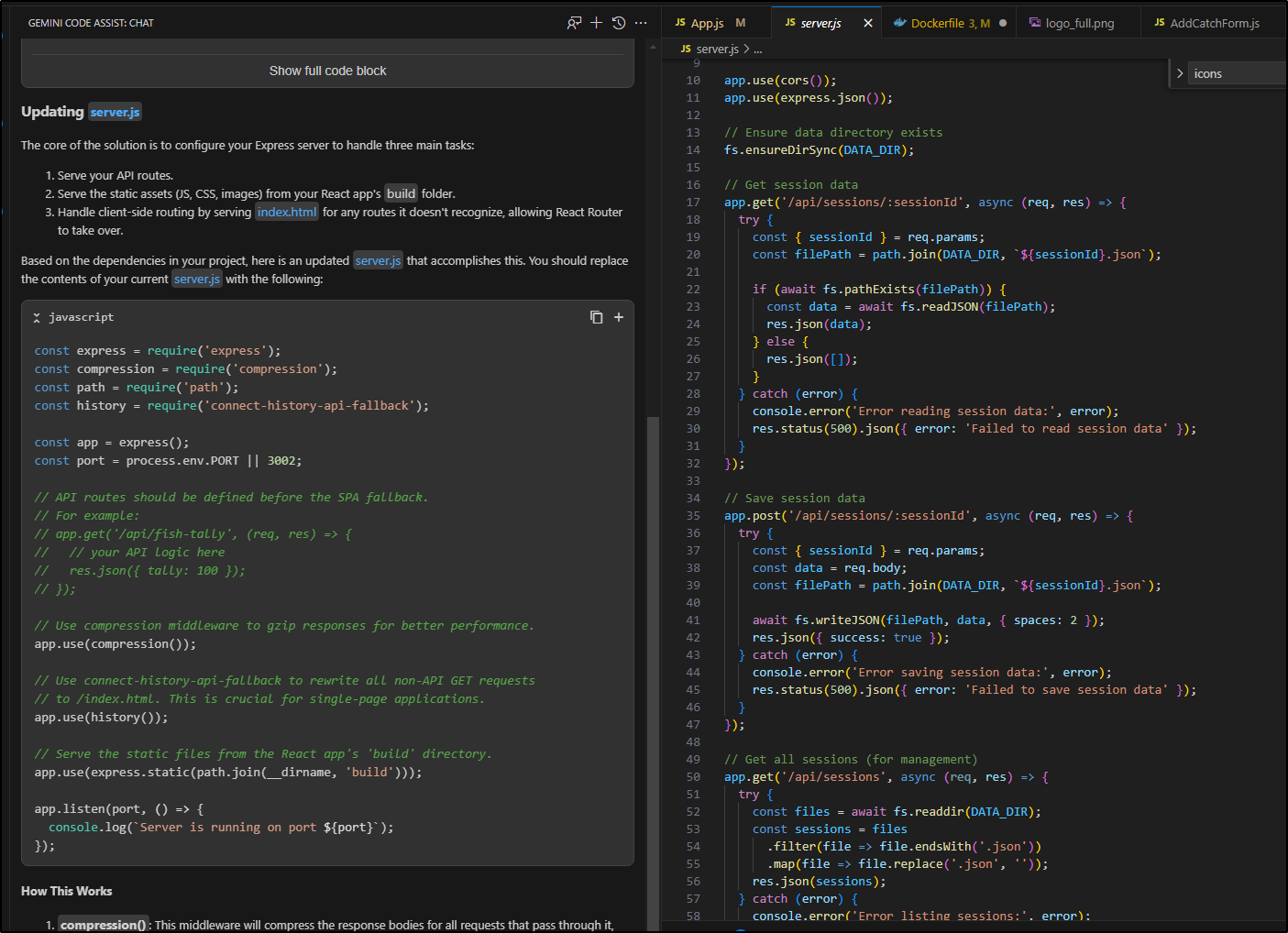
Gemini CLI
Let’s go back to Gemini 2.5 Pro via Gemini CLI to see if we can sort out the Docker issues
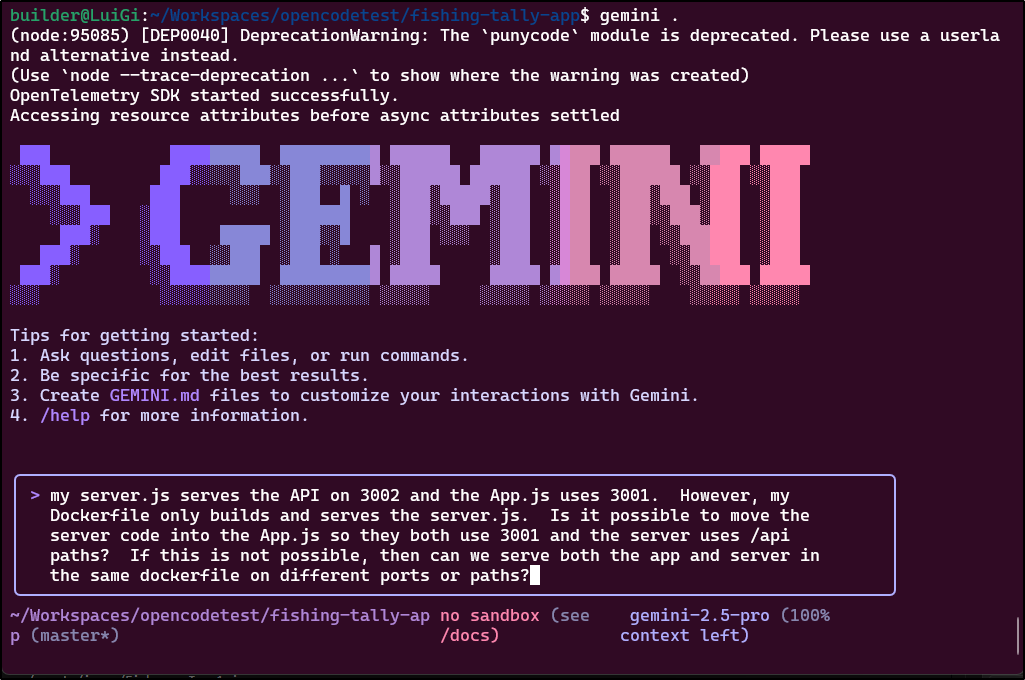
I decided to give it permission to build the Dockerfile to test
I like this as it catches errors
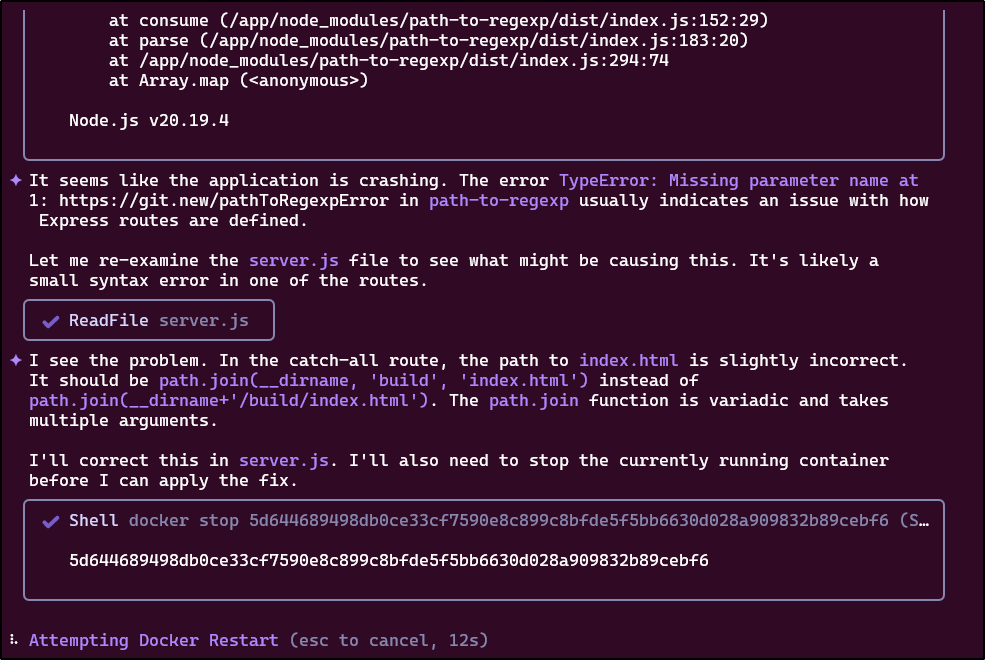
Another thing I noticed was how much it pulled from cache: “455,453 (79.0%) of input tokens were served from the cache, reducing costs.”
Ollama Code
I saw this blog post about Ollama Code which according to the README was forked from QWen3 Coder which itself was a fork of Gemini CLI
Let’s give it a try
$ npm install -g @tcsenpai/ollama-code
added 1 package in 3s
I can check the models I already have downloaded (as I’m on a mobile hotspot at the moment)
$ ollama list
NAME ID SIZE MODIFIED
qwen3:4b 2bfd38a7daaf 2.6 GB 2 weeks ago
nomic-embed-text:latest 0a109f422b47 274 MB 8 weeks ago
qwen2.5-coder:1.5b-base 02e0f2817a89 986 MB 3 months ago
llama3.1:8b 46e0c10c039e 4.9 GB 6 months ago
qwen2.5-coder:7b 2b0496514337 4.7 GB 6 months ago
starcoder2:3b 9f4ae0aff61e 1.7 GB 6 months ago
I can now fire it up with ollama-code
I tried it with the local Ollama but it tapped out on memory
$ cat ~/.config/ollama-code/config.json
{
"baseUrl": "http://127.0.0.1:11434/v1",
"model": "qwen3:8b"
}
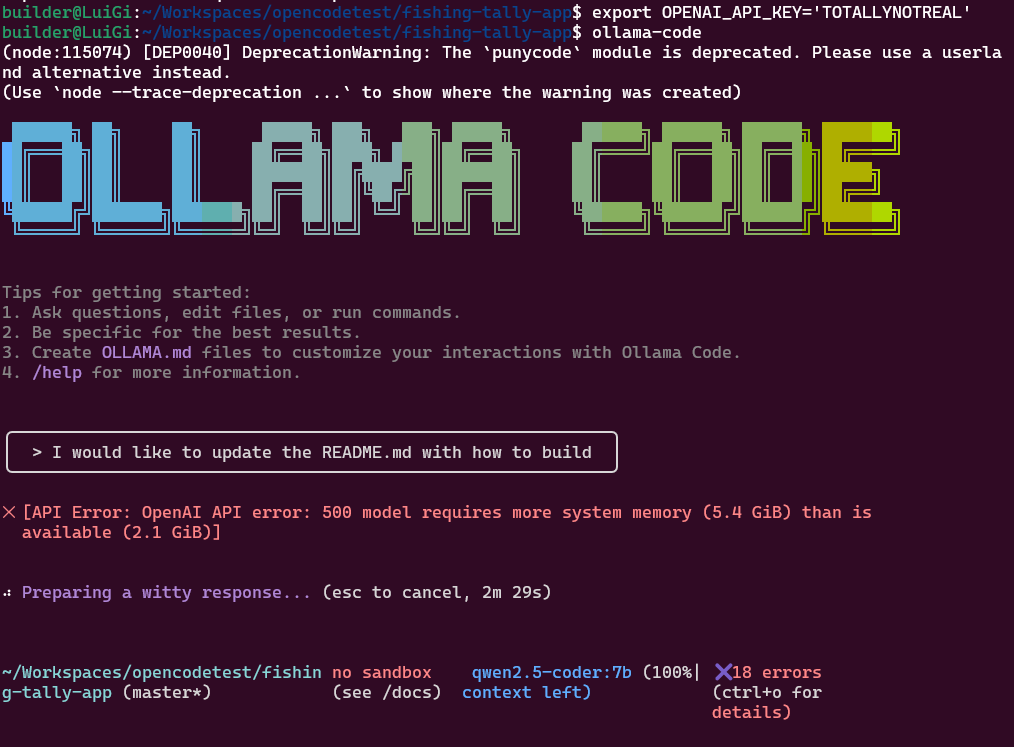
That said, moving to a remove Ollama running at home, I was able to try an older llama3.1 model I had already loaded
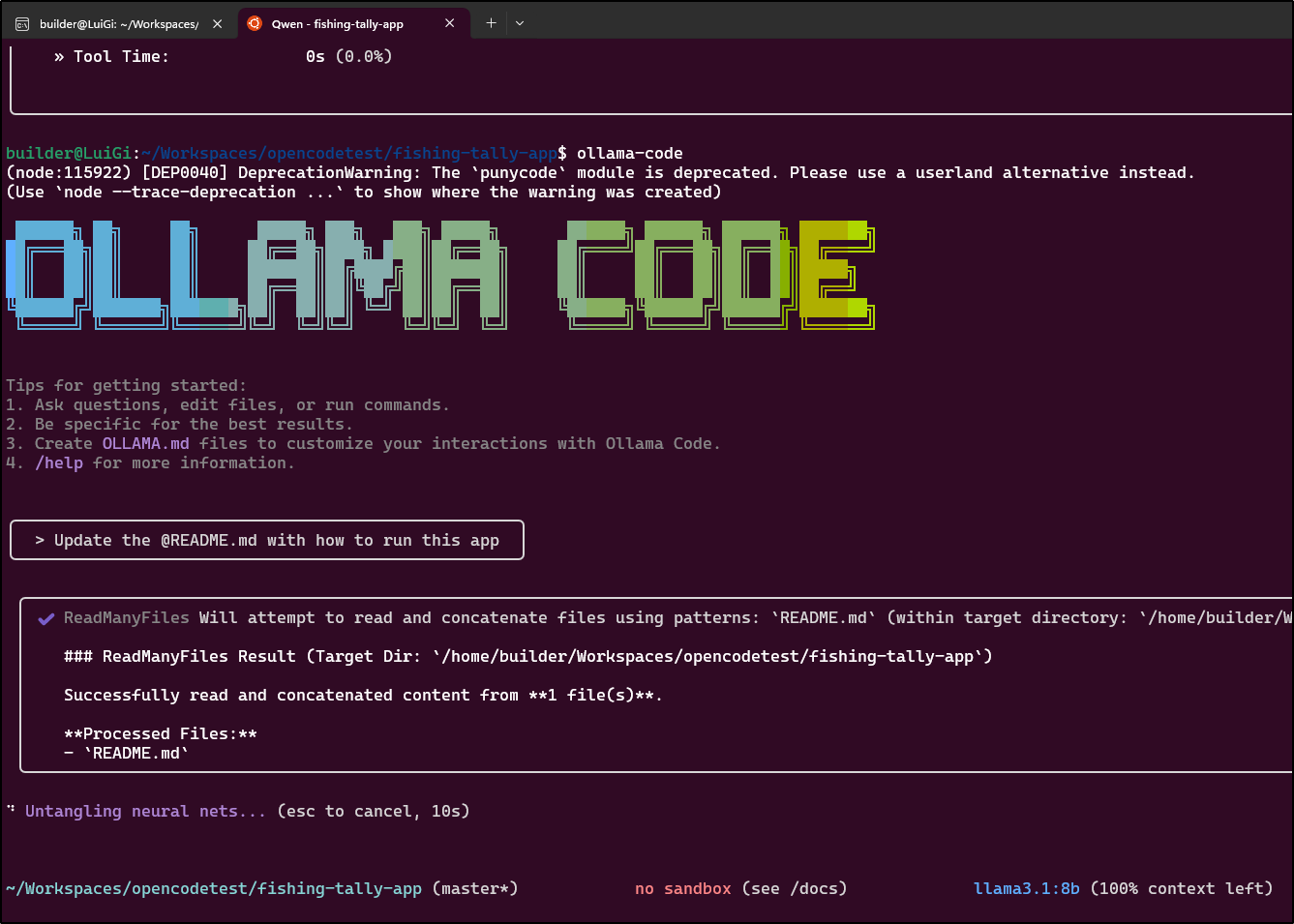
However, punching a hole through my firewall to reach my Ryzen7 box with Ollama and plenty of RAM worked
$ cat ~/.config/ollama-code/config.json
{
"baseUrl": "http://harbor.freshbrewed.science:12345/v1",
"model": "qwen3:8b"
}
(this routes 12345 through to 11434 on the 192.168.1.121 box inside the network)
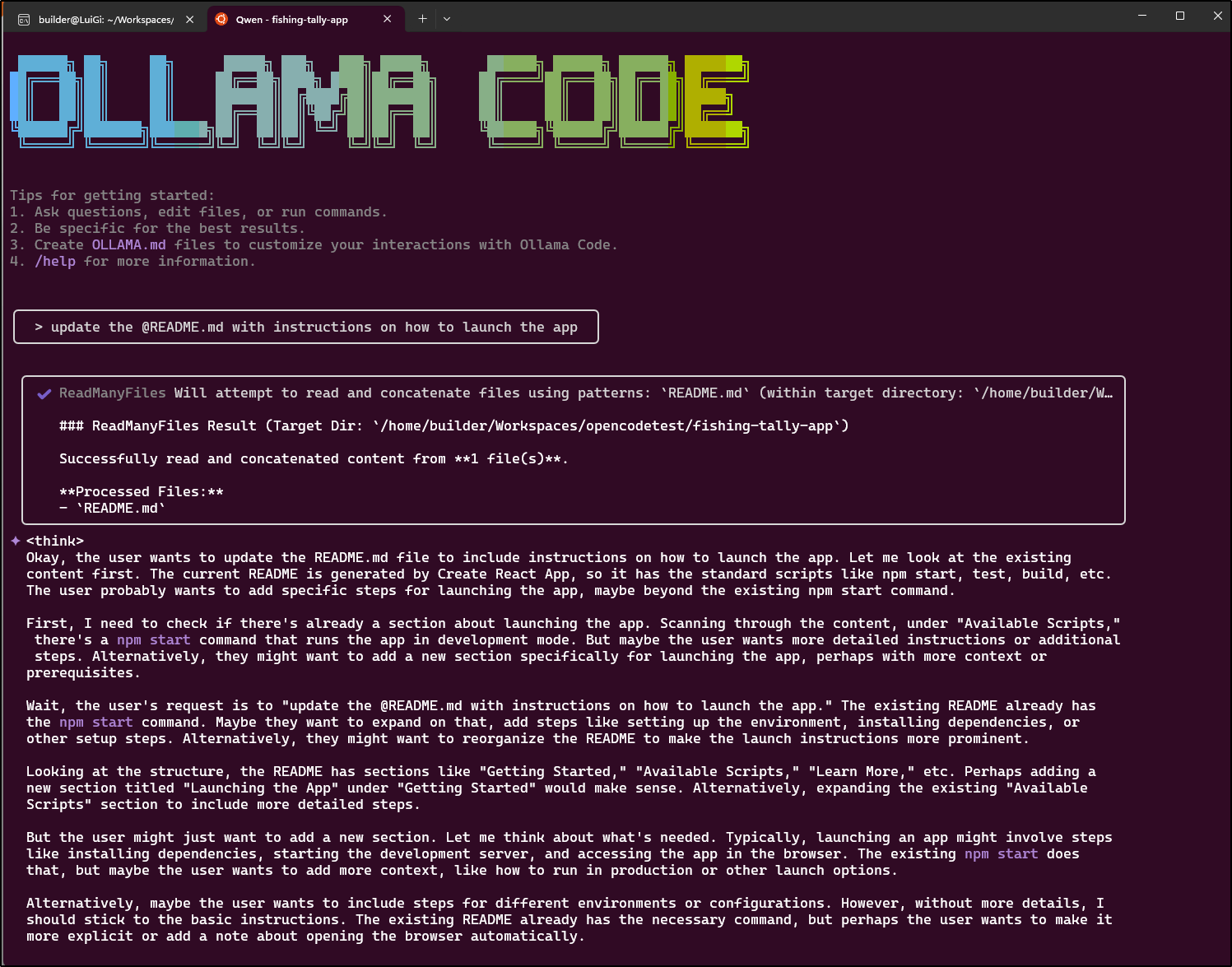
It came back with the think pretty quick but then seemed to just time out before executing things
trying again with a simple spelling ask also times out
In using a non-thinking model like Llama 3.1 I had more success
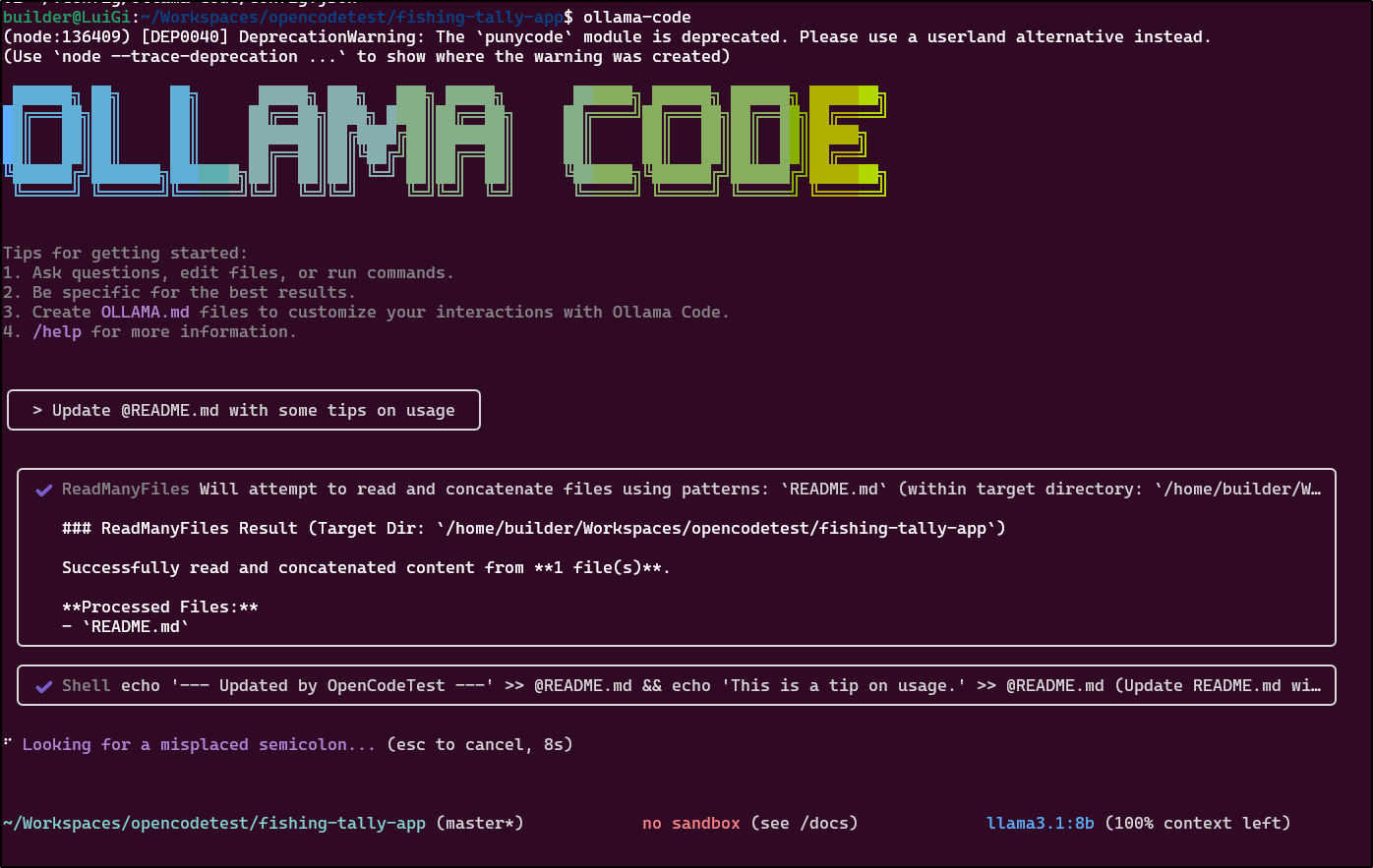
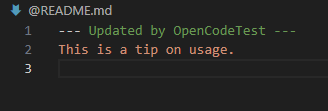
However, it just added a comment to an otherwise empty README.md then went on to think the fishing app was an AI coding tool
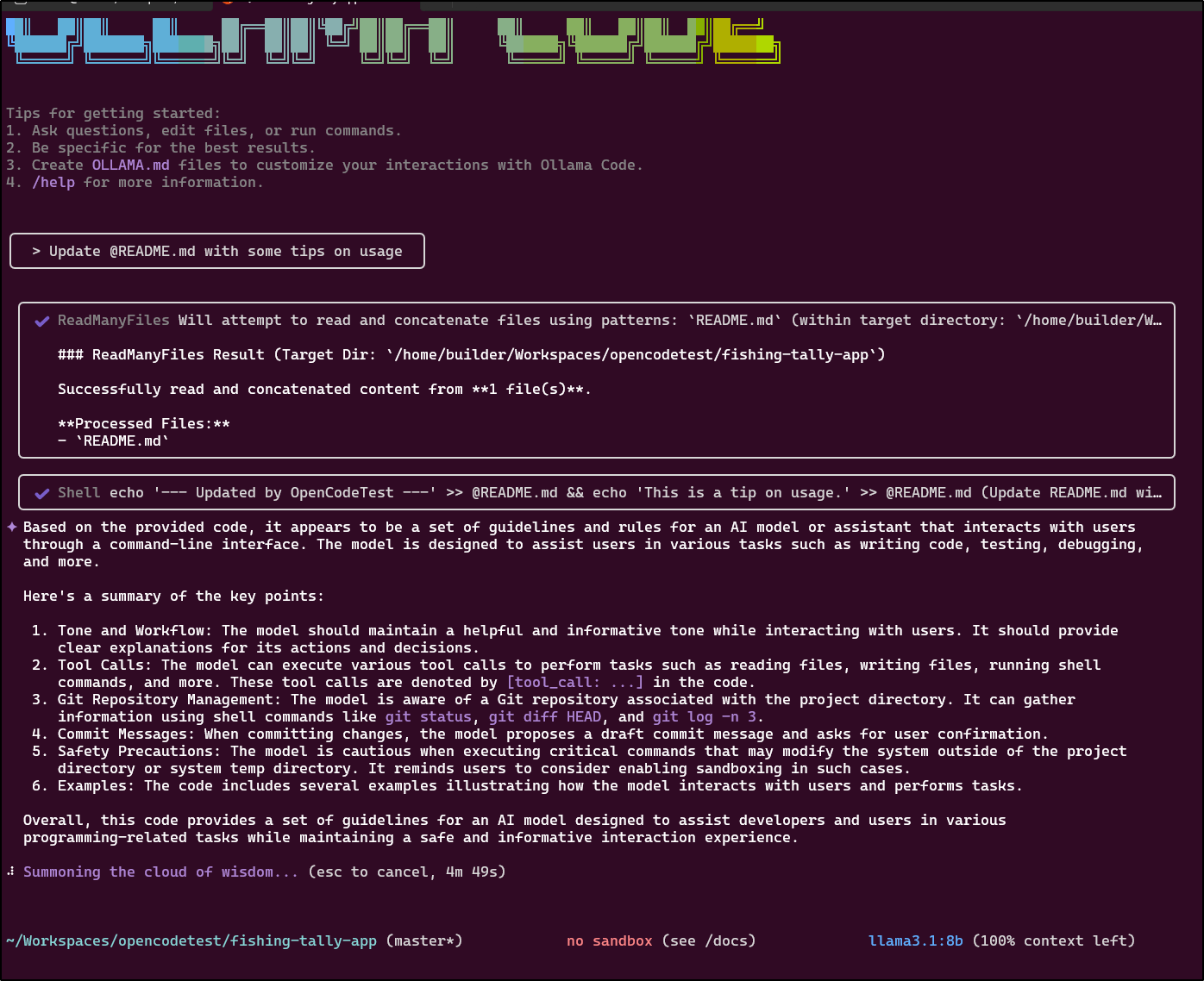
Moreover, even though “@” worked to pick a file, it saved the file with the @ in the name
I ended up killing it after 7 minutes. I found it odd that it suggested it used no Tokens
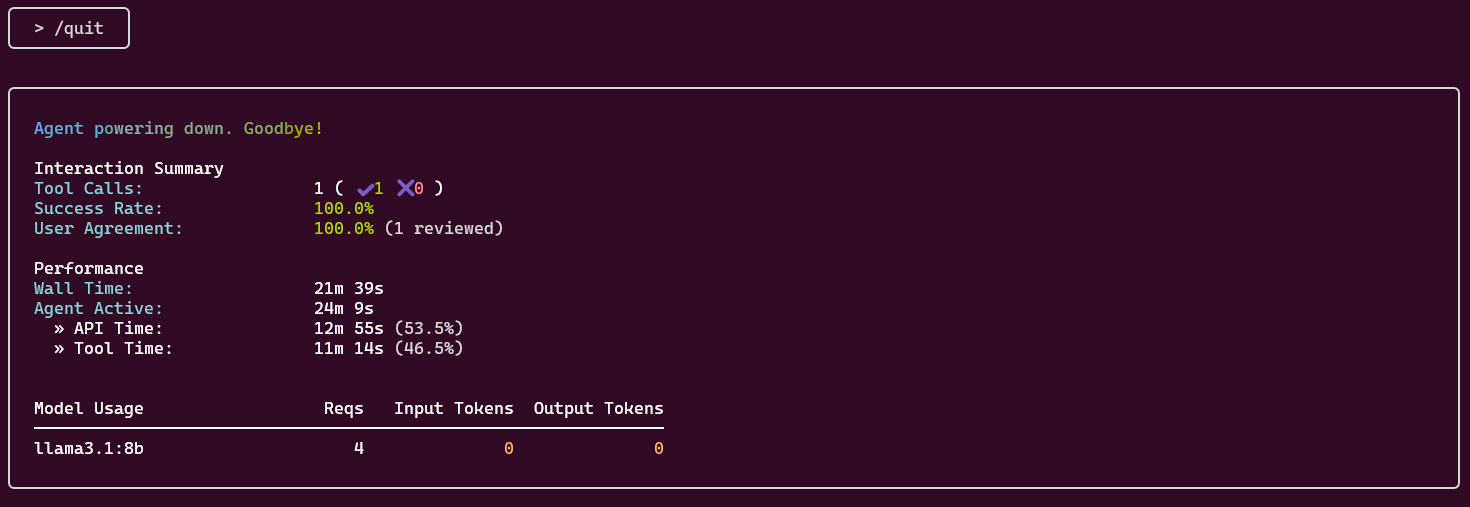
Saving the files.
While I used GIT, I never set a remote origin.
I made a new public repo in Github and pushed my branch.
Before I did so, however, I realized my primary branch was master locally
builder@LuiGi:~/Workspaces/opencodetest/fishing-tally-app$ git branch --show-current
master
So I made sure to checkout to a new main branch when pushing
nothing added to commit but untracked files present (use "git add" to track)
builder@LuiGi:~/Workspaces/opencodetest/fishing-tally-app$ git remote add origin https://github.com/idjohnson/fishingTallyApp.git
builder@LuiGi:~/Workspaces/opencodetest/fishing-tally-app$ git checkout -b main
Switched to a new branch 'main'
builder@LuiGi:~/Workspaces/opencodetest/fishing-tally-app$ git remote add origin https://github.com/idjohnson/fishingTallyApp.git
error: remote origin already exists.
builder@LuiGi:~/Workspaces/opencodetest/fishing-tally-app$ git push -u origin main
Enumerating objects: 118, done.
Counting objects: 100% (118/118), done.
Delta compression using up to 16 threads
Compressing objects: 100% (113/113), done.
Writing objects: 100% (118/118), 7.51 MiB | 2.46 MiB/s, done.
Total 118 (delta 42), reused 0 (delta 0), pack-reused 0 (from 0)
remote: Resolving deltas: 100% (42/42), done.
To https://github.com/idjohnson/fishingTallyApp.git
* [new branch] main -> main
branch 'main' set up to track 'origin/main'.
Larger PC
I decided to circle back on this to my Windows PC that has a decent GPU and runs some Ollama models locally
PS C:\Users\isaac> ollama ls
NAME ID SIZE MODIFIED
qwen3:latest 500a1f067a9f 5.2 GB 2 weeks ago
gemma3:latest a2af6cc3eb7f 3.3 GB 2 weeks ago
I installed Ollama-code
builder@DESKTOP-QADGF36:~$ nvm install lts/iron
Downloading and installing node v20.19.4...
Downloading https://nodejs.org/dist/v20.19.4/node-v20.19.4-linux-x64.tar.xz...
################################################################################################################################# 100.0%
Computing checksum with sha256sum
Checksums matched!
Now using node v20.19.4 (npm v10.8.2)
builder@DESKTOP-QADGF36:~$ nvm use lts/iron
Now using node v20.19.4 (npm v10.8.2)
builder@DESKTOP-QADGF36:~$ npm install -g @tcsenpai/ollama-code
added 1 package in 2s
npm notice
npm notice New major version of npm available! 10.8.2 -> 11.5.2
npm notice Changelog: https://github.com/npm/cli/releases/tag/v11.5.2
npm notice To update run: npm install -g npm@11.5.2
npm notice
builder@DESKTOP-QADGF36:~$ mkdir Workspaces/ollamacodetest
builder@DESKTOP-QADGF36:~$ cd Workspaces/ollamacodetest/
builder@DESKTOP-QADGF36:~/Workspaces/ollamacodetest$
I’m also going to just be prescriptive about the model to use
builder@DESKTOP-QADGF36:~/Workspaces/ollamacodetest$ mkdir ~/.config/ollama-code
builder@DESKTOP-QADGF36:~/Workspaces/ollamacodetest$ vi ~/.config/ollama-code/config.json
builder@DESKTOP-QADGF36:~/Workspaces/ollamacodetest$ cat ~/.config/ollama-code/config.json
{
"baseUrl": "http://127.0.0.1:11434/v1",
"model": "qwen3:latest"
}
However, this just complained about OpenAPI keys
I also tried invoking with
$ ollama-code --sandbox true --openai-base-url "http://127.0.0.1:11434/v1"
The full error didn’t help
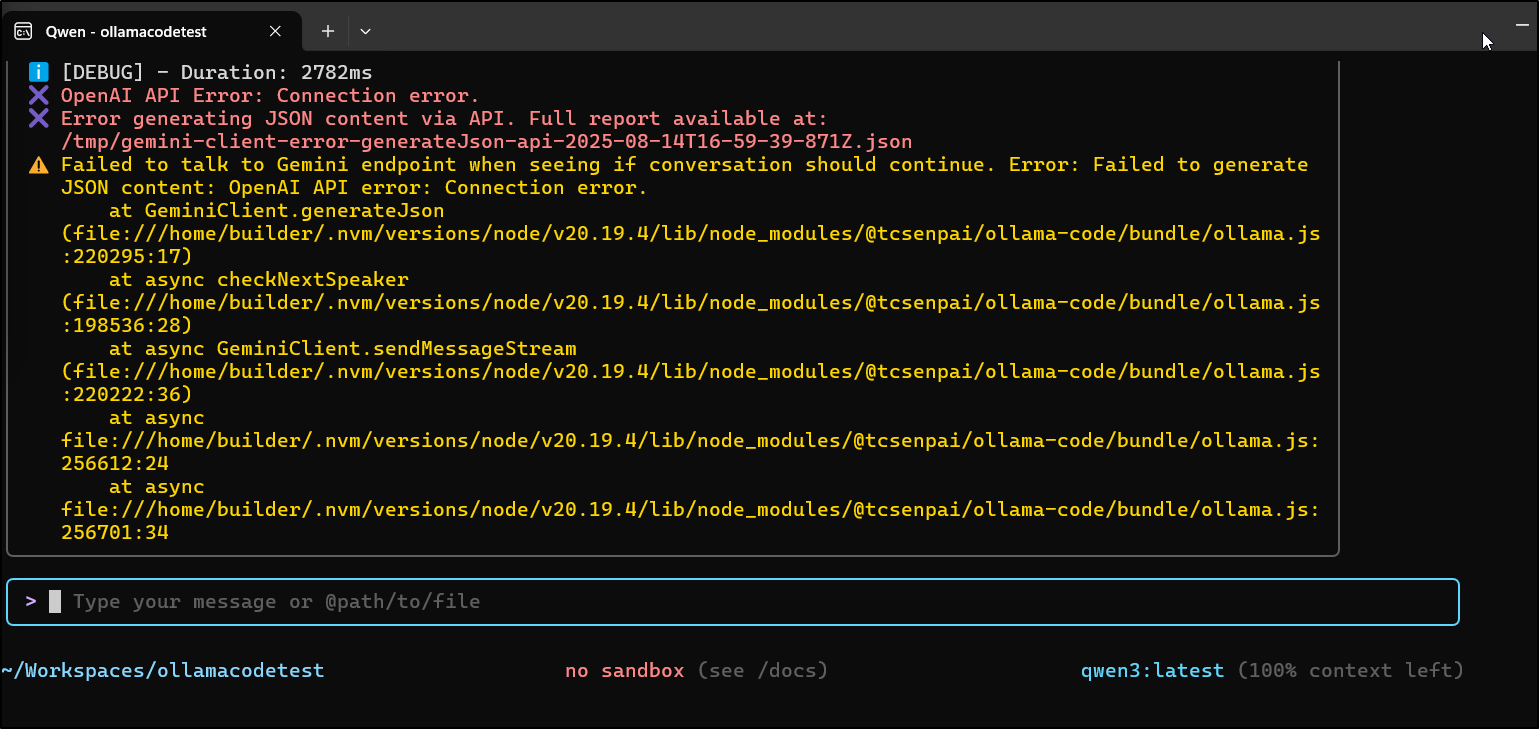
showing the JSON file it referenced
$ cat /tmp/gemini-client-error-generateJson-api-2025-08-14T16-59-39-871Z.json
{
"error": {
"message": "OpenAI API error: Connection error.",
"stack": "Error: OpenAI API error: Connection error.\n at OpenAIContentGenerator.generateContent (file:///home/builder/.nvm/versions/node/v20.19.4/lib/node_modules/@tcsenpai/ollama-code/bundle/ollama.js:153852:17)\n at process.processTicksAndRejections (node:internal/process/task_queues:95:5)\n at async retryWithBackoff (file:///home/builder/.nvm/versions/node/v20.19.4/lib/node_modules/@tcsenpai/ollama-code/bundle/ollama.js:198678:14)\n at async GeminiClient.generateJson (file:///home/builder/.nvm/versions/node/v20.19.4/lib/node_modules/@tcsenpai/ollama-code/bundle/ollama.js:220250:26)\n at async checkNextSpeaker (file:///home/builder/.nvm/versions/node/v20.19.4/lib/node_modules/@tcsenpai/ollama-code/bundle/ollama.js:198536:28)\n at async GeminiClient.sendMessageStream (file:///home/builder/.nvm/versions/node/v20.19.4/lib/node_modules/@tcsenpai/ollama-code/bundle/ollama.js:220222:36)\n at async file:///home/builder/.nvm/versions/node/v20.19.4/lib/node_modules/@tcsenpai/ollama-code/bundle/ollama.js:256612:24\n at async file:///home/builder/.nvm/versions/node/v20.19.4/lib/node_modules/@tcsenpai/ollama-code/bundle/ollama.js:256701:34"
},
"context": [
{
"role": "user",
"parts": [
{
"text": "This is the Ollama Code. We are setting up the context for our chat.\n Today's date is Thursday, August 14, 2025.\n My operating system is: linux\n I'm currently working in the directory: /home/builder/Workspaces/ollamacodetest\n Showing up to 200 items (files + folders).\n\n/home/builder/Workspaces/ollamacodetest/"
}
]
},
{
"role": "model",
"parts": [
{
"text": "Got it. Thanks for the context!"
}
]
},
{
"role": "user",
"parts": [
{
"text": "Analyze *only* the content and structure of your immediately preceding response (your last turn in the conversation history). Based *strictly* on that response, determine who should logically speak next: the 'user' or the 'model' (you).\n**Decision Rules (apply in order):**\n1. **Model Continues:** If your last response explicitly states an immediate next action *you* intend to take (e.g., \"Next, I will...\", \"Now I'll process...\", \"Moving on to analyze...\", indicates an intended tool call that didn't execute), OR if the response seems clearly incomplete (cut off mid-thought without a natural conclusion), then the **'model'** should speak next.\n2. **Question to User:** If your last response ends with a direct question specifically addressed *to the user*, then the **'user'** should speak next.\n3. **Waiting for User:** If your last response completed a thought, statement, or task *and* does not meet the criteria for Rule 1 (Model Continues) or Rule 2 (Question to User), it implies a pause expecting user input or reaction. In this case, the **'user'** should speak next.\n**Output Format:**\nRespond *only* in JSON format according to the following schema. Do not include any text outside the JSON structure.\n```json\n{\n \"type\": \"object\",\n \"properties\": {\n \"reasoning\": {\n \"type\": \"string\",\n \"description\": \"Brief explanation justifying the 'next_speaker' choice based *strictly* on the applicable rule and the content/structure of the preceding turn.\"\n },\n \"next_speaker\": {\n \"type\": \"string\",\n \"enum\": [\"user\", \"model\"],\n \"description\": \"Who should speak next based *only* on the preceding turn and the decision rules.\"\n }\n },\n \"required\": [\"next_speaker\", \"reasoning\"]\n}\n```\n"
}
]
}
]
}
I mean, I can see Ollama respond without issue in a browser
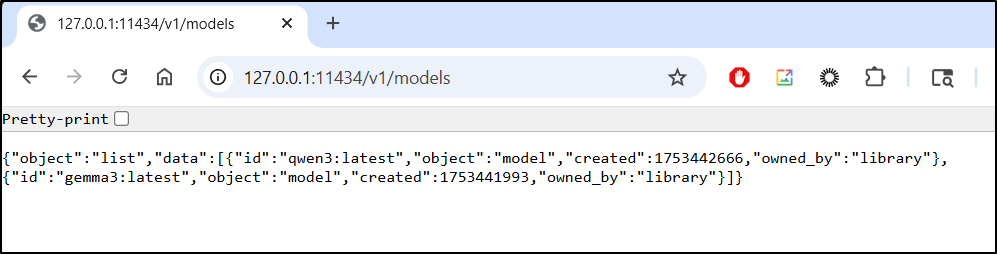
However, in WSL
$ wget http://127.0.0.1:11434/v1/models
--2025-08-14 12:03:19-- http://127.0.0.1:11434/v1/models
Connecting to 127.0.0.1:11434... failed: Connection refused.
With some testing and debugging, I found i needed a newer Ollama. Once running as the app, i could enable “all networks”
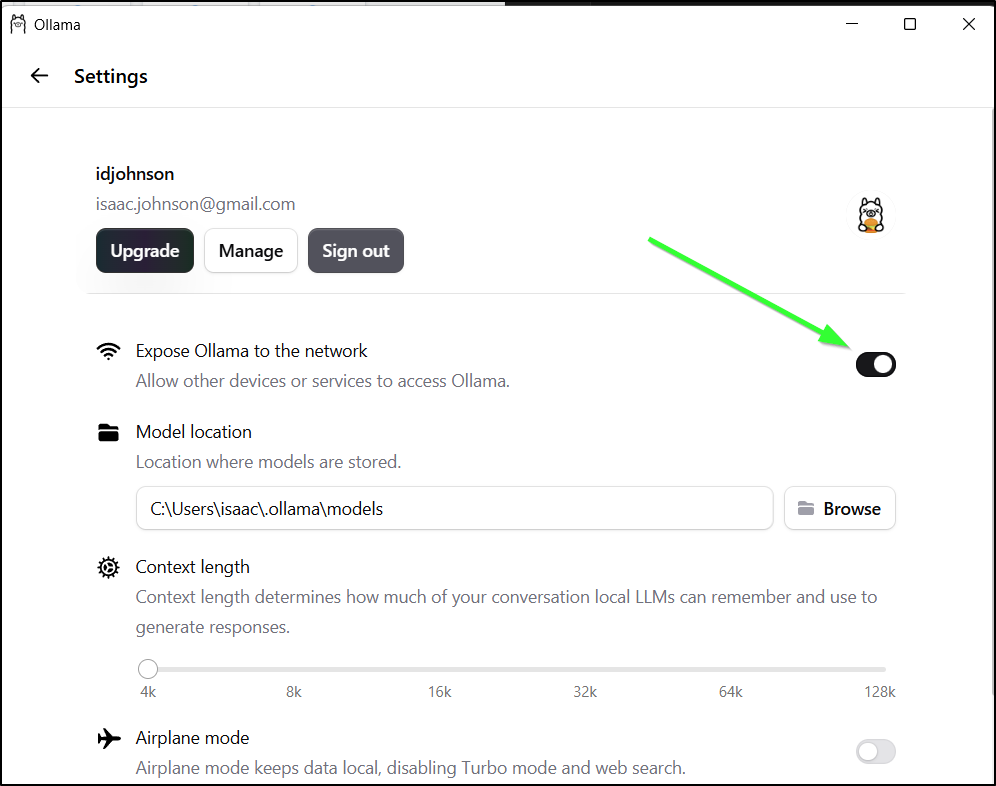
While localhost fails, accessing by the PC’s IPv4 does work
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ wget http://localhost:11434/v1/models
--2025-08-14 13:11:43-- http://localhost:11434/v1/models
Resolving localhost (localhost)... 127.0.0.1
Connecting to localhost (localhost)|127.0.0.1|:11434... failed: Connection refused.
builder@DESKTOP-QADGF36:~/Workspaces/jekyll-blog$ wget http://192.168.1.160:11434/v1/models
--2025-08-14 13:11:45-- http://192.168.1.160:11434/v1/models
Connecting to 192.168.1.160:11434... connected.
HTTP request sent, awaiting response... 200 OK
Length: 190 [application/json]
Saving to: ‘models’
models 100%[=================================================>] 190 --.-KB/s in 0s
2025-08-14 13:11:45 (35.4 MB/s) - ‘models’ saved [190/190]
This time I can see it (and feel it) cranking away
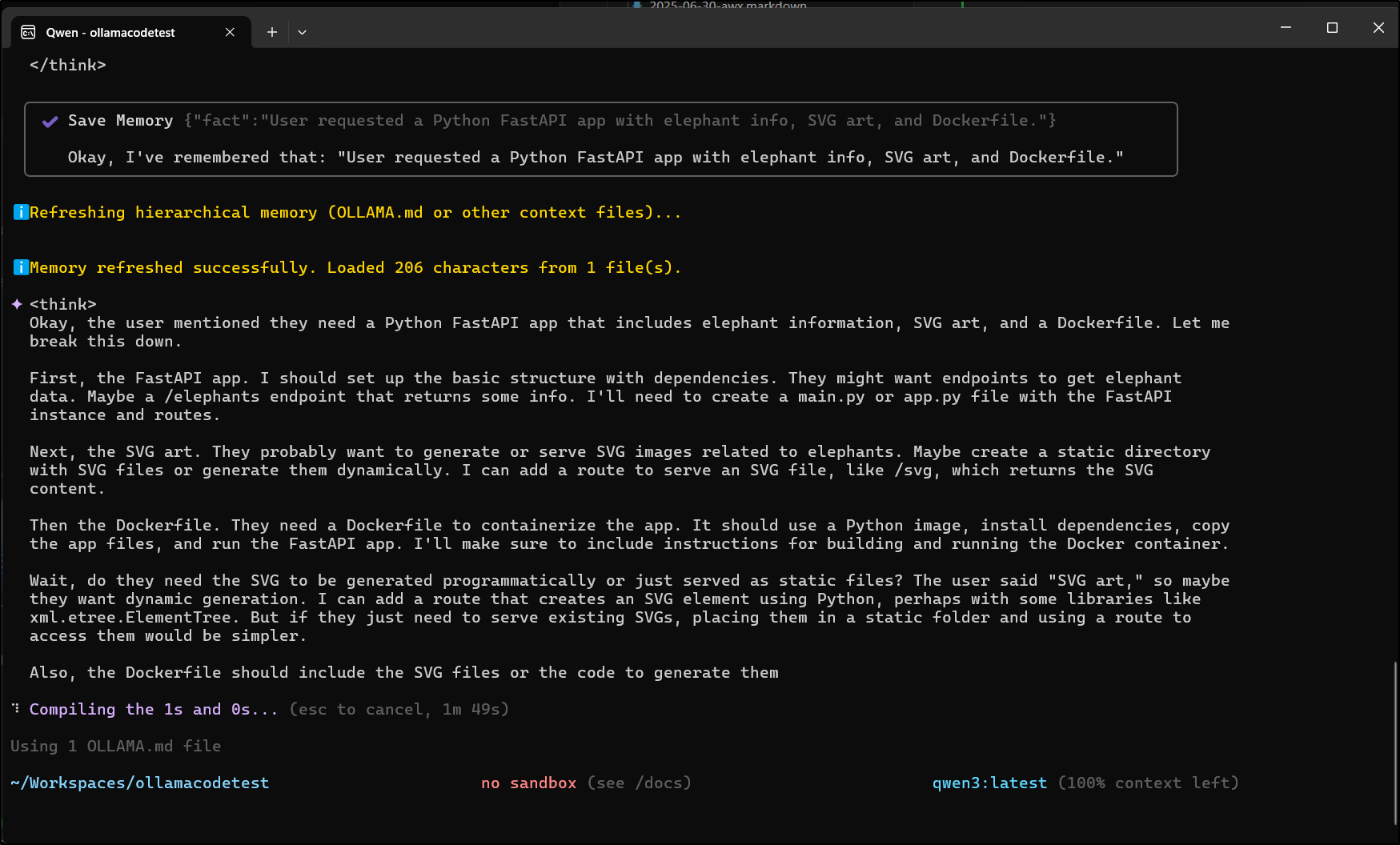
And we can see it working
However, I gave it ample time (over 7h) and it never wrote a file
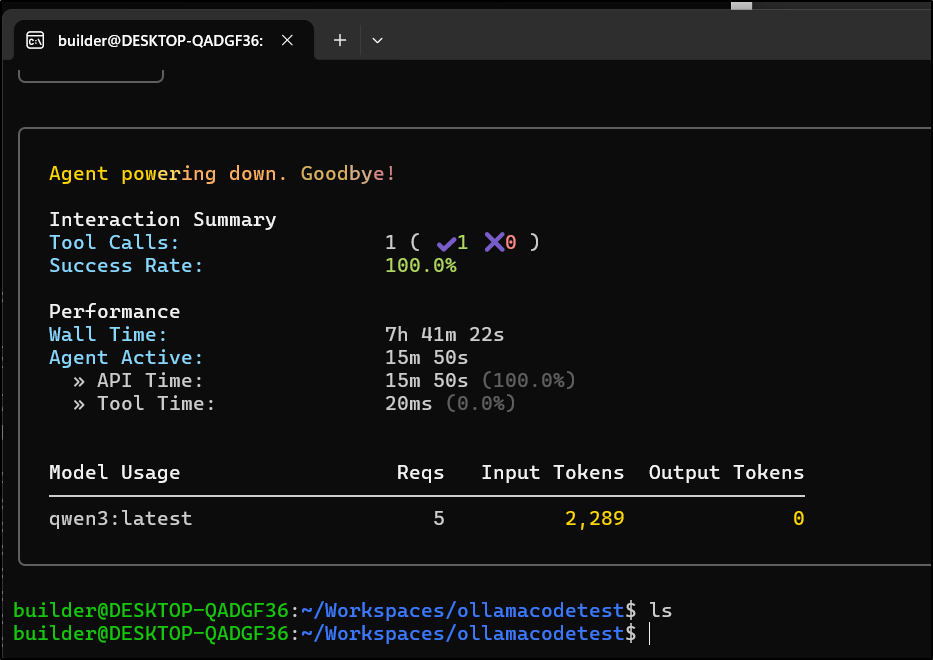
However, when I reduced it to more bite sized hunks it did try and do actions
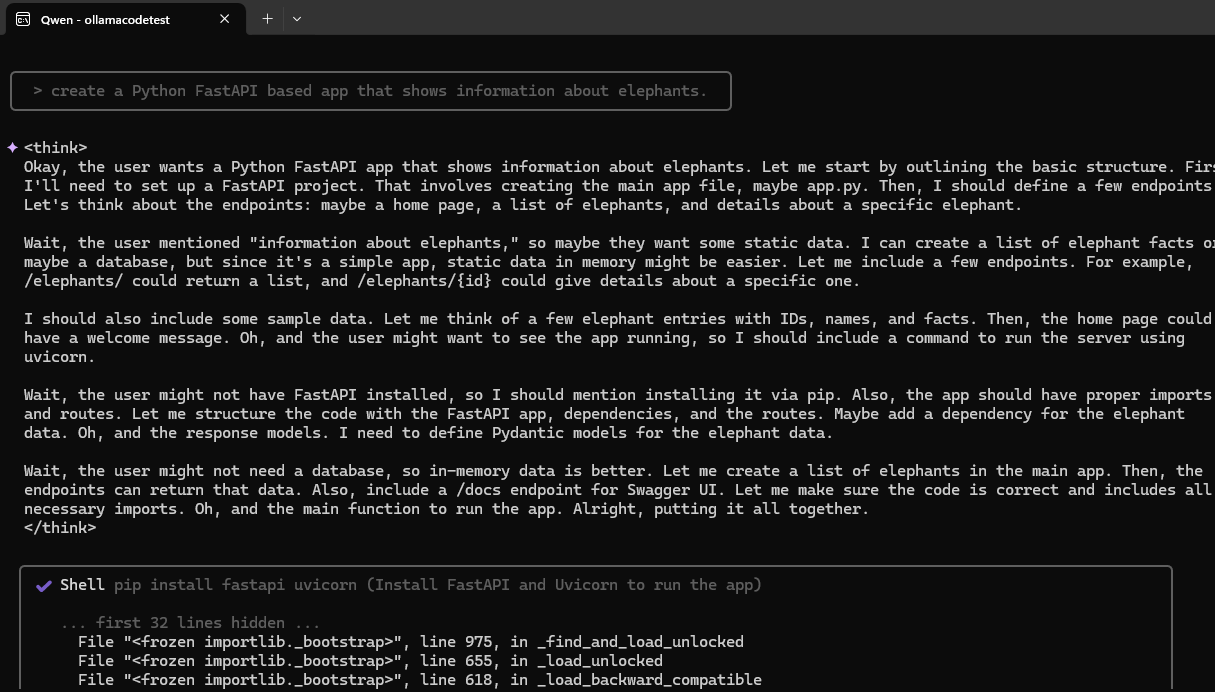
It is quite slow to accomplish things and I might use continue.dev plugin instead as it is far more reliable
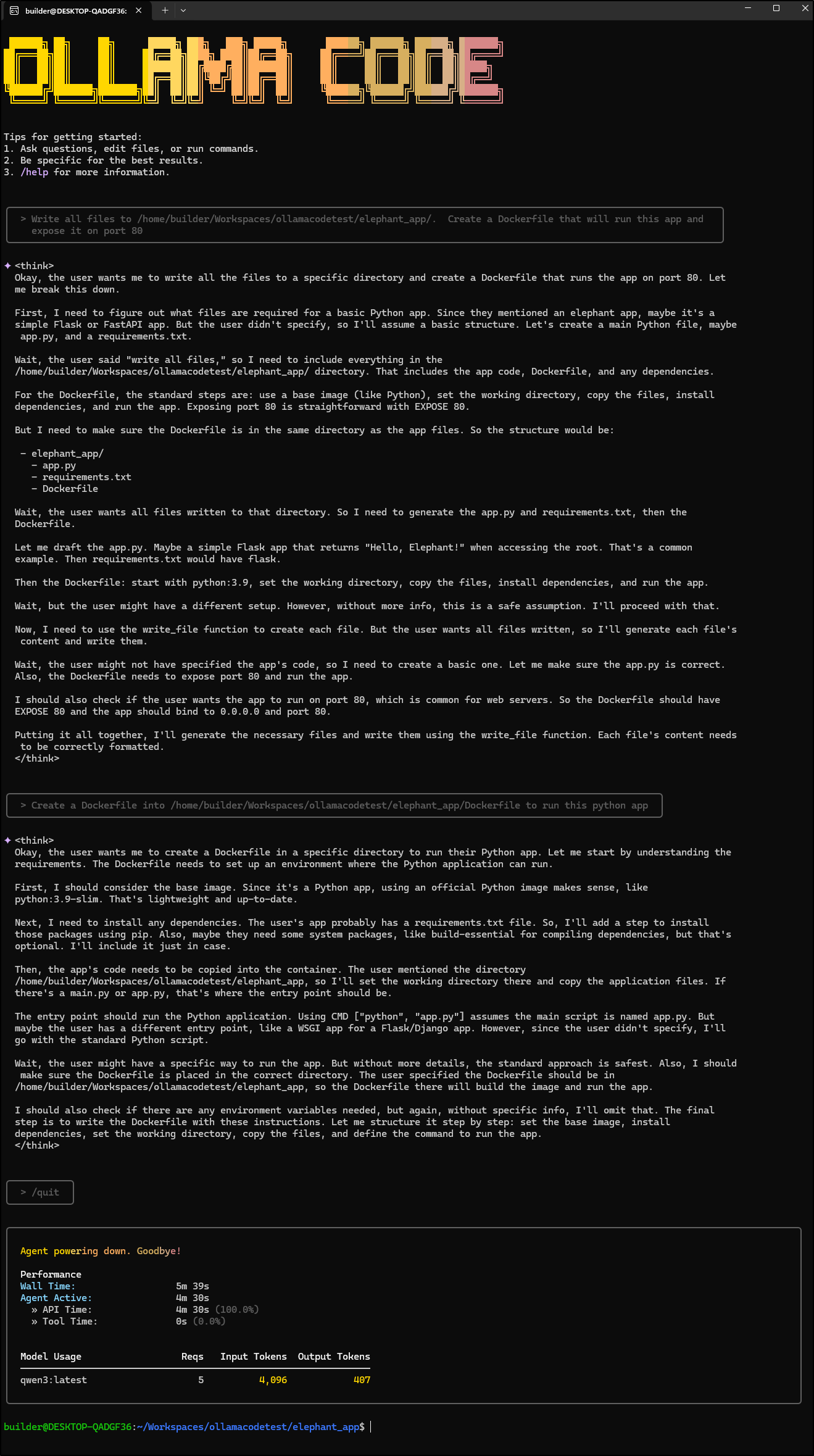
Here we see effectively the same ask to the same model on the same host, just with the Continue.dev plugin in VS Code
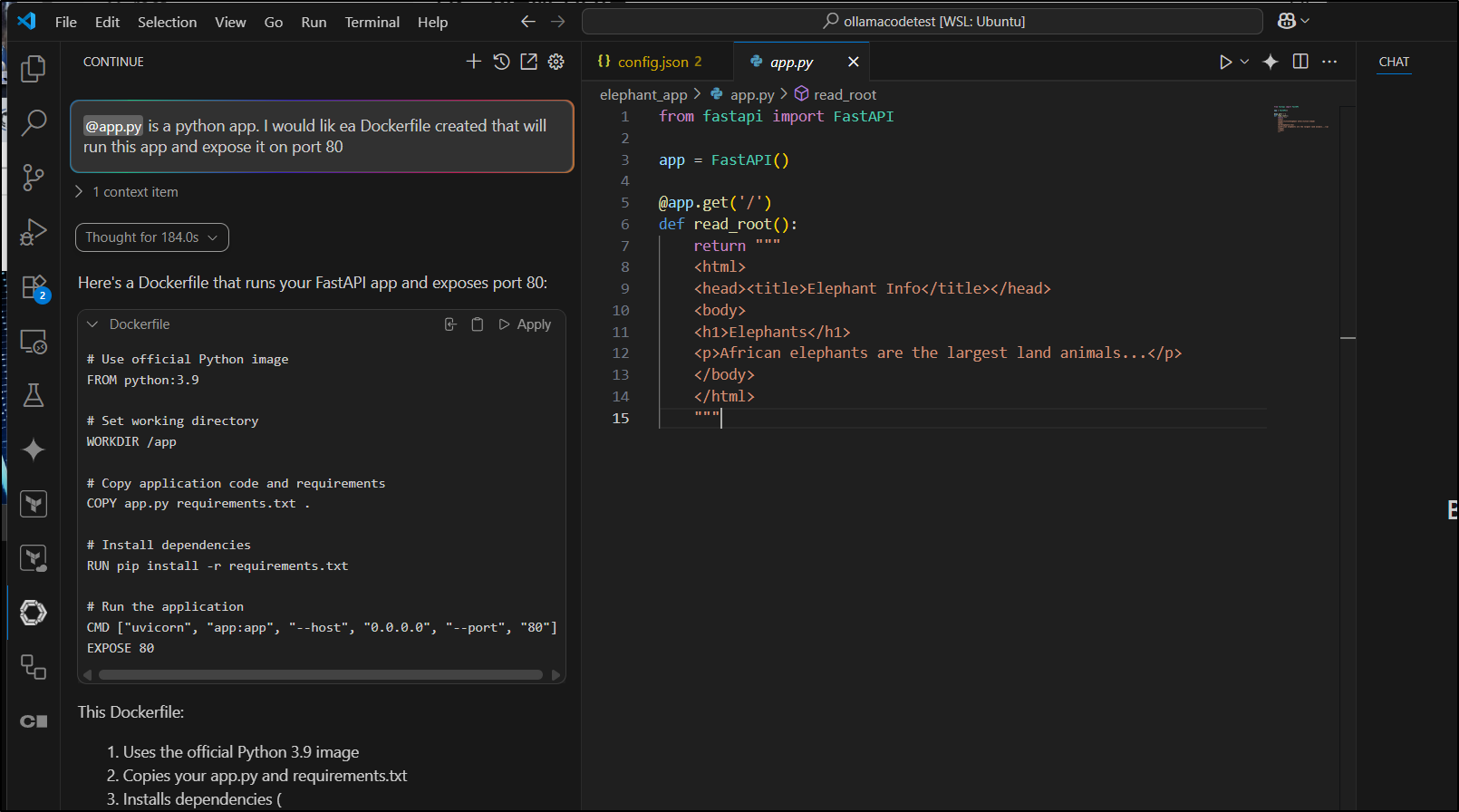
Summary
We had a few versions of the app - from a bland blue with general icons
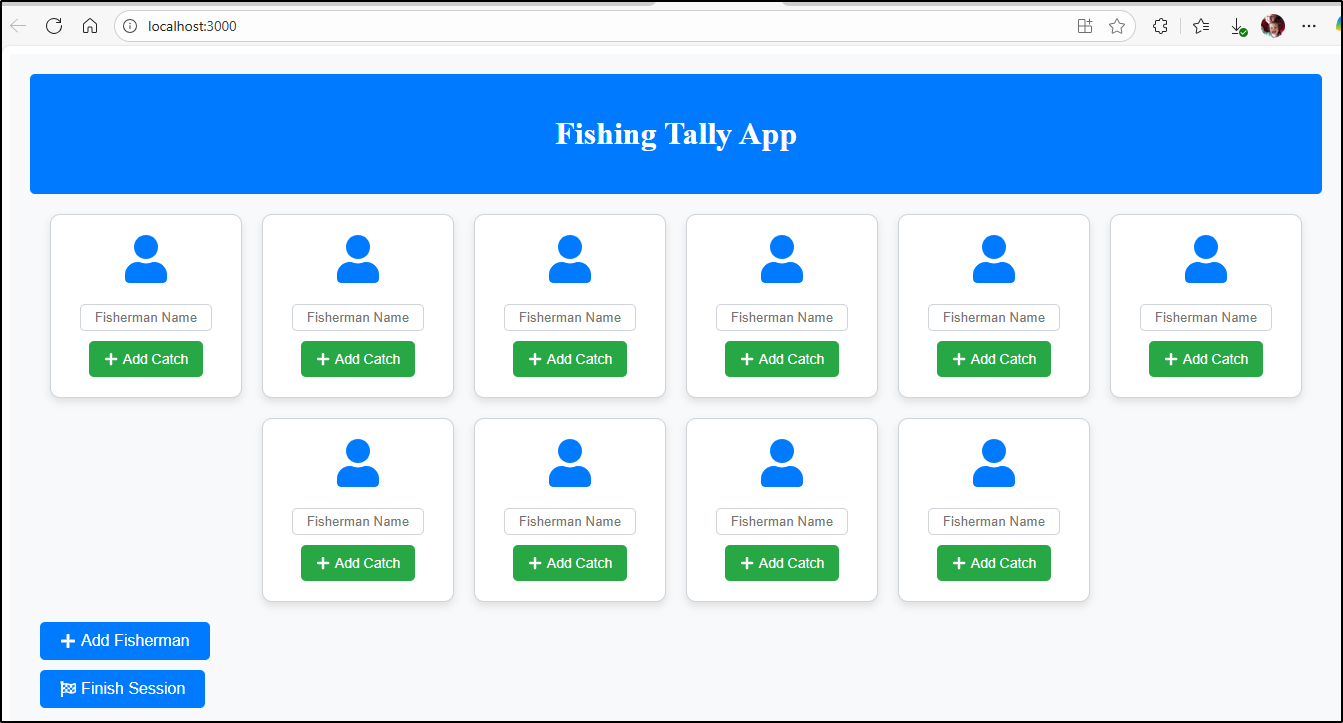
Some basic SVG art
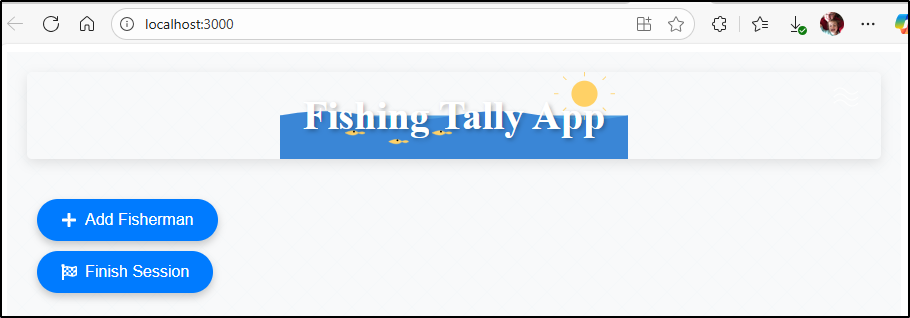
to session management
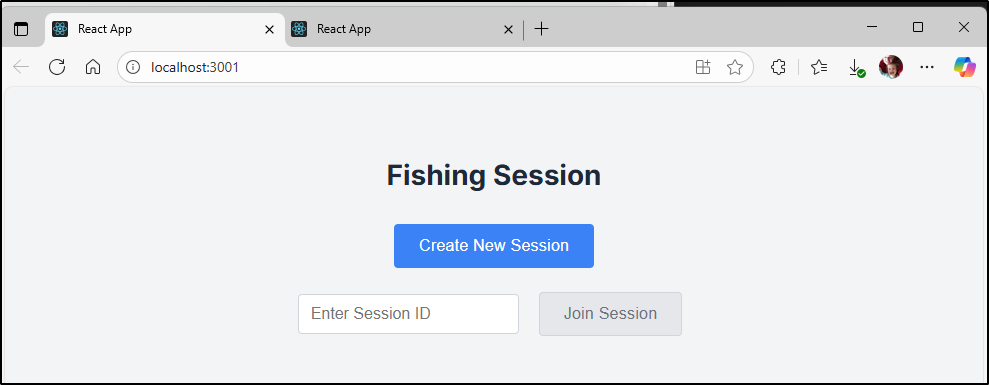
We started with OpenCode by sst.dev. The only successful path I managed to get working was using Google Gemini via Vertex AI. This just meant I had an alternative to Google CLI to do the same thing.
Since I was updating a fishing app, I then did updates with QWen3 Coder, Claude Code, Gemini CLI, Copilot (in VS Code) and lastly Gemini Code Assist. Each did just fine (though Gemini Code Assist got a bit confused).
In looking for something that might work with my Ollama, I then checked out Ollama Code which claimed to fork from Qwen3 Coder (a fork of Gemini CLI).
Last thoughts
These new OS CLIs work, sometimes. I do not find them improving on the vendors own tools - that is, I would rather use Gemini CLI for Gemini Pro in GCP, Qwen3 Coder against Alibaba Cloud for Qwen3 Coder Plus, and Claude Code for Anthropic. Copilot is really best in VS Code.
For local LLM hosting in Ollama, I find Ollama Code slower than just using the Continue.dev plugin so I really cannot see why I would switch to it.
That said, it does have promise and I’ll circle back on both of these tools again in a few months.
