

Published: Jan 2, 2025 by Isaac Johnson
Let’s talk about Large Language Models (LLMs) and how we can apply them at home. I’ve spoken on Copilot and Google Gemini Code Assist before. Those are very valid models and I use both on a regular basis.
However, today I want to talk today about LLMs we can self-host. Ollama is a free Open-Source toolset we can use to engage with LLMs that run locally on our own hardware. Like a ‘private ChatGPT’, these let us use different models and all we are really paying for is our local compute (usually by way of heat and power).
Trying Ollama on a Pi3
Let’s start with some rather moderate hardware. I have a couple old Raspberry Pi3s. I’ll use one with a 4 x arm71, Cortex-A53 and 1Gb of memory just to see what it can do.
Unfortunately, it looks like Armv71 is not supported:
builder@pi3green:~ $ curl -fsSL https://ollama.com/install.sh | sh
ERROR: Unsupported architecture: armv7l
My “newer” one is a Pi4 which has 4 x aarch64, Cortex-A72 CPU and 4Gb of memory, I’ll try that next.
This seems to be more successful
builder@pi4black:~ $ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
>>> Downloading Linux arm64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
I can now check the version
builder@pi4black:~ $ ollama --version
ollama version is 0.5.4
I now want to test with a model. The one I read they were using in this guide was “phi3”, so let’s give it a try
It took a couple minutes to download, but then alerted me that I lack the memory
builder@pi4black:~ $ ollama run phi3
pulling manifest
pulling 633fc5be925f... 100% ▕███████████████████████████████████████████████████████████████▏ 2.2 GB
pulling fa8235e5b48f... 100% ▕███████████████████████████████████████████████████████████████▏ 1.1 KB
pulling 542b217f179c... 100% ▕███████████████████████████████████████████████████████████████▏ 148 B
pulling 8dde1baf1db0... 100% ▕███████████████████████████████████████████████████████████████▏ 78 B
pulling 23291dc44752... 100% ▕███████████████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
success
Error: model requires more system memory (5.6 GiB) than is available (3.4 GiB)
I also tried zephyr which is a smaller model
builder@pi4black:~ $ ollama run zephyr
pulling manifest
pulling 730ebed2578e... 100% ▕███████████████████████████████████████████████████████████████▏ 4.1 GB
pulling a406579cd136... 100% ▕███████████████████████████████████████████████████████████████▏ 1.1 KB
pulling a96be15318d6... 100% ▕███████████████████████████████████████████████████████████████▏ 101 B
pulling fa956ab37b8c... 100% ▕███████████████████████████████████████████████████████████████▏ 98 B
pulling 7d3eb0692a36... 100% ▕███████████████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
success
Error: model requires more system memory (5.5 GiB) than is available (3.4 GiB)
Before landing on tinydolphin
Let’s try a story prompt: “create a story about a girl with a red sweatshirt bringing cookies to her grandmother through the forest”
Here we can see it generating the story in real time:
The store in full:
nce upon an ancient time in a land far away, there lived a brave and curious girl named Dolphin. As days passed by, her family grew ever so proud of their accomplishments. Her grandmother, wise and kind, had been their constant provider all these years, sharing with them the love and joy of life through cooking and stories.
Their days were often spent outdoors in the forest, where nature’s beauty unfolded before their eyes like a painting, with sunsets casting golden hues on the earth below. The grandmother had been known to whisk up a scrumptious meal for them during evenings, and Dolphin would proudly bring it to her parents for sharing.
One fateful day in autumn, Dolphin’s family began their daily routine when they noticed the sounds of laughter echoing from the nearby forest. As they approached, they found themselves surrounded by the sweet scent of freshly baked cookies. The grandmother was beaming with pride as she shared a few bites with her granddaughter.
Dolphin could not contain herself as she proudly presented her grandmother with a heart-shaped cookie, which left her giggling like a child. It wasn’t long before they were approached by a small, friendly dog, who seemed to be in need of some fresh air and the sweet treats. Dolphin introduced the dog to her grandmother and shared a cookie with it as well.
Feeling a bit warm from their exertions, the family sat down for a moment to savor their delicious meal. It was then that Dolphin noticed something unusual in the forest: noiseless footsteps echoing through the underbrush, and an unfamiliar scent wafting towards them.
Dolphin’s curiosity piqued, she asked her grandmother about the source of these strange noises. The grandmother confided that someone had just passed by her home, leaving a trail of footprints in the mud behind. Feeling unsure, Dolphin decided to investigate further.
Much to her delight, they soon stumbled upon an old wooden bridge, covered in moss and dotted with flowers. As they stood beneath it, the bridge seemed to be suspiciously thin, and a strange, delicate scent wafted through the air. Dolphin had finally discovered where those footprints were coming from!
Their excitement was contagious as they walked further into the forest, discovering more hidden treasures along their way. They found a beautiful old map in an old wooden box, which led them to the source of the peculiar scent. There, they found a long-forgotten old wooden chest, filled with various items left behind by the people who passed through years ago.
As Dolphin opened the chest, she was astounded to find a grand surprise: a beautifully wrapped present waiting for her. As it unfurled, she realized that it contained not one but two delicious looking cookies! This made her heart swell with joy as she shared them with her grandmother.
With gratitude for their kindness, Dolphin thanked the person who had passed by her home and set off back towards the familiar streets of her small town. The laughter from their family echoed through the air, but it was the warmth and love they shared as they ventured through the forest together that truly made this day memorable.
However, when thrown a basic US Civics question, it did not fair as well:
>>> who is the 20th president of the United States?
It responded
The 20th President of the United States was Grover Cleveland, who served from March 4, 1885 to January 20, 1889. He was the son of President James Garfield and was born in Erie, Ohio, on May 29, 1822. Grover Cleveland was known for his diplomatic skills and as a progressive politician, who worked tirelessly to balance the interests of the country with those of his state.
The 20th president was actually James Garfield born in Ohio in 1831 and died 1881. Grover Cleveland was actually the 22nd and 24th president and was born in New Jersey in 1837. Seems almost all the facts were wrong, but confidentially so.
Using labels
One thing worth mentioning is that most of these models have various tags, just like Docker containers. The tags often denote the size of the model which usually translates to size and memory requirements.
So, for instance, while our Pi4 cannot do the phi3 model with the default label due to memory:
builder@pi4black:~ $ ollama run phi3
Error: model requires more system memory (5.6 GiB) than is available (3.4 GiB)
I can look at all the tags available and see there are smaller ones from which we can choose
While I couldn’t use even the smallest Phi3 modle
builder@pi4black:~ $ ollama run phi3:3.8b-mini-4k-instruct-q2_K
pulling manifest
pulling 932db794f22e... 100% ▕███████████████████████████████████████████████████████▏ 1.4 GB
pulling fa8235e5b48f... 100% ▕███████████████████████████████████████████████████████▏ 1.1 KB
pulling 542b217f179c... 100% ▕███████████████████████████████████████████████████████▏ 148 B
pulling 8dde1baf1db0... 100% ▕███████████████████████████████████████████████████████▏ 78 B
pulling 5181e7c1f392... 100% ▕███████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
success
Error: model requires more system memory (4.9 GiB) than is available (3.4 GiB)
You can see how it was much closer to my memory allotment
On K8s
Let’s use the older test cluster for this.
I’m essentially following the steps from here
$ cat ./ollama.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ollama
namespace: ollama
spec:
selector:
matchLabels:
name: ollama
template:
metadata:
labels:
name: ollama
spec:
containers:
- name: ollama
image: ollama/ollama:latest
ports:
- name: http
containerPort: 11434
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: ollama
namespace: ollama
spec:
type: ClusterIP
selector:
name: ollama
ports:
- port: 80
name: http
targetPort: http
protocol: TCP
I’ll then create a namespace and apply
builder@DESKTOP-QADGF36:~$ kubectl create ns ollama
namespace/ollama created
builder@DESKTOP-QADGF36:~$ kubectl apply -f ./ollama.yaml
deployment.apps/ollama created
service/ollama created
I gave it 14m before switching to my primary cluster - i cannot be sure if this is due to my nodes or dockerhub
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 16m default-scheduler Successfully assigned ollama/ollama-668ffb5bc9-gzn5q to isaac-macbookpro
Normal Pulling 14m kubelet Pulling image "ollama/ollama:latest"
It worked fine on the primary cluster.
However, it kept rejecting my models
$ kubectl port-forward svc/ollama -n ollama 11434:80 &
[1] 4626
$ curl http://localhost:11434/api/generate -d '{"model":"llama2","prompt":"Who was the 20th US President?"}'
Handling connection for 11434
{"error":"model 'llama2' not found"}
$ curl http://localhost:11434/api/generate -d '{
> "model": "tinydolphin",
> "prompt":"who was the 20th US President?"
> }'
Handling connection for 11434
{"error":"model 'tinydolphin' not found"}
That said, I could hop on the pod to do it:
Again, without the GPU, it’s as slow as the rest.
On an older i5 Macbook Air
Finally, let’s give it a go on a Macbook Air which is the master node of my test cluster
builder@anna-MacBookAir:~$ ollama run phi3
pulling manifest
pulling 633fc5be925f... 100% ▕███████████████████████████████████████████████████████▏ 2.2 GB
pulling fa8235e5b48f... 100% ▕███████████████████████████████████████████████████████▏ 1.1 KB
pulling 542b217f179c... 100% ▕███████████████████████████████████████████████████████▏ 148 B
pulling 8dde1baf1db0... 100% ▕███████████████████████████████████████████████████████▏ 78 B
pulling 23291dc44752... 100% ▕███████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
success
Error: model requires more system memory (5.6 GiB) than is available (4.2 GiB)
Even my old macbook seems insufficient, despite having 8gb total memory
builder@anna-MacBookAir:~$ free -m
total used free shared buff/cache available
Mem: 7848 4299 530 43 3018 3204
Swap: 2047 907 1140
Here we can see it generating a story with the prompt:
And it’s results
In the quiet solitude of the forest, there lies a young girl named Lily. Lily’s grandma often enjoyed spending time in her garden, baking delicious treats and sharing them with friends and family. When summer approached, Lily would bring some of her homemade cookies to her grandma for her birthday present.
As the days passed, Lily felt more confident with each bite she took. Her grandmother loved the cherry red sweatshirt that Lily wore, and whenever she found herself in a moment of quiet contemplation, she’d reminisce about their past together.
One sunny day, Lily decided it was time to visit her grandma once again. As she made her way through the lush foliage, she couldn’t help but feel grateful for the memories they shared in the quiet forest. The cherry red sweatshirt of her grandmother matched the sunny mood, and as Lily got closer, she noticed a small pile of cookies scattered on the ground.
“I’ve missed you dearly, grandma!” Lily said, picking up the first cookie. “What brings you here?”
“Just coming back for my birthday,” said Grandma with a chuckle. “You know how much I love sweets.”
Lily felt her heart swell with joy as she carefully removed the cookies from the ground. Her grandmother’s sweet scent was filling the air, and Lily couldn’t help but wonder how many more years it had taken for her to finally get to meet her in person.
As they stood together, they began to chat about their days, their plans, and everything that mattered to them. Grandma shared stories of her life as a young girl, filled with adventures and laughter. Lily, on the other hand, spoke about the simple pleasures that bring us joy – like sharing a warm cookie with someone we love.
“You know what?” said Lily, breaking the silence. “I’ve never had your grandma’s cookies before.”
“Oh, are you ready to try some?” asked Grandma, who always had a smile for her visitors. Lily nodded, and the two began to bake.
As they cooked together, Lily couldn’t help but feel grateful for the warmth and connection she felt with her grandmother. It was moments like these that reminded her why her love for baking and cherry red sweatshirts were so special. And as they stood there together, Grandma gave Lily a look of pure happiness.
“Thank you,” said Lily. “For everything.”
The sun began to set, casting its golden rays over the forest. The bustling sounds of birds chirping and squirrels hopping had long since faded away, leaving only a sweet scent in their wake. Lily felt tears welling up in her eyes as she gazed into Grandma’s eyes.
“I love you, grandma,” she said with sincerity. “Thank you for showing me the way and sharing your love with me.”
Later that evening, as the sun began to set once more, Lily found herself walking through her grandmother’s garden. It was a warm afternoon, perfect for basking in the sunlight. She grabbed a vase of wildflowers from the ground and carried it over to where Grandma stood with her cherry red sweatshirt tied loosely around her waist.
“Here, grandma,” Lily said, placing the flowers down on the ground. “We’ll have more later when I make more cookies for you.”
“Thank you, dear,” replied Grandma, smiling down at her granddaughter with love. She leaned in and hugged Lily tightly, wrapping her arms around her like she had done so many times before.
Later that night, as they sat by the fire pit, sharing a meal and talking about their day, Grandma couldn’t help but smile at the memory of Lily’s cherry red sweatshirt. She had spent countless hours baking with her granddaughter, creating sweet treats to share with friends and family. And every time they shared a meal together, she felt grateful for the love that was pouring out of her heart.
“Lily,” said Grandma when she noticed Lily’s eyes welling up in tears. “What happened during those days?”
“I don’t know,” replied Lily with vulnerability. “I think I just forgot about the cookies, and it was like I had to go through all that again.”
Lily began to cry as she realized how much she missed her grandmother’s warm embrace and sweet stories. “But, grandma, I can’t forget! It was so special sharing those moments with you.”
“Don’t worry, dear,” said Grandma, giving Lily a gentle smile. “Even if it wasn’t what we had planned for, we were still there for each other. And that’s all that matters in the end.”
As they lay on the grass together, surrounded by the warmth of their love and cherry red sweatshirt, Grandma smiled at her granddaughter with pride. She knew that Lily would always have a special place in her heart, and she couldn’t wait to see what adventures awaited them next.
“I promise,” said Lily, looking up into the sky as a cool breeze began to pick up. “We will never forget this day.”
As they stood there together, surrounded by nature and loved ones, Lily knew that she would always cherish the memories made with her grandmother. And as they continued to share stories and laughter, their love for each other only grew stronger.
For years, Lily continued to cherish the memories she had shared with her grandmother, and every time she walked through the forest, she felt a deep sense of gratitude for the moments that had brought them together.
As before on the Pi, a factual history question was equally wrong
>>> who is the 20th president of the United States?
Returning
President William Howard Taft was inaugurated as the 20th President of the United States on May 8, 1909. He succeeded President Theodore Roosevelt, who had resigned from office to become the Secretary of the Navy. Taft was a Republican from Ohio and served in the United States House of Representatives before being elected president in 1908.
WSL on machine with GPU
Let’s now try on a computer with a decent graphics card
builder@DESKTOP-QADGF36:~$ curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
[sudo] password for builder:
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
WARNING: systemd is not running
WARNING: see https://learn.microsoft.com/en-us/windows/wsl/systemd#how-to-enable-systemd to enable it
>>> Nvidia GPU detected.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
As WSL lacks systemd to start the background process, we’ll want to serve first
builder@DESKTOP-QADGF36:~$ ollama serve
Couldn't find '/home/builder/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIAkmc9YQ1PP5qGOHj2x3BW4ygyL7Y/6k7WIKKlBW9+iv
2024/12/23 07:33:56 routes.go:1259: INFO server config env="map[CUDA_VISIBLE_DEVICES: GPU_DEVICE_ORDINAL: HIP_VISIBLE_DEVICES: HSA_OVERRIDE_GFX_VERSION: HTTPS_PROXY: HTTP_PROXY: NO_PROXY: OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_GPU_OVERHEAD:0 OLLAMA_HOST:http://127.0.0.1:11434 OLLAMA_INTEL_GPU:false OLLAMA_KEEP_ALIVE:5m0s OLLAMA_KV_CACHE_TYPE: OLLAMA_LLM_LIBRARY: OLLAMA_LOAD_TIMEOUT:5m0s OLLAMA_MAX_LOADED_MODELS:0 OLLAMA_MAX_QUEUE:512 OLLAMA_MODELS:/home/builder/.ollama/models OLLAMA_MULTIUSER_CACHE:false OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:0 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:* app://* file://* tauri://* vscode-webview://*] OLLAMA_SCHED_SPREAD:false ROCR_VISIBLE_DEVICES: http_proxy: https_proxy: no_proxy:]"
time=2024-12-23T07:33:56.803-06:00 level=INFO source=images.go:757 msg="total blobs: 0"
time=2024-12-23T07:33:56.803-06:00 level=INFO source=images.go:764 msg="total unused blobs removed: 0"
[GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached.
[GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production.
- using env: export GIN_MODE=release
- using code: gin.SetMode(gin.ReleaseMode)
[GIN-debug] POST /api/pull --> github.com/ollama/ollama/server.(*Server).PullHandler-fm (5 handlers)
[GIN-debug] POST /api/generate --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (5 handlers)
[GIN-debug] POST /api/chat --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (5 handlers)
[GIN-debug] POST /api/embed --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (5 handlers)
[GIN-debug] POST /api/embeddings --> github.com/ollama/ollama/server.(*Server).EmbeddingsHandler-fm (5 handlers)
[GIN-debug] POST /api/create --> github.com/ollama/ollama/server.(*Server).CreateHandler-fm (5 handlers)
[GIN-debug] POST /api/push --> github.com/ollama/ollama/server.(*Server).PushHandler-fm (5 handlers)
[GIN-debug] POST /api/copy --> github.com/ollama/ollama/server.(*Server).CopyHandler-fm (5 handlers)
[GIN-debug] DELETE /api/delete --> github.com/ollama/ollama/server.(*Server).DeleteHandler-fm (5 handlers)
[GIN-debug] POST /api/show --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (5 handlers)
[GIN-debug] POST /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).CreateBlobHandler-fm (5 handlers)
[GIN-debug] HEAD /api/blobs/:digest --> github.com/ollama/ollama/server.(*Server).HeadBlobHandler-fm (5 handlers)
[GIN-debug] GET /api/ps --> github.com/ollama/ollama/server.(*Server).PsHandler-fm (5 handlers)
[GIN-debug] POST /v1/chat/completions --> github.com/ollama/ollama/server.(*Server).ChatHandler-fm (6 handlers)
[GIN-debug] POST /v1/completions --> github.com/ollama/ollama/server.(*Server).GenerateHandler-fm (6 handlers)
[GIN-debug] POST /v1/embeddings --> github.com/ollama/ollama/server.(*Server).EmbedHandler-fm (6 handlers)
[GIN-debug] GET /v1/models --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (6 handlers)
[GIN-debug] GET /v1/models/:model --> github.com/ollama/ollama/server.(*Server).ShowHandler-fm (6 handlers)
[GIN-debug] GET / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
[GIN-debug] GET /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] GET /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
[GIN-debug] HEAD / --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func1 (5 handlers)
[GIN-debug] HEAD /api/tags --> github.com/ollama/ollama/server.(*Server).ListHandler-fm (5 handlers)
[GIN-debug] HEAD /api/version --> github.com/ollama/ollama/server.(*Server).GenerateRoutes.func2 (5 handlers)
time=2024-12-23T07:33:56.804-06:00 level=INFO source=routes.go:1310 msg="Listening on 127.0.0.1:11434 (version 0.5.4)"
time=2024-12-23T07:33:56.807-06:00 level=INFO source=routes.go:1339 msg="Dynamic LLM libraries" runners="[cpu cpu_avx cpu_avx2 cuda_v11_avx cuda_v12_avx rocm_avx]"
time=2024-12-23T07:33:56.807-06:00 level=INFO source=gpu.go:226 msg="looking for compatible GPUs"
time=2024-12-23T07:33:58.897-06:00 level=INFO source=types.go:131 msg="inference compute" id=GPU-44d5572d-f3f5-e282-2074-24b44c091e34 library=cuda variant=v12 compute=8.6 driver=12.6 name="NVIDIA GeForce RTX 3070" total="8.0 GiB" available="6.9 GiB"
I can now try with our usual test of tinydolphin. As you can see, it is radically faster
The story in full:
As sunset casts its golden glow over the landscape, a lush and vibrant forest comes alive in harmony with nature. Lingering whispers of wind carry the scent of wildflowers and meadows where countless creatures frolic amidst the verdant foliage. Among these flourishing scenes, there is a solitary figure, a young woman with the unmistakable essence of an adventurer in her step. She moves gracefully through the branches overhead, her red sweatshirt fluttering behind her like a colorful cloak.
The curious onlookers gathered around the old lady’s dwelling cannot help but notice the young woman’s peculiar choice of attire. Their curiosity is piqued as they wonder: “What kind of adventurer would wear such an ordinary-looking sweatshirt?”, questioning their belief that all fashion comes in a limited spectrum of color combinations and patterns.”
As she draws closer to her grandmother, the young woman takes off her red sweatshirt, revealing the warmth of her heart beneath. “Oh, Grandma! I didn’t want you to see me like this. Can we continue our journey together?” With a smile and an outstretched hand, she extends her hand towards her grandmother’s aged paws as they form a unified handshake.
The old woman, whose eyes are brimming with warmth, takes the young woman’s hand and leads her through the forest. As they walk together, the two begin to explore the landscape together, their laughter filled with memories of the past, as if this moment was meant for them to rekindle an old flame.
The sun dips below the horizon, casting its last rays on the canopy above. The pair reaches a small clearing nestled among the trees, where they discover a rustic picnic table set with a variety of delicious-smelling fruits and a plateful of warm bread. With a deep breath, they dig into the freshly baked goodness, their laughter filling the air with joyous exuberance.
As they continue to feast on the delightful meal together, they share stories of old times and cherished memories. As night descends upon the forest, they lie beneath the star-studded sky, gazing up at the vast expanse of the cosmos while enjoying one last laugh before succumbing to slumber.
The sun rises once more, casting its last rays on the scene as they return to their own homes. The cherished journey through the forest has brought them closer than ever before, allowing for unforgettable moments that will forever remain in their hearts.
Because I have more memory, I can actually use a larger model this time
builder@DESKTOP-QADGF36:~$ ollama run zephyr
pulling manifest
pulling 730ebed2578e... 100% ▕███████████████████████████████████████████████████████████████▏ 4.1 GB
pulling a406579cd136... 100% ▕███████████████████████████████████████████████████████████████▏ 1.1 KB
pulling a96be15318d6... 100% ▕███████████████████████████████████████████████████████████████▏ 101 B
pulling fa956ab37b8c... 100% ▕███████████████████████████████████████████████████████████████▏ 98 B
pulling 7d3eb0692a36... 100% ▕███████████████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
success
>>> create a story about a girl with a red sweatshirt bringing cookies to her grandmother through the forest
Once upon a time, there was a young girl named Lily. She had a close bond with her grandma, who lived deep in the woods.
Every week, Lily would visit her beloved grandmother, but this particular day, the path leading to her grandma's house
was closed due to heavy rainfall.
Lily didn't want to miss out on visiting her grandmother and decided to take a different route through the forest. She
wore her favorite red sweatshirt and carried a basket filled with freshly baked cookies that she made herself. She set
off into the dense woods, determined to reach her grandma's house in time for tea.
As Lily walked through the forest, she heard strange sounds coming from behind the trees. She cautiously moved forward,
her heart pounding in her chest. Suddenly, a group of rabbits darted past her feet, followed by a family of squirrels
carrying acorns. Lily grinned as she realized that she had stumbled upon an enchanted forest.
The further Lily ventured into the woods, the more she found herself surrounded by mystical creatures. She saw a group of
fairies dancing around a daisy, and the trees seemed to whisper secrets in her ear. The red sweatshirt on Lily's back
glowed softly as if it were magical too.
With her basket full of cookies, Lily finally reached her grandmother's house. Her grandma was overjoyed to see Lily and
immediately invited her inside for tea. As they sipped their drinks, Lily shared the story of her adventure in the
forest, which had been filled with wondrous surprises.
From that day on, Lily would always take the longer route through the enchanted forest, knowing that the magic she
encountered was worth the extra effort. And every time she wore her red sweatshirt, she felt a sense of warmth and
comfort, as if it were still radiating the mystical energy of the woods.
On Jokes
I asked the tinydolphin models on the Pi and Laptop to create a joke about a parrot
>>> tell me a joke about a parrot
The Pi replied
Why did the parrot refuse to say “cheerio”? Because he saw birds do it, and couldn’t be bothered.
And the laptop
Parrot: What did the parrot say to its friend, the cat?
Cat: “Sit! I have something to show you.”
Parrot: “Oh, great!”
Cat: “Well, look at this feather.”
Parrot: “What?”
Cat: “There’s a parrot feather. Didn’t you see it? It’s right there.”
Parrot: “Yes, I saw it. But what about the feathers on the chest of the bird? Those are very pretty.”
Cat: “Oh, well, maybe they just haven’t been brushed yet.”
Parrot: “I guess you’re right. It’s all in the eyes.”
I used Zephyr which explained the jokes, but they were equally not funny
>>> tell me a joke about a parrot
Why did the parrot wear lipstick?
To cover up his bird beak! (This is a pun on the phrase "bird's mouth," which some people mistakenly pronounce as "berd's
mousth" or "bert's lipstick.")
Alternatively, why did the parrot have to stay home from school?
Because he couldn't find his beak! (This is a playful riff on the saying "couldn't find my way with both hands," which is
commonly used when someone is struggling with directions or location.)
Or, why did the parrot get arrested?
Because he was accused of stealing a cover-up! (This is a pun on the phrase "bird's mouth" again and also plays with the
homophonic words "cover-up" and "copper's nipple.")
Hope you found these jokes as amusing as I do!
Code
Let’s ask for a basic Nginx Kubernetes manifest. Something I do fairly often
First, I’ll use the tinydolphin model which worked fine on K8s and the Pi4.
show me a Kubernetes YAML manifest for a simple nginx based web server
These took a very long time.
tinydolphin results
The Pi4 was terser with:
Sure! Here is a simple Kubernetes YAML manifest file for a basic NGINX reverse proxy:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas:
min: 1
max: 3
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: "nginx:alpine"
ports:
- containerPort: 80
- protocol: tcp
and the Kubernetes pod had a bit of commentary:
Sure, here’s a simple Kubernetes YAML manifest for a basic NGINX-based web server:
apiVersion: v1
kind: Service
metadata:
name: example-nginx
spec:
type: NodePort
ports:
- port: 80
targetPort: 80
selector:
app: example-nginx
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-nginx
spec:
replicas: 1
selector:
matchLabels:
app: example-nginx
template:
metadata:
labels:
app: example-nginx
spec:
containers:
- name: example-nginx
image: nginx:latest
ports:
- containerPort: 80
This YAML manifest is for a basic NGINX web server. It defines two services: “example-nginx” and “app”. The “app” service represents the actual application, which in this case is an HTTP(s) server listening on port 80.
You can use this YAML file as a starting point to build your own Kubernetes applications. For example, you could create a deployment for a fully-fledged application, or you could use it as a template for a more simplified solution (like an Ingress controller).
Notes on tinydolphin results
Frankly this second version from the Pod was quite good. Yes, it took about 8 minutes to generate, but it’s technically accurate and complete.
I tried Zephyr next on the WSL instance with a GPU. I’ll put them verbatim as they include markdown…
Zephyr Results:
Here’s a simple YAML manifest for deploying an NGINX-based web server on Kubernetes. This assumes that you already have
an image built and tagged in your registry with the name my-web-server:latest. Make sure to replace the placeholder
values below with appropriate ones for your setup:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-web-server
spec:
replicas: 3
selector:
matchLabels:
app: my-web-server
template:
metadata:
labels:
app: my-web-server
spec:
containers:
- name: nginx
image: my-registry/my-web-server:latest
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: my-web-server-service
spec:
type: ClusterIP
selector:
app: my-web-server
ports:
- port: 80
This manifest creates a Deployment with three replicas labeled as app: my-web-server, which uses an NGINX container
image from your registry. It also creates a Service of type ClusterIP that exposes the container’s port 80. The
selector field in both objects ensures that they are bound together and work correctly as a whole. You can apply this
YAML manifest to your Kubernetes cluster using the following command:
kubectl apply -f my-web-server.yaml
This will create the deployment and service resources on your Kubernetes cluster, making your NGINX web server accessible
through the ClusterIP created by the Service. You can access the service using its assigned IP address, which you can
get with:
kubectl get svc my-web-server-service -o jsonpath='{.status.loadBalancer.ingress[0].ip}'`
Now you can hit this URL in your browser to access the web server: `http://<CLUSTER_IP>:80`.
Notes
This is mostly right, except I would have hoped it would have given me a container with nginx instead of a placeholder “my-registry/my-web-server:latest”
Using a Model meant for code
At this point, we’ll stick with my gaming computer which while moderate, at least has a GPU.
There are a lot of models we can see on the library page.
It can be beneficial to pick a model that closer aligns to what you are trying to accomplish.
For instance, I pulled down the codellama model to focus specifically on coding
builder@DESKTOP-QADGF36:~$ ollama run codellama
pulling manifest
pulling 3a43f93b78ec... 100% ▕███████████████████████████████████████████████████████████████▏ 3.8 GB
pulling 8c17c2ebb0ea... 100% ▕███████████████████████████████████████████████████████████████▏ 7.0 KB
pulling 590d74a5569b... 100% ▕███████████████████████████████████████████████████████████████▏ 4.8 KB
pulling 2e0493f67d0c... 100% ▕███████████████████████████████████████████████████████████████▏ 59 B
pulling 7f6a57943a88... 100% ▕███████████████████████████████████████████████████████████████▏ 120 B
pulling 316526ac7323... 100% ▕███████████████████████████████████████████████████████████████▏ 529 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
Let’s now ask for a Kubernetes Nginx manifest
This worked great. It was different than the rest as well, having created both a deployment YAML manifest for the containerized web server, but also highlighting the ‘kubectl expose’ command which gives us some flexibility on service type (such as NodePort, LoadBalancer or ClusterIP).
Let’s now throw some Python at it. Something I find myself doing more and more nowadays is creating a quick flask-based container to do some kind of function.
This worked amazing, up until I asked for the test payload and it neglected to add /fetch to the URL - but it’s really quite close. This is a series of 4 back-to-back prompts that rely on the prior contexts to succeed:
Python Test (with markdown)
>>> create a python flask based container that exposes the endpoint /fetch on HTTP get to return the text "seems like it works
... captain"
from flask import Flask, request
app = Flask(__name__)
@app.route('/fetch', methods=['GET'])
def fetch():
return "seems like it works captain"
if __name__ == '__main__':
app.run(debug=True)
This is a simple Python script that creates a Flask application with a single endpoint /fetch that returns the string
“seems like it works captain” when called using an HTTP GET request. The app.run(debug=True) line starts the Flask
development server, which allows you to test your application by visiting http://localhost:5000/fetch in a web browser
or sending an HTTP request with curl.
>>> what is the requirements.txt for that?
The requirements.txt file for the Python Flask application would contain the following line:
Flask==1.1.2
This specifies the version of the Flask library to be installed when running the pip install -r requirements.txt
command. The pip package manager will then download and install the specified version of Flask, as well as any other
dependencies required by your application.
>>> what would the Dockerfile look like?
The Dockerfile for a Python Flask application would typically look something like this:
FROM python:3.9-slim-buster
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 5000
CMD ["flask", "run", "-h", "0.0.0.0"]
This file specifies the base image to use (in this case, a Python 3.9 slim-buster image), sets the working directory,
copies the requirements.txt file into the container, installs any dependencies required by your application using
pip, copies the current directory contents into the container, exposes port 5000 for the Flask development server, and
sets the command to run the Flask development server.
You can then build and run this image using Docker:
$ docker build -t my-flask-app .
$ docker run -p 5000:5000 my-flask-app
This will build a Docker image from the Dockerfile in the current directory, and then start a container running the
my-flask-app image on port 5000. You can then visit http://localhost:5000/ in a web browser to see your Flask
application in action.
>>> How might i build and run this dockerfile as well as send it a test payload with curl?
To build the Docker image from the Dockerfile, you can use the following command:
$ docker build -t my-flask-app .
This will create a Docker image named “my-flask-app” based on the instructions in the Dockerfile in the current
directory.
To run the Docker container and expose port 5000 for the Flask development server, you can use the following command:
$ docker run -p 5000:5000 my-flask-app
This will start a new container running the “my-flask-app” image and map port 5000 on the host to port 5000 in the container.
To test your application with curl, you can send an HTTP GET request to http://localhost:5000/ and receive the response
from the Flask development server:
$ curl http://localhost:5000/
This will send a GET request to the root URL of your application, which should return the string “seems like it works
captain” as defined in the fetch() function in the previous example.
Older code
One of the challenges I have found, really across the internet as a whole, is the short term memory - older languages are harder with which to acchieve positive results:
For instance, asking
show me a Perl basic script for serving an HTTP server that returns "hello there" on HTTP GET to /fetch
This coding model showed me some code for ‘Plack Middleware”
#!/usr/bin/env perl
use strict;
use warnings;
use Plack::Builder;
builder {
enable 'Plack::Middleware::ContentType';
enable 'Plack::Middleware::Static', { path => '/static' };
enable 'Plack::Middleware::ConditionalGET';
enable 'Plack::Middleware::MethodOverride';
enable 'Plack::Middleware::ReverseProxy';
enable 'Plack::Middleware::Session',
store => 'File::Store',
accessor => 'session_id';
enable 'Plack::Middleware::XSendfile';
enable 'Plack::Middleware::XRealIP';
enable 'Plack::Middleware::ErrorDocument';
enable 'Plack::Middleware::ContentType';
mount '/fetch' => sub {
my $env = shift;
return [ 200, ['Content-Type' => 'text/plain'], ["hello there"] ];
};
};
and wanted me to invoke with a plackup piece of middleware:
$ plackup -MPlack::App::Builder ./script.pl
Zephyr response:
Here’s a basic Perl script to create an HTTP server that responds with “Hello There!” when you make an HTTP GET request
to the root URL (/) or /fetch.
First, let’s define our handler function:
sub serve_request {
my ($env) = @_;
# Set default response status and headers
$env->{'HTTP_RESPONSE_CODE'} = '200 OK';
$env->{'CONTENT_TYPE'} = 'text/plain; charset=UTF-8';
my $uri = $env->{'REQUEST_URI'};
# Handle requests for the root URL (/) and /fetch
if ($uri eq '/') {
$env->{'QUERY_STRING'} = '' unless $env->{'QUERY_STRING'};
print "Hello There!\n";
return;
} elsif ($uri eq '/fetch') {
my $body = 'Hello There!';
my $headers = "HTTP/1.1 200 OK\r\nContent-Type: text/plain; charset=UTF-8\r\nContent-Length: " . Length($body) .
"\r\n";
print "$headers$body\r\n";
return;
}
# Handle other requests with a 404 error response
$env->{'HTTP_RESPONSE_CODE'} = '404 Not Found';
print "Not found!\n";
}
The serve_request function is called by the server, passing in an environment hash containing all the details about the
request. We set some default values for the response status and headers, handle requests for the root URL and /fetch,
and return a 404 error response for other requests.
Next, we’ll create our HTTP server:
use IO::Socket;
use ForkManager;
my $server = IO::Socket->new(LocalPort => 80) or die "Cannot open server socket: $!\n";
my $manager = new ForkManager(5);
sub cleanup { close($_[0]]) for values %{$ENV{SOCKETS}}; }
$SIG{CHLD} = \&cleanup;
while (my $client = $server->accept()) {
my $pid = $manager->start() or next;
# Set up environment hash and pass to our handler function
my %env = ('HTTP_USER_AGENT' => "Mozilla/5.0 (Windows NT 10.0; Win64; x64)", 'REQUEST_METHOD' => 'GET',
'QUERY_STRING' => '', 'SERVER_PROTOCOL' => 'HTTP/1.1', 'PATH_INFO' => '/', 'REMOTE_ADDR' => '127.0.0.1', 'SERVER_PORT' =>
'80', 'REQUEST_URI' => '/');
serve_request(\%env);
close($client);
}
We create a new IO::Socket on port 80, set up a ForkManager to manage child processes, register our cleanup
subroutine for CHLD signals, and enter the server loop. We fork off a new process for each incoming client request and
pass an environment hash (initialized with some default values) to our serve_request function. Finally, we close the
socket after serving the request.
Save this script as httpd.pl, make it executable (chmod +x httpd.pl), and run it (./httpd.pl). You can then access
your HTTP server by making a GET request to http://localhost/ or http://localhost/fetch.
Zephyr Notes
The Zephyr Model was actually better - yes, longer, but more accurate
TinyDolphin
I will just show the code, which is Perl, but not a webserver in the slightest
Here’s a Perl basic script for serving an HTTP server that returns “Hello, there” on GET to ‘/fetch’:
#!/usr/bin/perl
use strict;
use warnings;
my $prompt = "Enter your name: ";
while(<>) {
my $name = <STDIN>;
$name =~ s/\n//g;
print "$name\n";
}
sub fetch {
return "Hello, $_[0]!";
}
sub main {
my ($prompt) = @_;
my $name = <>; # Read user input and store in variable
print "Fetching user: $name\n";
return fetch($prompt); # Call function to get response
}
# Execute the script when invoked with arguments
if ($#ARGV > 0) {
main @ARGV;
} else {
main();
}
Gemini (free)
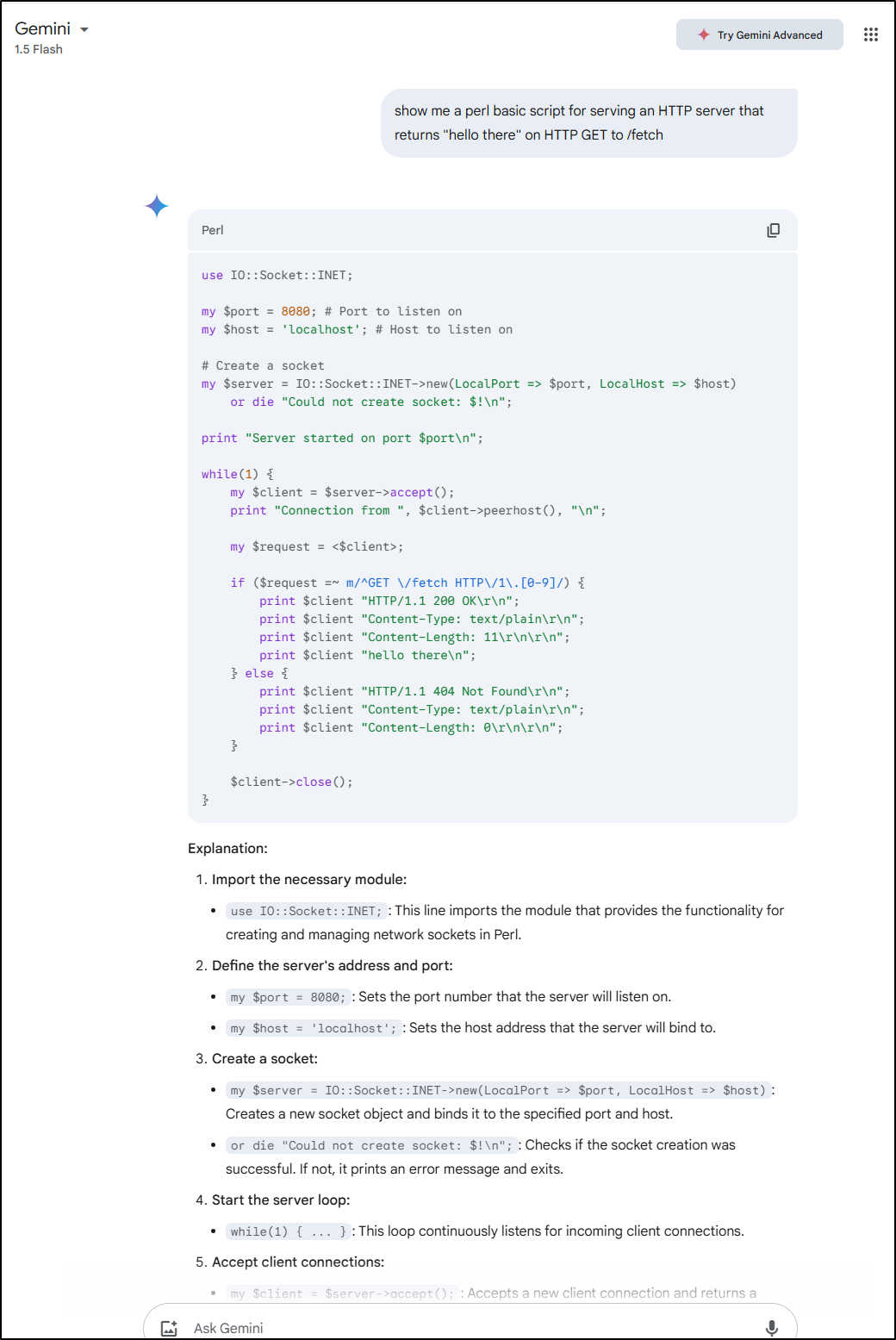
Let’s fire it Gemini and see
I also tried the other free-to-me model, 2.0 flash experimental
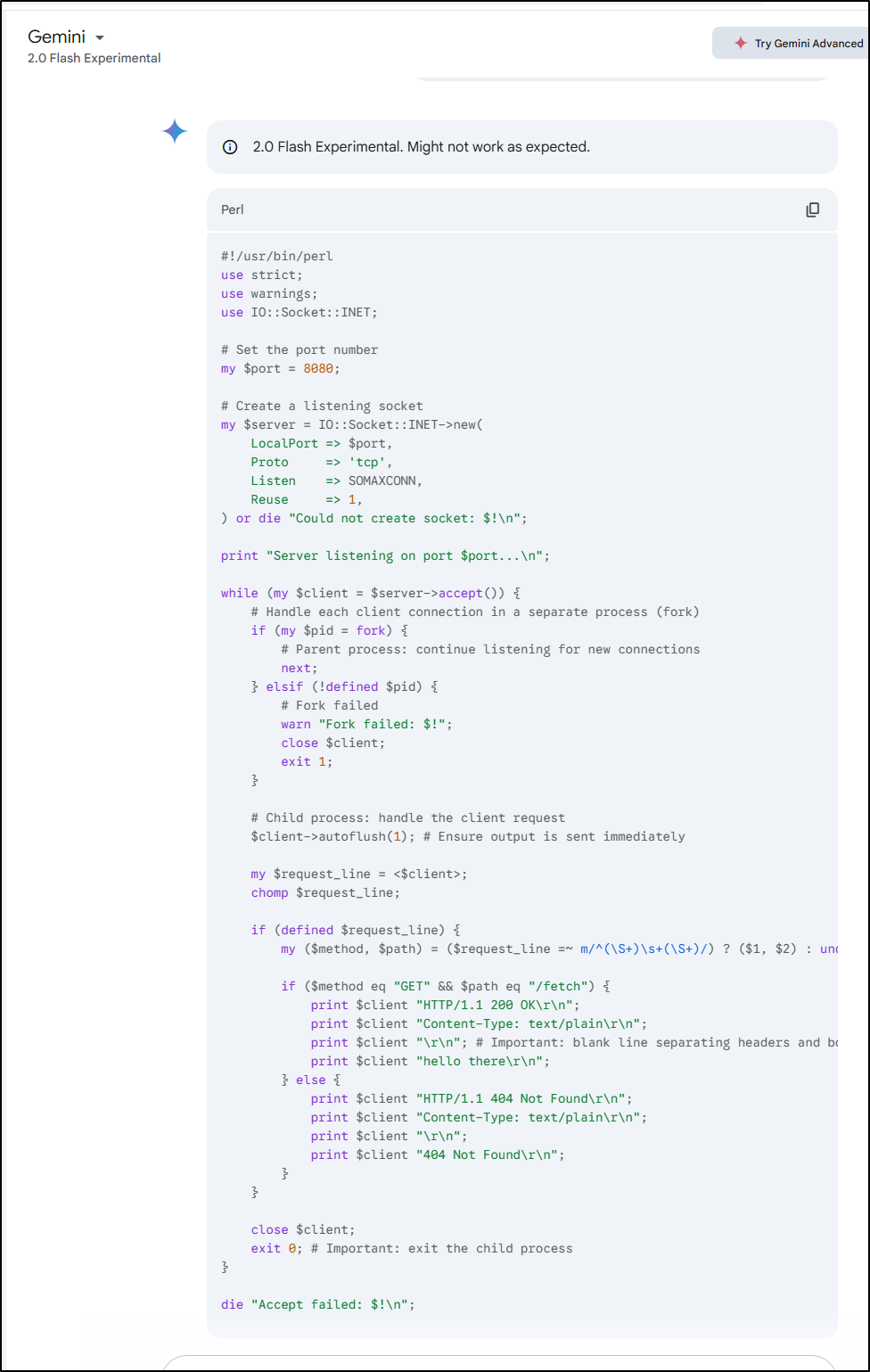
I like the concurrency and flush they included, but it’s adding a lot I didn’t ask for including HTTP response headers as output text.
CoPilot (free)
I thought we might as well fire it at Co-pilot (free in Windows) to see if it works. It used the HTTP::Daemon as I likely would - or at least a simple CPAN library as I might.

#!/usr/bin/perl
use strict;
use warnings;
use HTTP::Daemon;
use HTTP::Status;
# Create a new HTTP server listening on port 8080
my $d = HTTP::Daemon->new(LocalPort => 8080) || die "Cannot create HTTP::Daemon: $!";
print "Server is running at: ", $d->url, "\n";
while (my $c = $d->accept) {
while (my $r = $c->get_request) {
if ($r->method eq 'GET' and $r->uri->path eq "/fetch") {
# Respond with "hello there" to GET /fetch
$c->send_response(HTTP::Response->new(RC_OK, 'OK', ['Content-Type' => 'text/plain'], "hello there"));
}
else {
# Respond with 404 Not Found for other requests
$c->send_error(RC_NOT_FOUND);
}
}
$c->close;
undef($c);
}
Actually, this looks pretty good. As a Perl programmer, I love using lots and lots of -> and having things on one line. Tight code is right code.
It’s not perfect, but using HTTP::Daemon would definately be an option I consider.
Summary
It’s clear Ollama has some benefits. I haven’t done anything more at this time then try some models over a variety of hosts. My goal was to test Ollama on Pis, Kubernetes and a host with a GPU. I tried the smallest model (tinydolphin) as well as Zephyr and Codellama.
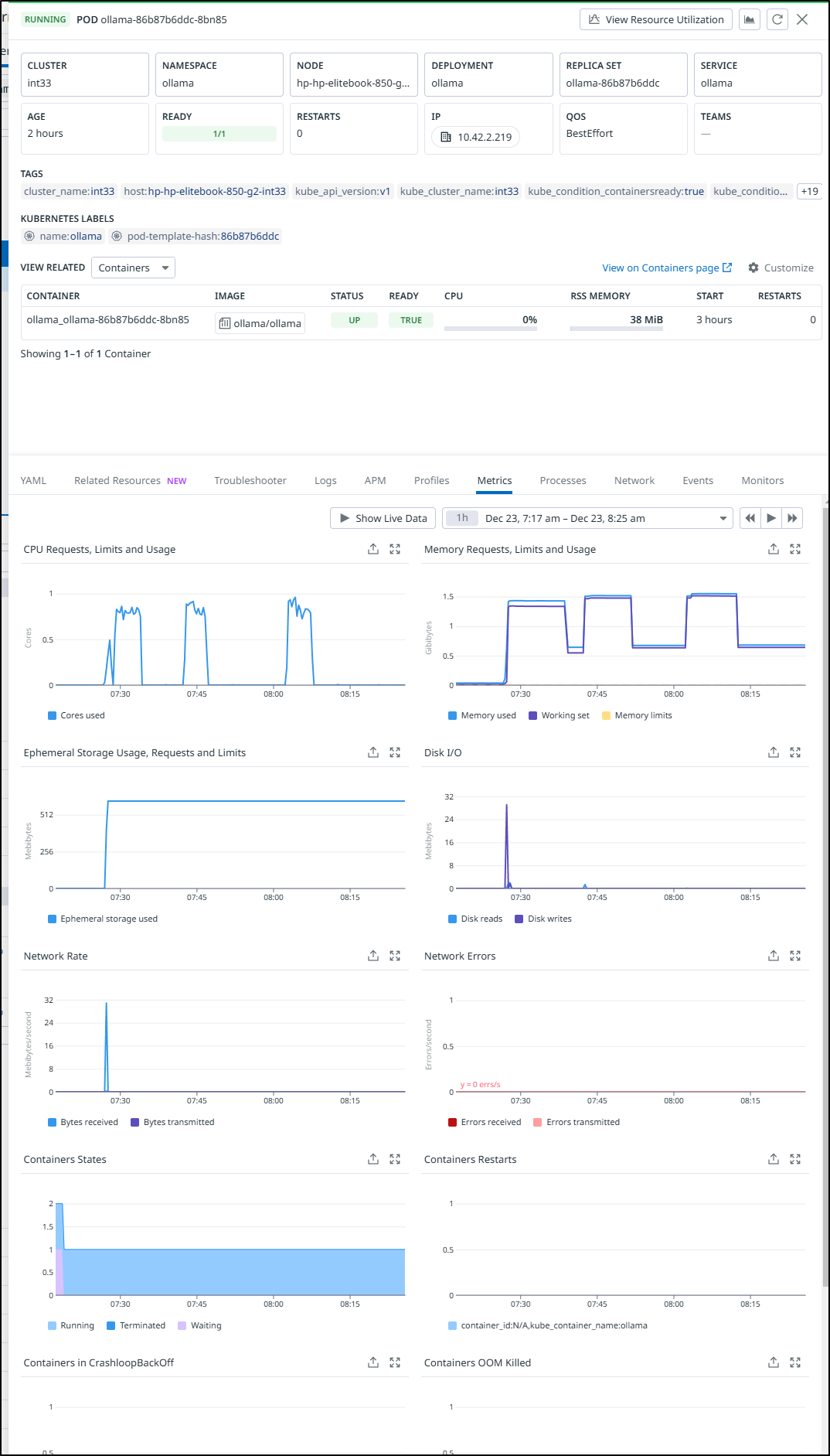
Looking at the Pod in Datadog, it does not look like it consumed much past 1.5Gb
Next, I’ll want to talk about tying our own library in as well as using code, like Python to engage with LLMs we host. The term for this is ‘RAG’ (Retrieval-Augmented Generation) which basically means taking a pre-trained model - be it hosted by ourselves or externally like ChatGPT and then adding our data as ‘context’ to the model.
Addenedum: My Thoughts on AI Hype
I’m bearish at best when it comes to the use of AI in a real and meaningful way. I do not think it will solve all our problems and when I see things like AI in MS Paint, it makes me chuckle. AI is a tool and it’s got soooooo much hype, everyone is trying to jamb it in everywhere to solve things (or just plain confuse things).
Years ago I worked at a company that made MiFi hotspots. And in that time, blue LEDs started to show up. It was a unique wavelength and up until 2010 or so, we didn’t really see that odd spectrum blue LED anywhere. So, of course, we had to jamb stupid blue lights in all our new devices. I asked about this “why are we replacing a clearly green ‘on’ light with blue”. The answer was we just had to add the new blue LEDs everywhere because they were hip and “people think blue is high tech”. For those of you old enough, you can recall when in 2010 to 2015 or so, every damn new tech product had blue lights for no good reason.
AI are blue lights. There are times that blue can be good, and we can use some fresh blue. But there are times it’s just plain hype. And whether its a tech trend like “DevOps” or “Synergy” or “Cloud”, or something physical like “Blue LEDs”. The hype will eventually fade. We will use the tools, of course, but I should hope just for that which adds actual value.
