

Published: Jul 2, 2024 by Isaac Johnson
I think ScrapingAnt landed in my “things to check out” from a web advert. I recently had some cycles to signup and give it a go. I’ll explore the WebUI as well as using ScrapingAnt with curl.
I found ScrapingBee, which while it seems a copy, actually came out just shortly before ScrapingAnt. It too offers webscraping as a service. We’ll signup and try it as well.
Lastly, we’ll compare prices of these two small SaaS services before wrapping up.
Scraping Ant Signup
Let’s start with the free tier
I can signup wiht Github or Google. I’ll use the latter
I have now 10k API credits to use then I need to pay for a plan.
Let’s give it a try.
Say I want to track when new GDG events are happening in my area
I’ll start by entering that URL into the Request Generator. For now, I’ll leave it as a curl example
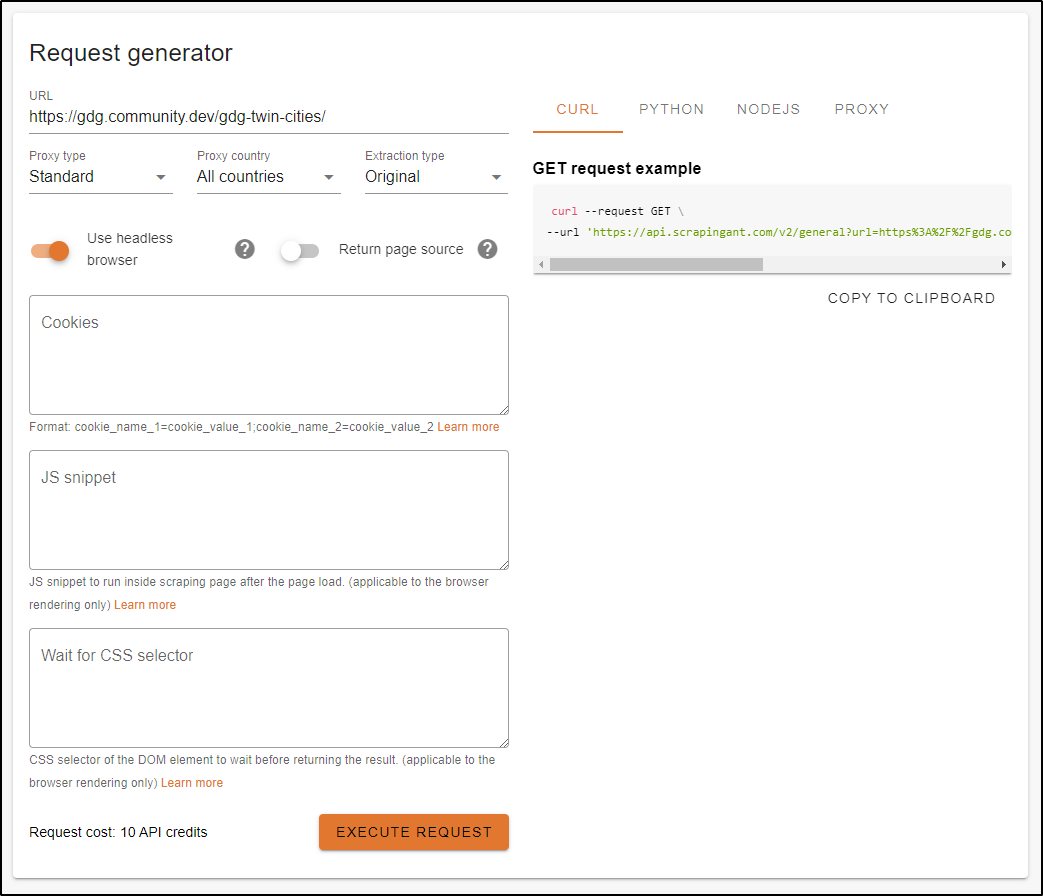
The request result cost 10 credits and just showed me the source HTML
Perhaps I need a JS Snippet?
I asked Gemini for help
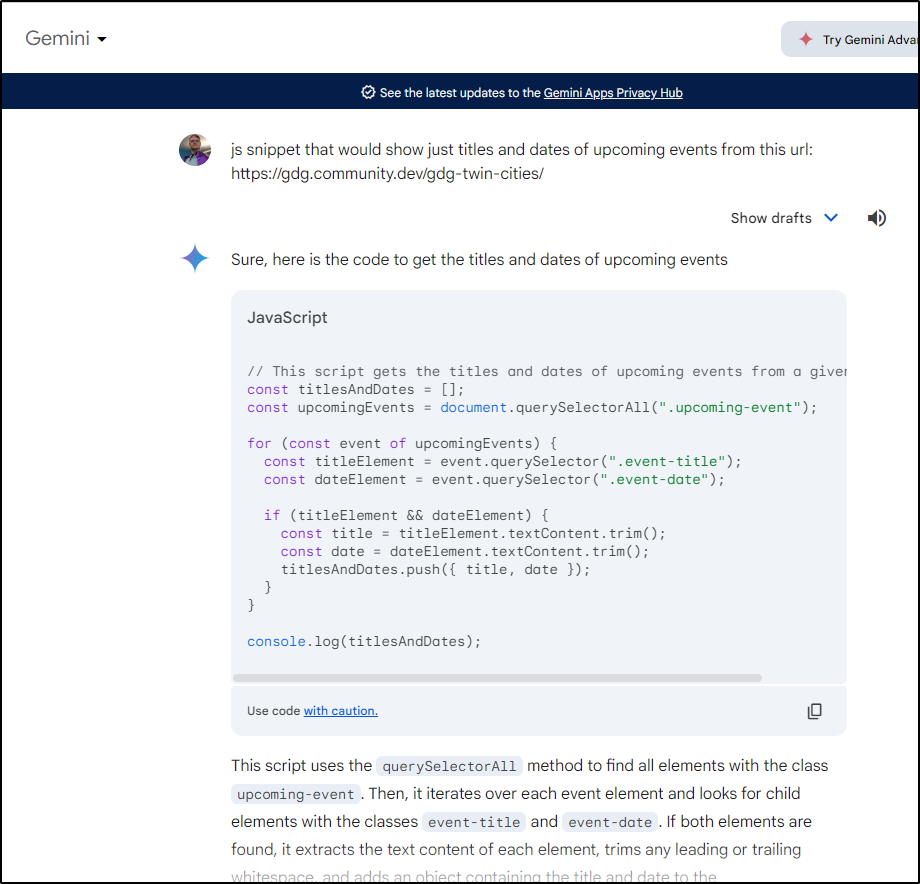
I plugged it in, but didn’t see any result after way more than a minute
Co-pilot gave me a different suggestion
fetch('https://gdg.community.dev/gdg-twin-cities/')
.then(response => response.text())
.then(html => {
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');
const events = doc.querySelectorAll('.event-item'); // Use the correct selector for event items
events.forEach(event => {
const title = event.querySelector('.event-title').innerText; // Use the correct selector for the title
const date = event.querySelector('.event-date').innerText; // Use the correct selector for the date
console.log(`Title: ${title}, Date: ${date}`);
});
})
.catch(error => {
console.error('Error fetching or parsing the content:', error);
});
Via API key
I can dump the output to a file
$ curl --request GET --url 'https://api.scrapingant.com/v2/general?url=https%3A%2F%2Fgdg.community.dev%2Fgdg-twin-cities%2F&x-api-key=d198b446e87d4126b93932a030233da1' > t.o
I could also parse out the specific parts I wanted, such as the new Sessions and dates:
$ curl --request GET --url 'https://api.scrapingant.com/v2/general?url=https%3A%2F%2Fgdg.community.dev%2Fgdg-twin-cities%2F&x-api-key=d198b446e87d4126b93932a030233da1' | grep -oE '"event_type_title":"[^"]+"|start_date":"[^"]+"|title":"[^"]+"' | awk -F':' '{
print $2}' | tr -d '"'
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 478k 100 478k 0 0 23799 0 0:00:20 0:00:20 --:--:-- 118k
GDG Twin Cities
Workshop / Study Group
2024-06-26T21
Build with AI
Speaker Session / Tech Talk
2024-06-26T14
GDG Cloud Southlake #34
Workshop / Study Group
2024-06-22T13
Build With AI, Fine Tuning Gemini
Workshop / Study Group
2024-06-19T21
Build with AI
Speaker Session / Tech Talk
2024-05-29T21
GDG Cloud Southlake #33
Executive Director of Technology Experience and CRM
Founding Organizer
Team Member
Application Developer, Consultant
Co Organizer
Tech Lead
Co Organizer
Co Organizer
GDG Twin Cities
GDG Twin Cities
Executive Director of Technology Experience and CRM
Founding Organizer
Team Member
Application Developer, Consultant
Co Organizer
Tech Lead
Co Organizer
Co Organizer
Workshop / Study Group
2024-06-26T21
Build with AI
Speaker Session / Tech Talk
2024-06-26T14
GDG Cloud Southlake #34
Workshop / Study Group
2024-06-22T13
Build With AI, Fine Tuning Gemini
Workshop / Study Group
2024-06-19T21
Build with AI
Speaker Session / Tech Talk
2024-05-29T21
GDG Cloud Southlake #33
Now, at this time, I can use the direct URL just as easy
$ curl --request GET --url 'https://gdg.community.dev/gdg-twin-cities/' | grep -oE '"event_type_title":"[^"]+"|start_date":"[^"]+"|title":"[^"]+"' | awk -F':' '{print $2}' | tr -d '"' % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 470k 100 470k 0 0 723k 0 --:--:-- --:--:-- --:--:-- 722k
GDG Twin Cities
Workshop / Study Group
2024-06-26T21
Build with AI
Speaker Session / Tech Talk
2024-06-26T14
GDG Cloud Southlake #34
Workshop / Study Group
2024-06-22T13
Build With AI, Fine Tuning Gemini
Workshop / Study Group
2024-06-19T21
Build with AI
Speaker Session / Tech Talk
2024-05-29T21
GDG Cloud Southlake #33
Executive Director of Technology Experience and CRM
Founding Organizer
Team Member
Application Developer, Consultant
Co Organizer
Tech Lead
Co Organizer
Co Organizer
GDG Twin Cities
GDG Twin Cities
Executive Director of Technology Experience and CRM
Founding Organizer
Team Member
Application Developer, Consultant
Co Organizer
Tech Lead
Co Organizer
Co Organizer
Workshop / Study Group
2024-06-26T21
Build with AI
Speaker Session / Tech Talk
2024-06-26T14
GDG Cloud Southlake #34
Workshop / Study Group
2024-06-22T13
Build With AI, Fine Tuning Gemini
Workshop / Study Group
2024-06-19T21
Build with AI
Speaker Session / Tech Talk
2024-05-29T21
GDG Cloud Southlake #33
We can send our request out from various endpoints
For instance, perhaps i send from China to find i cannot access the local GDG page
$ curl --request GET \
s://api.scraping> --url 'https://api.scrapingant.com/v2/extended?url=https%3A%2F%2Fgdg.community.dev%2Fgdg-twin-cities%2F&x-api-key=d198b446e0233da1&proxy_country=CN'
{"detail":"This site can’t be reached"}
But then I see my own site can:
$ curl --request GET --url 'https://api.scrapingant.com/v2/extended?url=https%3A%2F%2Ffreshbrewed.science&x-api-key=d198b446e87d4126b93932a030233da1&proxy_country=CN'
{"html":"<!DOCTYPE html><html class=\"fontawesome-i2svg-active fontawesome-i2svg-complete\"><head>\n <meta charset=\"utf-8\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <title>Fresh/Brewed - Fresh/Brewed</title>\n <style type=\"text/css\">svg:not(:root).svg-inline--fa{overflow:visible}.svg-inline--fa{display:inline-block;font-size:inherit;height:1em;overflow:visible;vertical-align:-.125em}.svg-inline--fa.fa-lg{vertical-align:-.225em}.svg-inline--fa.fa-w-1{width:.0625em}.svg-inline--fa.fa-w-2{width:.125em}.svg-inline--fa.fa-w-3{width:.1875em}.svg-inline--fa.fa-w-4{width:.25em}.svg-inline--fa.fa-w-5{width:.3125em}.svg-inline--fa.fa-w-6{width:.375em}.svg-inline--fa.fa-w-7{width:.4375em}.svg-inline--fa.fa-w-8{width:.5em}.svg-inline--fa.fa-w-9{width:.5625em}.svg-inline--fa.fa-w-10{width:.625em}.svg-inline--fa.fa-w-11{width:.6875em}.svg-inline--fa.fa-w-12{width:.75em}... snip....
Pricing
We can see there are various tiers of pricing today
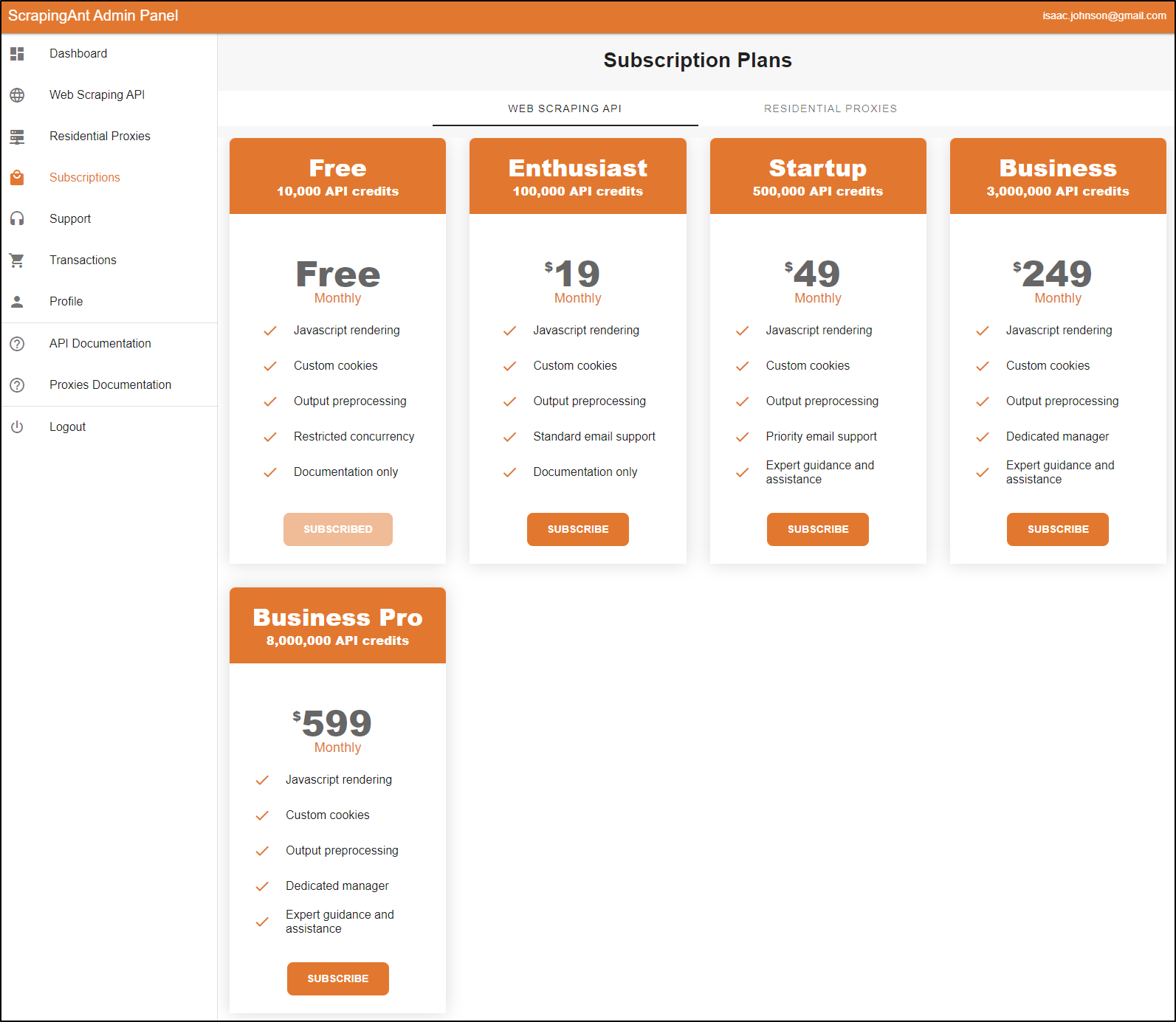
Most requests I notice take 10 credits. So we can roughly translate the lowest tier ‘Enthusiast’ “100,000 API Credits” is 10k requests for US $20/mo.
Scraping Bee
We can signup for Scraping Bee in much the same way. It has similar layout and for a bit I suspected it was the same site with different design aesthetics.
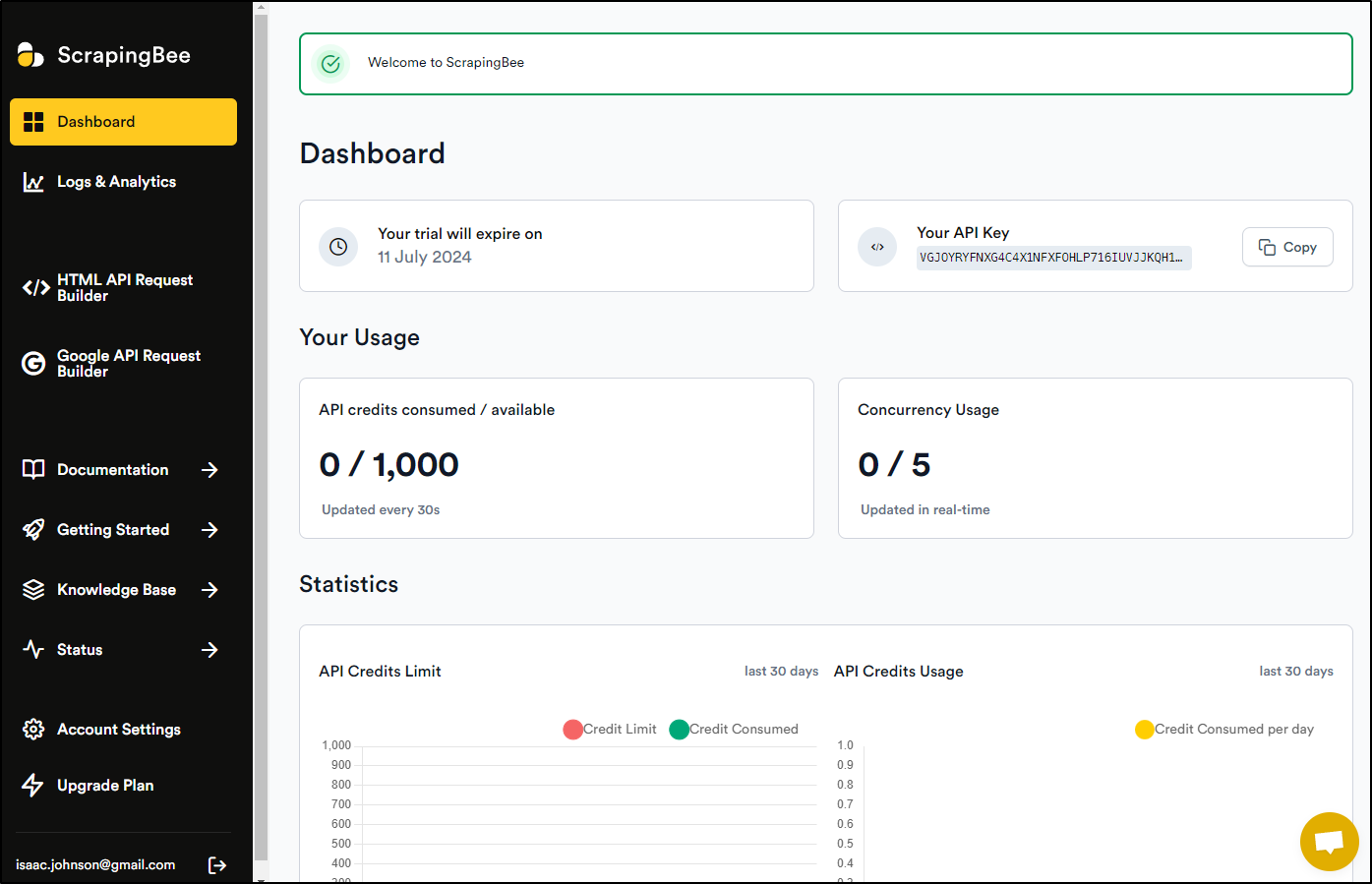
We can use our API key with curl like we did before
$ curl --request GET --url "https://app.scrapingbee.com/api/v1/?api_key=VGJOYRYFNXG4C4X1NFXFOHLP716IUVJJKQH1KWT4M194BQW1KTFKGF9TOJCN2ERAYN0R4D9DB46NUQ54&url=https%3A%2F%2Ffreshbrewed.science"
<!DOCTYPE html><html class="fontawesome-i2svg-pending"><head>
<meta charset="utf-8"> ... snip ...
We can use Geolocation to set the country code (albeit as a premium proxy)
For example, pulling from Germany:
$ curl --request GET --url "https://app.scrapingbee.com/api/v1/?api_key=VGJOYRYFNXG4C4X1NFXFOHLP716IUVJJKQH1KWT4M194BQW1KTFKGF9TOJCN2ERAYN0R4D9DB46NUQ54&premium_proxy=true&country_code=de&url=https%3A%2F%2Ffreshbrewed.science"
<!DOCTYPE html><html class="fontawesome-i2svg-pending"><head>
<meta charset="utf-8"> ... snip ..
We can also use an even more expensive (by way of credits) option of a “Stealth Proxy” meant to bypass blocks
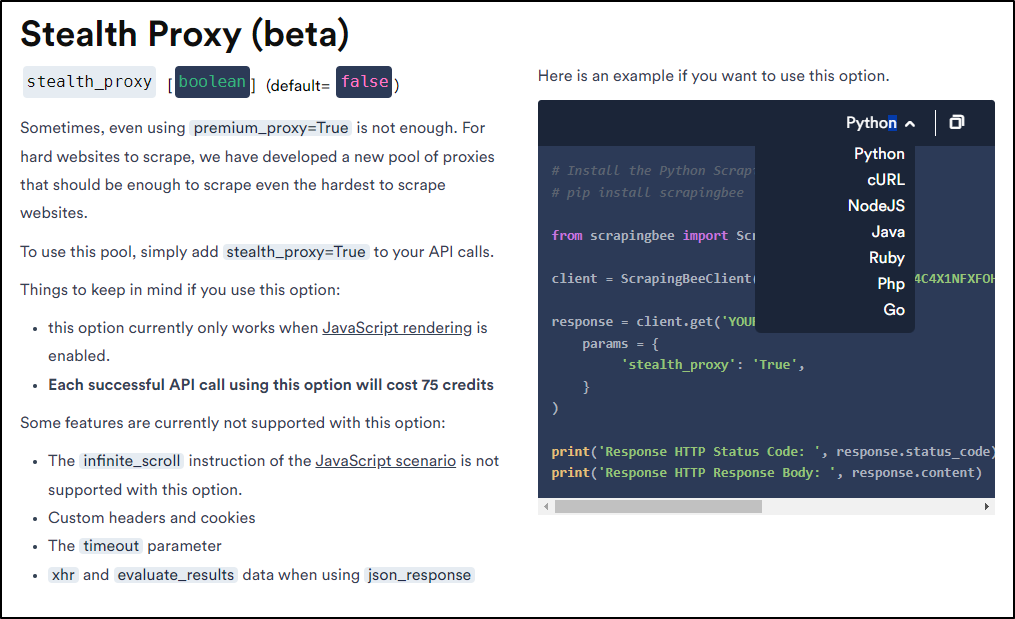
They also have “Pure Header Forwarding” that can let us pass headers.
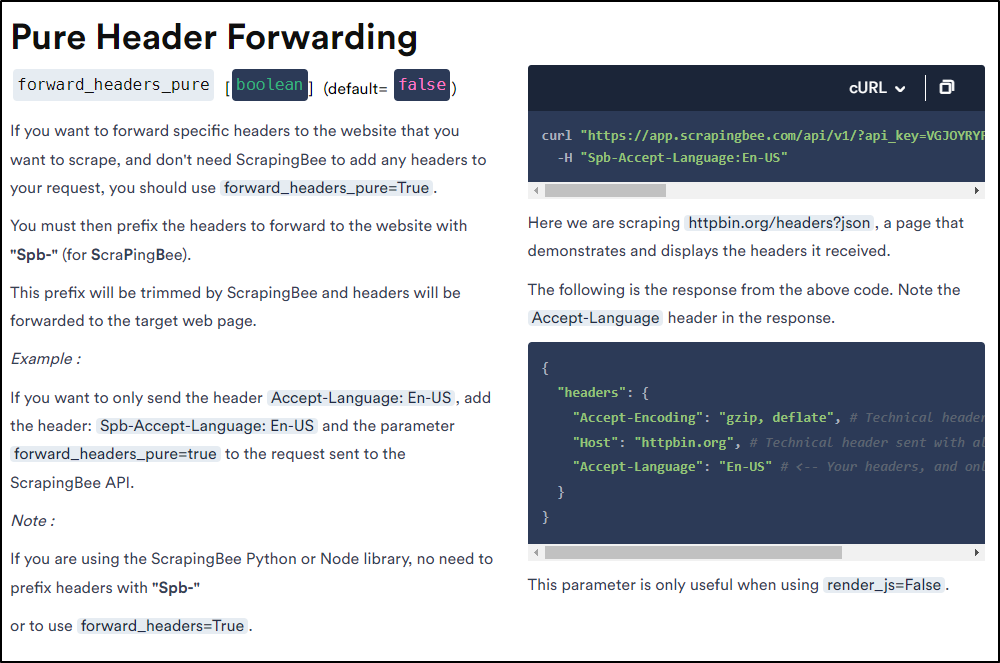
For instance, say i desired to send OTLP tracing spans to New Relic from different locations.
I could use:
curl -X POST --url "https://app.scrapingbee.com/api/v1/?api_key=VGJOYRYFNXG4C4X1NFXFOHLP716IUVJJKQH1KWT4M194BQW1KTFKGF9TOJCN2ERAYN0R4D9DB46NUQ54&url=http%3A%2F%2Fotlp.nr-data.net%2Fheaders%3Fjson&forward_headers_pure=true" \
-H "Spb-api-key=xxxxxxxxxxxxxxxxxxxxxNRAL" --data @span.json
Note: i did show my key above, but I rotated it after writing so it is now outdated
Pricing
We can see ScrapingBee pricing
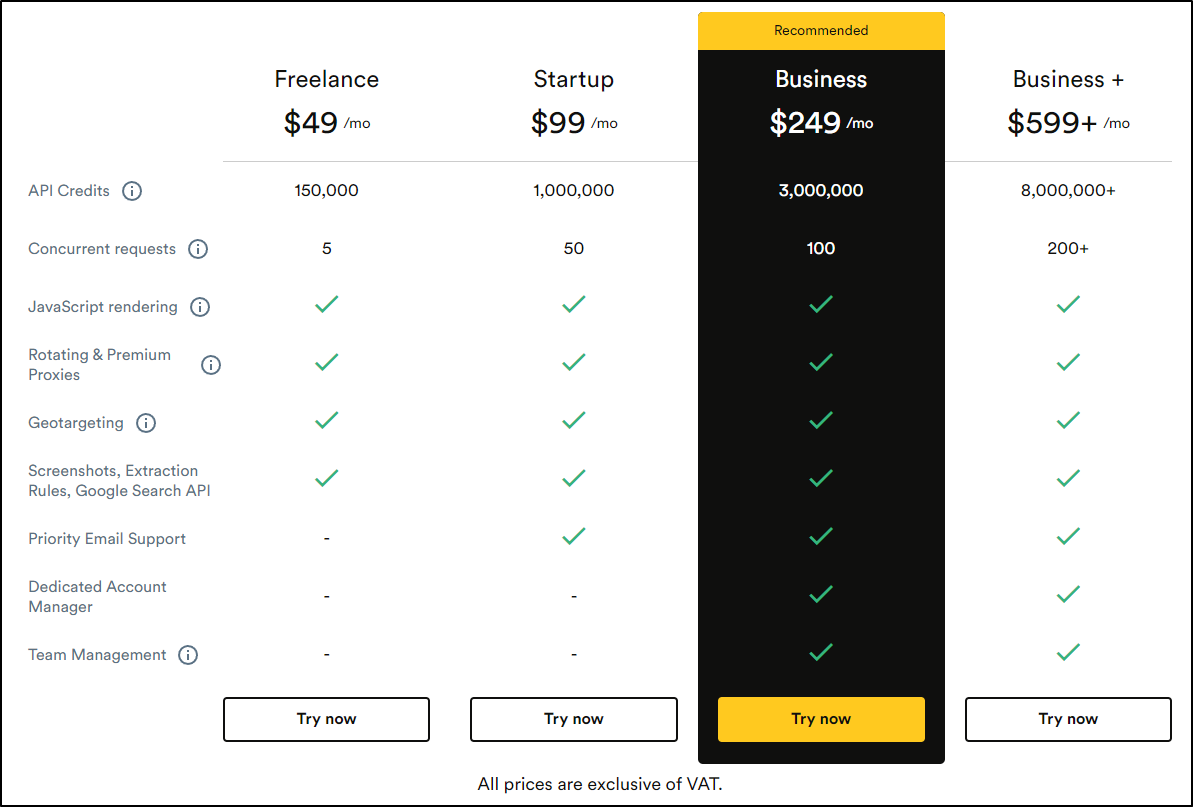
So basic queries would be roughly 15k/mo for $50.
Companies
I see a Crunchbase for Scraping Bee pointed to France with 1-10 employees. Looking at Pierre de Wulf, one of the co-founders, profile, it has been around since July 2019.
I was surprised to find the Founder of ScrapingAnt, which according to LinkedIn has 3 employees, is the creation of Oleh Kulyk around Apr 2020.
While similarly named, I think it’s more happenstance than anything.
I found this Scrapeway breakdown that compares the two.
Comparing
I might consider making AWS Lambdas to do the same thing. For AWS, we can get 1mil requests and 888 hours of compute time for free.
Google also makes CloudRun free for the first 180k or 240k cpu seconds a month.
Summary
I actually think both tools offer a compelling product. ScrapingAnt has the cheapest offering of $19/mo but can charge for a blocked request so that cheap price might be comparing like for like. ScrapingBee has a large featureset but lacks unlimited concurrency so the Ant would be better if one has to scale out in parallel often.
Since I use Python and Javascript most often, both are supported as first-class languages in Ant and Bee. Both let me head out of different companies. Since neither let you carry credits, whatever you pay-for is what you get in the month.
If price is the main point, the Bee gives about 300 requests for US$1 compared to 500 for the same price by way of the Ant. As I mentioned, one can also code-your-own with Lambda, CloudRun or Azure Functions as well.
