

Published: Nov 25, 2023 by Isaac Johnson
Recently, I hopped on my Immich site and found that a crashing pod was holding the whole system up. I decided to write up how to find and fix as this has happened to me before on other containerized services that have local file dependencies.
It was also a good opportunities to build out a basic site watcher using scheduled jobs in AWX (using bash, PagerDuty and Resend.dev).
The Problem
Simply put, I found the site was down.
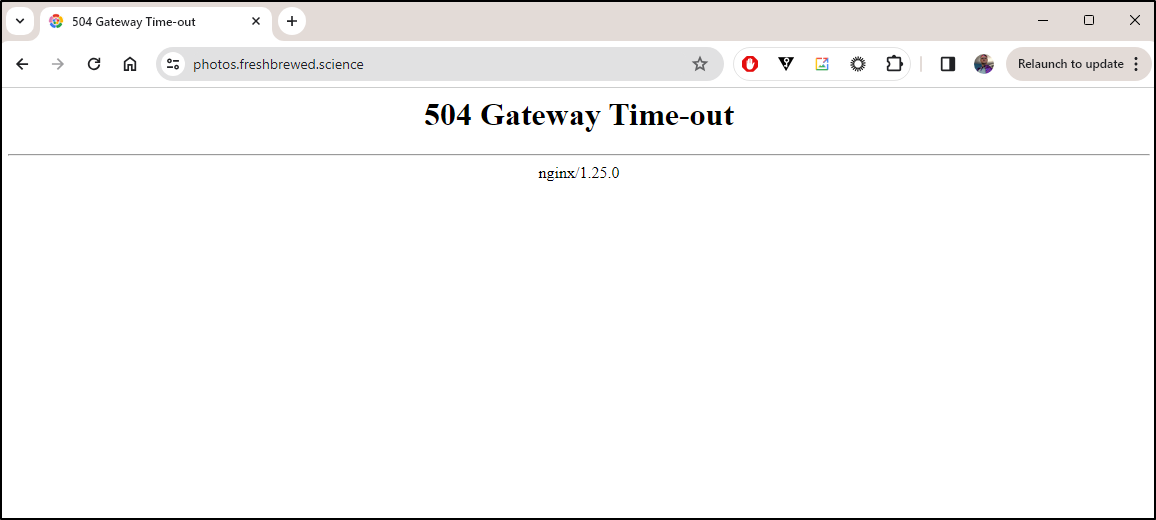
I panicked that it was due to a cluster crash, which happens at times.
Looking into the pods in the namespace:
$ kubectl get pods -n immich
NAME READY STATUS RESTARTS AGE
immichprod-redis-master-0 1/1 Running 0 5d18h
immichprod-web-dd4b87954-g2n56 1/1 Running 0 21d
immichprod-machine-learning-75d84dd96f-rzswr 1/1 Running 0 5d18h
immichprod-postgresql-0 1/1 Running 0 21d
immichprod-proxy-764698ffb4-ncmst 1/1 Running 12 (4d16h ago) 5d18h
immichprod-typesense-55bf4bd8d6-z77zc 0/1 CrashLoopBackOff 1633 (109s ago) 5d18h
immichprod-server-c6698b848-lxs59 0/1 Running 2132 (5m56s ago) 5d18h
immichprod-microservices-5b969c856d-2wnq8 1/1 Running 917 (5m43s ago) 5d18h
I could see two were stuck in a crashloop.
My first try is to always just rotate them and see if they come back up:
$ kubectl delete pod immichprod-typesense-55bf4bd8d6-z77zc -n immich && kubectl delete pod immichprod-server-c6698b848-lxs59 -n immich
pod "immichprod-typesense-55bf4bd8d6-z77zc" deleted
pod "immichprod-server-c6698b848-lxs59" deleted
$ kubectl get pods -n immich
NAME READY STATUS RESTARTS AGE
immichprod-redis-master-0 1/1 Running 0 5d18h
immichprod-web-dd4b87954-g2n56 1/1 Running 0 21d
immichprod-machine-learning-75d84dd96f-rzswr 1/1 Running 0 5d18h
immichprod-postgresql-0 1/1 Running 0 21d
immichprod-proxy-764698ffb4-ncmst 1/1 Running 12 (4d16h ago) 5d18h
immichprod-microservices-5b969c856d-2wnq8 1/1 Running 917 (7m10s ago) 5d18h
immichprod-server-c6698b848-7nlj4 0/1 Running 0 46s
immichprod-typesense-55bf4bd8d6-sg49p 0/1 CrashLoopBackOff 2 (15s ago) 48s
The logs were do to a local filesystem DB being open when a pod crashed (likely during a forced reboot)
$ kubectl logs immichprod-typesense-55bf4bd8d6-sg49p -n immich
I20231121 11:49:56.728648 1 typesense_server_utils.cpp:357] Starting Typesense 0.24.0
I20231121 11:49:56.728678 1 typesense_server_utils.cpp:360] Typesense is using jemalloc.
I20231121 11:49:56.728938 1 typesense_server_utils.cpp:409] Thread pool size: 32
I20231121 11:49:56.732545 1 store.h:63] Initializing DB by opening state dir: /tsdata/db
E20231121 11:49:56.744969 1 store.h:67] Error while initializing store: IO error: While lock file: /tsdata/db/LOCK: Resource temporarily unavailable
E20231121 11:49:56.744992 1 store.h:69] It seems like the data directory /tsdata/db is already being used by another Typesense server.
E20231121 11:49:56.744998 1 store.h:71] If you are SURE that this is not the case, delete the LOCK file in the data db directory and try again.
I20231121 11:49:56.745041 1 store.h:63] Initializing DB by opening state dir: /tsdata/meta
E20231121 11:49:56.768613 1 store.h:67] Error while initializing store: IO error: While lock file: /tsdata/meta/LOCK: Resource temporarily unavailable
E20231121 11:49:56.768626 1 store.h:69] It seems like the data directory /tsdata/meta is already being used by another Typesense server.
E20231121 11:49:56.768631 1 store.h:71] If you are SURE that this is not the case, delete the LOCK file in the data db directory and try again.
E20231121 11:49:56.894925 1 backward.hpp:4199] Stack trace (most recent call last):
E20231121 11:49:56.894938 1 backward.hpp:4199] #5 Object "/opt/typesense-server", at 0x4c8f50, in _start
E20231121 11:49:56.894943 1 backward.hpp:4199] #4 Object "/usr/lib/x86_64-linux-gnu/libc-2.31.so", at 0x7fe50f528082, in __libc_start_main
E20231121 11:49:56.894946 1 backward.hpp:4199] #3 Source "/typesense/src/main/typesense_server.cpp", line 160, in main [0x4999b2]
E20231121 11:49:56.894950 1 backward.hpp:4199] #2 Source "/typesense/src/typesense_server_utils.cpp", line 452, in run_server [0x6f2d8c]
E20231121 11:49:56.894954 1 backward.hpp:4199] #1 Source "/typesense/src/ratelimit_manager.cpp", line 429, in init [0x6cc5a8]
E20231121 11:49:56.894968 1 backward.hpp:4199] #0 Source "/typesense/include/store.h", line 154, in get [0x4ec6ef]
Segmentation fault (Address not mapped to object [(nil)])
E20231121 11:49:57.017424 1 typesense_server.cpp:102] Typesense 0.24.0 is terminating abruptly.
I’ve had this happen before - never fun. But this is solvable.
First, let’s get the YAML for the pod
$ kubectl get pod immichprod-typesense-55bf4bd8d6-sg49p -n immich -o yaml
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2023-11-21T11:49:24Z"
generateName: immichprod-typesense-55bf4bd8d6-
labels:
app.kubernetes.io/instance: immichprod
app.kubernetes.io/name: typesense
pod-template-hash: 55bf4bd8d6
name: immichprod-typesense-55bf4bd8d6-sg49p
namespace: immich
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: immichprod-typesense-55bf4bd8d6
uid: f3e9941f-61f1-41eb-aafa-d5eff526f4a6
resourceVersion: "270227029"
uid: 4e7d3022-468e-4855-800d-75d45863a8bc
spec:
automountServiceAccountToken: true
containers:
- env:
- name: DB_DATABASE_NAME
value: immich
- name: DB_HOSTNAME
value: immichprod-postgresql
- name: DB_PASSWORD
value: notthepassword
- name: DB_USERNAME
value: immich
- name: IMMICH_MACHINE_LEARNING_URL
value: http://immichprod-machine-learning:3003
- name: IMMICH_SERVER_URL
value: http://immichprod-server:3001
- name: IMMICH_WEB_URL
value: http://immichprod-web:3000
- name: REDIS_HOSTNAME
value: immichprod-redis-master
- name: TYPESENSE_API_KEY
value: typesense
- name: TYPESENSE_DATA_DIR
value: /tsdata
- name: TYPESENSE_ENABLED
value: "true"
- name: TYPESENSE_HOST
value: immichprod-typesense
image: docker.io/typesense/typesense:0.24.0
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /health
port: http
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
name: immichprod-typesense
ports:
- containerPort: 8108
name: http
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /health
port: http
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /tsdata
name: tsdata
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-896hw
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
nodeName: builder-hp-elitebook-850-g2
preemptionPolicy: PreemptLowerPriority
priority: 0
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
volumes:
- name: tsdata
persistentVolumeClaim:
claimName: immichprod-typesense-tsdata
- name: kube-api-access-896hw
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
status:
conditions:
- lastProbeTime: null
lastTransitionTime: "2023-11-21T11:49:27Z"
status: "True"
type: Initialized
- lastProbeTime: null
lastTransitionTime: "2023-11-21T11:49:27Z"
message: 'containers with unready status: [immichprod-typesense]'
reason: ContainersNotReady
status: "False"
type: Ready
- lastProbeTime: null
lastTransitionTime: "2023-11-21T11:49:27Z"
message: 'containers with unready status: [immichprod-typesense]'
reason: ContainersNotReady
status: "False"
type: ContainersReady
- lastProbeTime: null
lastTransitionTime: "2023-11-21T11:49:26Z"
status: "True"
type: PodScheduled
containerStatuses:
- containerID: containerd://b9665cc80044ef1efa538949e8cf0277587c7ad999ff3cb72d26e4acabf132a6
image: docker.io/typesense/typesense:0.24.0
imageID: docker.io/typesense/typesense@sha256:3cc1251f09ef6c75a5b1f2751c04e7265c770c0f2b69cba1f9a9f20da57cfa28
lastState:
terminated:
containerID: containerd://b9665cc80044ef1efa538949e8cf0277587c7ad999ff3cb72d26e4acabf132a6
exitCode: 1
finishedAt: "2023-11-21T11:51:10Z"
reason: Error
startedAt: "2023-11-21T11:51:09Z"
name: immichprod-typesense
ready: false
restartCount: 4
started: false
state:
waiting:
message: back-off 1m20s restarting failed container=immichprod-typesense pod=immichprod-typesense-55bf4bd8d6-sg49p_immich(4e7d3022-468e-4855-800d-75d45863a8bc)
reason: CrashLoopBackOff
hostIP: 192.168.1.215
phase: Running
podIP: 10.42.3.148
podIPs:
- ip: 10.42.3.148
qosClass: BestEffort
startTime: "2023-11-21T11:49:27Z"
The parts we care about are the volumeMounts in the spec:
volumeMounts:
- mountPath: /tsdata
name: tsdata
and the source of those volumeMounts, the volumes:
volumes:
- name: tsdata
persistentVolumeClaim:
claimName: immichprod-typesense-tsdata
I’ll create a quick utility pod that we can use to fix this:
$ cat immichpod.yaml
apiVersion: v1
kind: Pod
metadata:
name: ubuntu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu
command: ["tail", "-f", "/dev/null"]
volumeMounts:
- name: immichprod-typesense-tsdata
mountPath: /tsdata
volumes:
- name: immichprod-typesense-tsdata
persistentVolumeClaim:
claimName: immichprod-typesense-tsdata
$ kubectl apply -f immichpod.yaml -n immich
pod/ubuntu-pod created
Next, I’ll exec into the pod
$ kubectl get pods -n immich
NAME READY STATUS RESTARTS AGE
immichprod-redis-master-0 1/1 Running 0 5d18h
immichprod-web-dd4b87954-g2n56 1/1 Running 0 21d
immichprod-machine-learning-75d84dd96f-rzswr 1/1 Running 0 5d19h
immichprod-postgresql-0 1/1 Running 0 22d
immichprod-proxy-764698ffb4-ncmst 1/1 Running 12 (4d16h ago) 5d19h
immichprod-typesense-55bf4bd8d6-sg49p 0/1 CrashLoopBackOff 7 (68s ago) 12m
ubuntu-pod 1/1 Running 0 23s
immichprod-microservices-5b969c856d-2wnq8 0/1 CrashLoopBackOff 918 (21s ago) 5d19h
immichprod-server-c6698b848-7nlj4 0/1 CrashLoopBackOff 7 (6s ago) 12m
$ kubectl exec -it ubuntu-pod -n immich -- /bin/bash
root@ubuntu-pod:/#
I’ll remove the lock
$ kubectl exec -it ubuntu-pod -n immich -- /bin/bash
root@ubuntu-pod:/# ls /tsdata/db/
000975.log CURRENT LOCK LOG.old.1700567469760409 LOG.old.1700567729831999 MANIFEST-000004 archive
000977.sst IDENTITY LOG LOG.old.1700567558745219 LOG.old.1700568039807357 OPTIONS-000007
root@ubuntu-pod:/# rm -f /tsdata/db/LOCK
root@ubuntu-pod:/# rm -f /tsdata/meta/LOCK
root@ubuntu-pod:/# exit
exit
Then rotate the crashed pods and watch until they come back online:
$ kubectl get pods -n immich
NAME READY STATUS RESTARTS AGE
immichprod-redis-master-0 1/1 Running 0 5d18h
immichprod-web-dd4b87954-g2n56 1/1 Running 0 21d
immichprod-machine-learning-75d84dd96f-rzswr 1/1 Running 0 5d19h
immichprod-postgresql-0 1/1 Running 0 22d
immichprod-proxy-764698ffb4-ncmst 1/1 Running 12 (4d16h ago) 5d19h
ubuntu-pod 1/1 Running 0 5m28s
immichprod-microservices-5b969c856d-7mcbn 1/1 Running 0 2m44s
immichprod-typesense-55bf4bd8d6-c67dk 1/1 Running 0 65s
immichprod-server-c6698b848-sh2nr 1/1 Running 2 (32s ago) 2m38s
Now we are back to good!
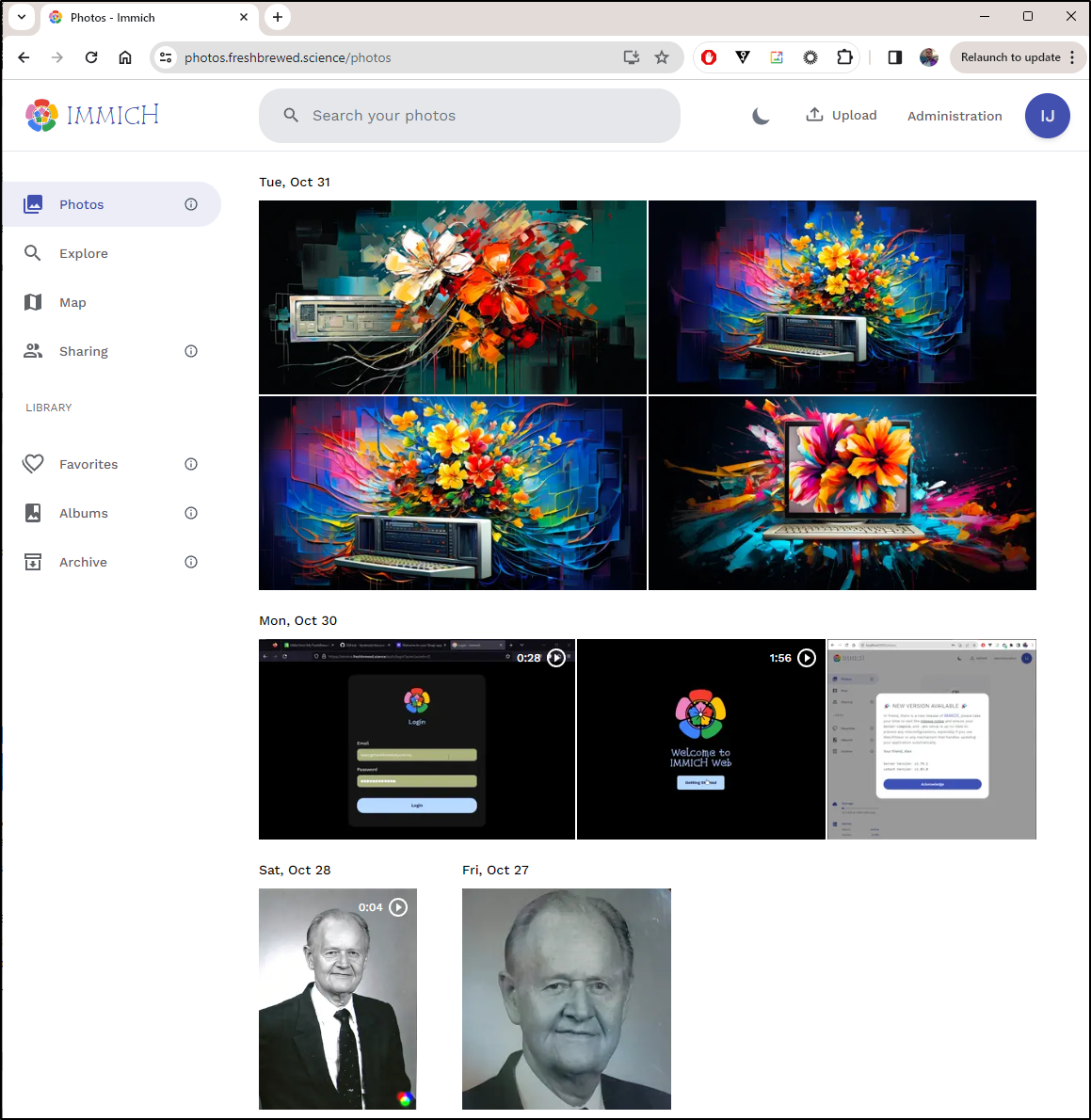
Ansible Checks with Bash
I didn’t want to just leave it there. I really should keep an eye out for failing systems.
I could write a check in Datadog on pods, that would work.
The other more generic approach might be to use a scheduled job in AWX.
First, I’ll need a script that can watch for 4xx and 5xx responses from a website. I added in some email notifications using resend.dev (see the Tools Roundup post on Resend.dev).
$ cat ./checkWebsiteAndPage.sh
#!/bin/bash
URL=$1
# Resend.dev
RESTKN=$2
FROME=$3
TOE=$4
echo '{"from":"' | tr -d '\n' > payload.json
echo $FROME | tr -d '\n' >> payload.json
echo '", "to": "' | tr -d '\n' >> payload.json
echo $TOE | tr -d '\n' >> payload.json
echo '", "subject": "' | tr -d '\n' >> payload.json
echo $URL | tr -d '\n' >> payload.json
echo ' in error", "html": "<h1>' | tr -d '\n' >> payload.json
echo $URL | tr -d '\n' >> payload.json
if curl -k -I $URL 2>&1 | grep -q "HTTP/1.1 5"; then
echo "$URL Website is returning a 5xx error"
echo ' generated a 5xx code</h1>"' >> payload.json
echo '}' >> payload.json
cat payload.json
curl -X POST -H "Authorization: Bearer $RESTKN" -H 'Content-Type: application/json' -d @payload.json 'https://api.resend.com/emails'
exit
else
echo "$URL Website is not returning a 5xx error"
fi
if curl -k -I $URL 2>&1 | grep -q "HTTP/1.1 4"; then
echo "$URL Website is returning a 4xx error"
echo ' generated a 4xx code</h1>"' >> payload.json
echo '}' >> payload.json
cat payload.json
curl -X POST -H "Authorization: Bearer $RESTKN" -H 'Content-Type: application/json' -d @payload.json 'https://api.resend.com/emails'
exit
else
echo "$URL Website is not returning a 4xx error"
fi
I can do a quick test of a dead service:
$ ./checkWebsiteAndPage.sh https://gbwebui.freshbrewed.science re_xxxxxxxxxxxxxxxxxxxx onboarding@resend.dev isaac.johnson@gmail.com
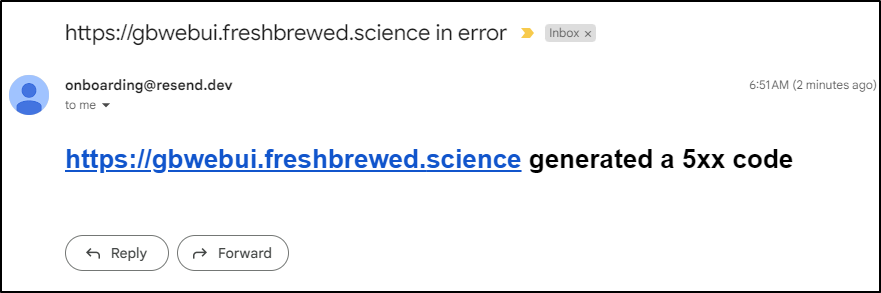
https://gbwebui.freshbrewed.science Website is returning a 5xx error
{"from":"onboarding@resend.dev", "to": "isaac.johnson@gmail.com", "subject": "https://gbwebui.freshbrewed.science in error", "html": "<h1>https://gbwebui.freshbrewed.science generated a 5xx code</h1>"
}
which fired an email
Next, I’ll make a new playbook that can use that script
$ cat checkForBustedInternalSites.yaml
- name: Check for Broken Services
hosts: all
tasks:
- name: Transfer the script
copy: src=checkWebsiteAndPage.sh dest=/tmp mode=0755
- name: Check Immich
ansible.builtin.shell: |
./checkWebsiteAndPage.sh https://photos.freshbrewed.science
args:
chdir: /tmp
- name: Check GBWebUI
ansible.builtin.shell: |
# Known fail - to test
./checkWebsiteAndPage.sh https://gbwebui.freshbrewed.science
args:
chdir: /tmp
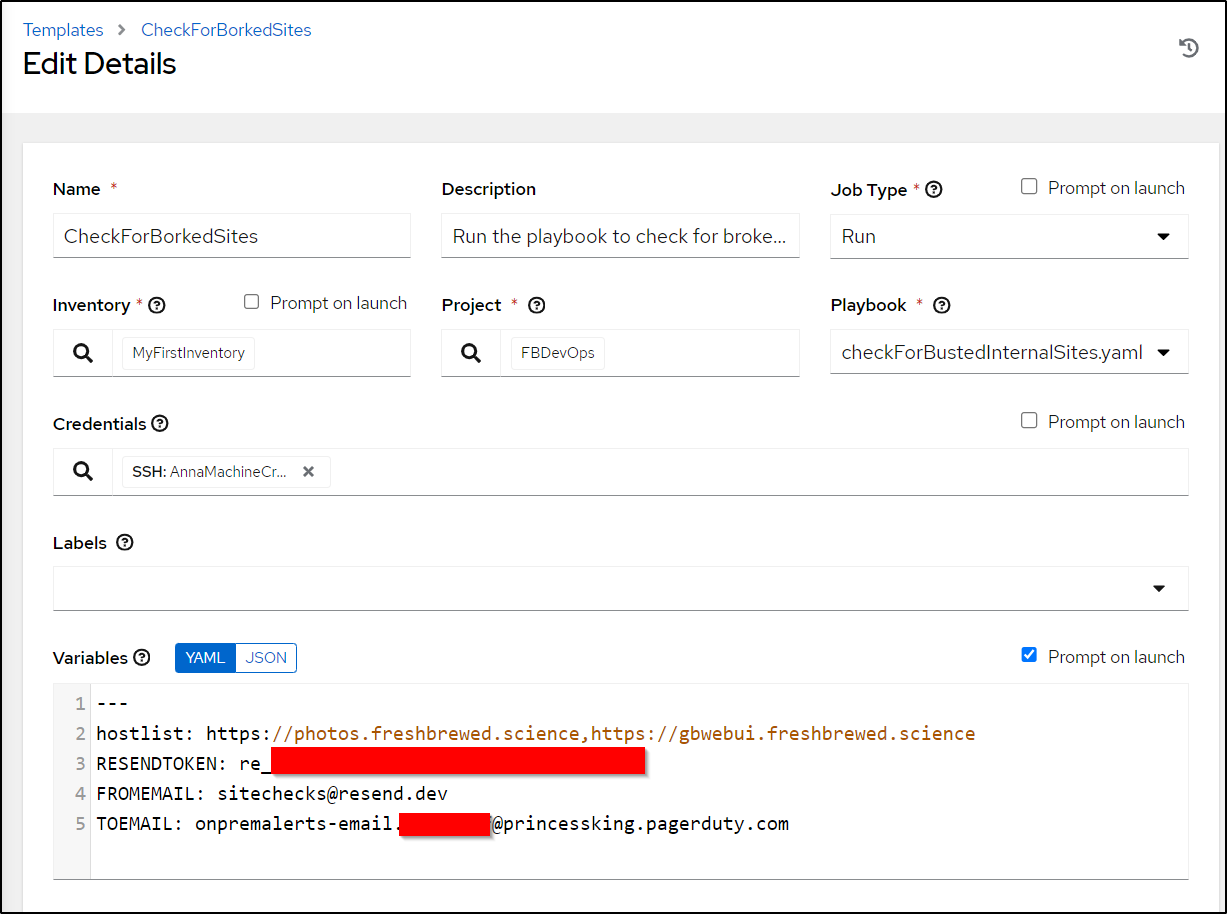
I’ll create a template to use it
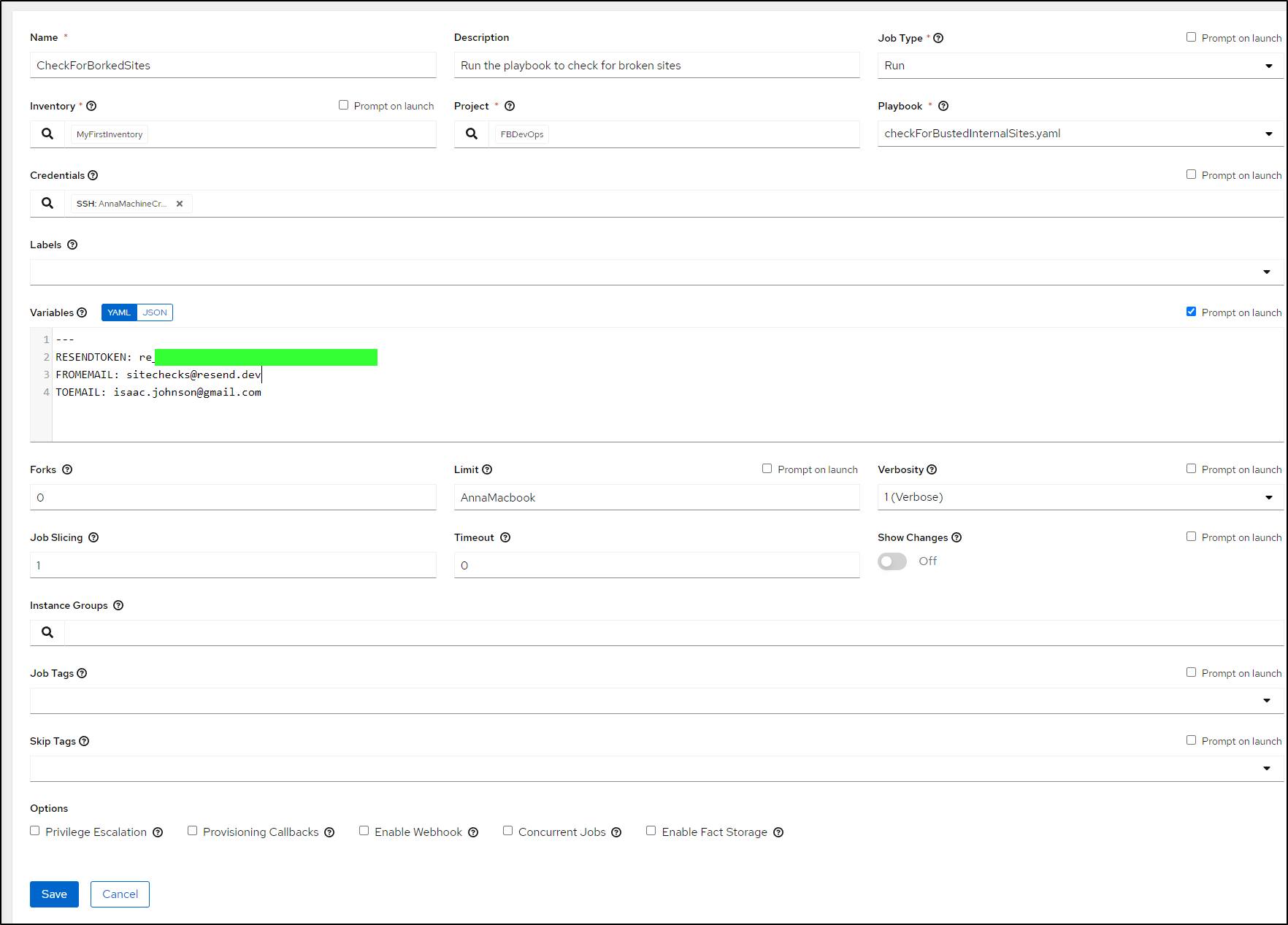
then launch
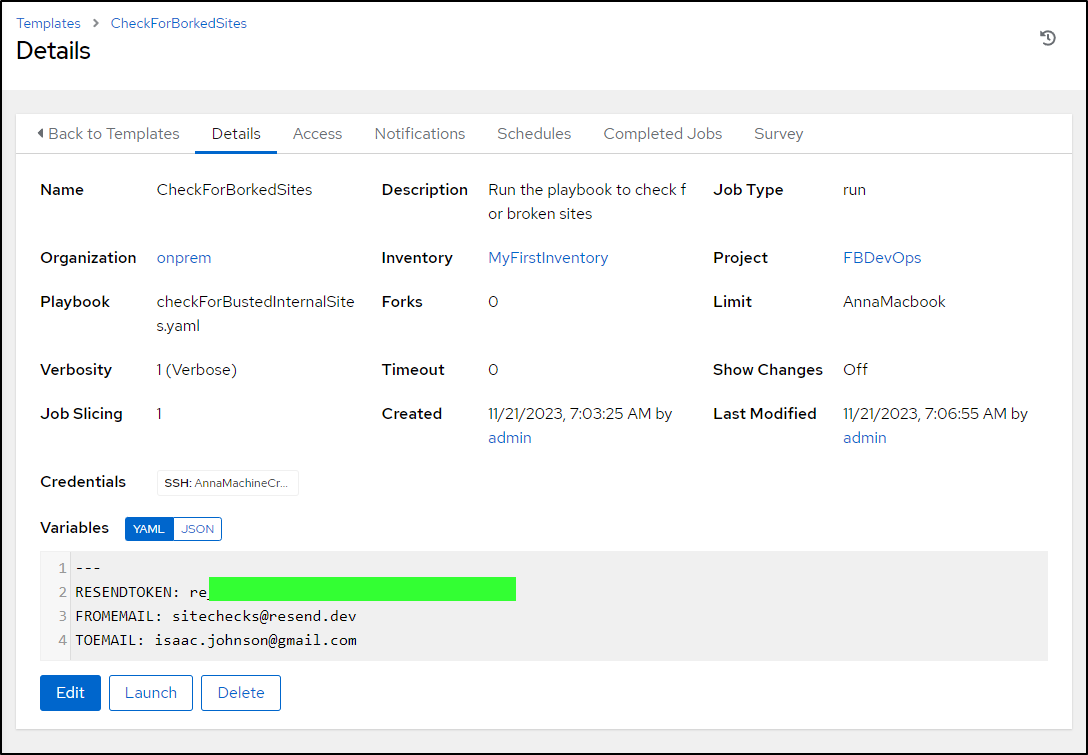
It successfully sent an email on the check
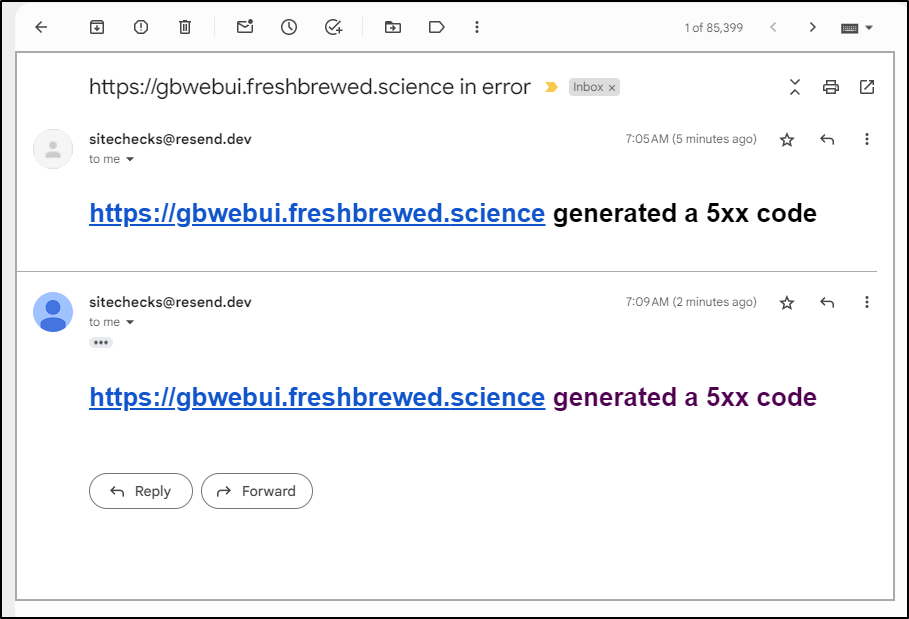
Maintaining a large hardcoded list seems fraught with problems. Let’s change this to a loop
- name: Check for Broken Services
hosts: all
tasks:
- name: Transfer the script
copy: src=checkWebsiteAndPage.sh dest=/tmp mode=0755
- name: Check Immich
ansible.builtin.shell: |
./checkWebsiteAndPage.sh {{ item }} {{ RESENDTOKEN }} {{ FROMEMAIL }} {{ TOEMAIL }}
loop: "{{ hostlist.split(',') }}"
args:
chdir: /tmp
Then update the template vars
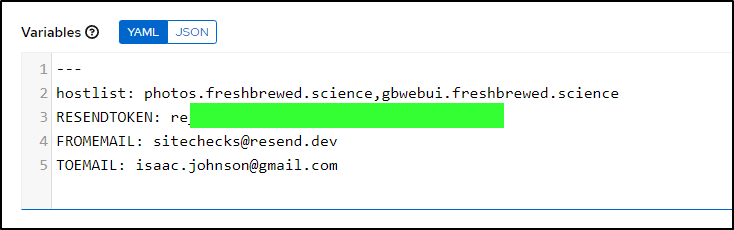
Actually, I needed to add the protocol in that variable to make it work:
hostlist: https://photos.freshbrewed.science,https://gbwebui.freshbrewed.science
Next, I want to use PagerDuty to alert me if there is an issue. I need to fetch the email from the service.
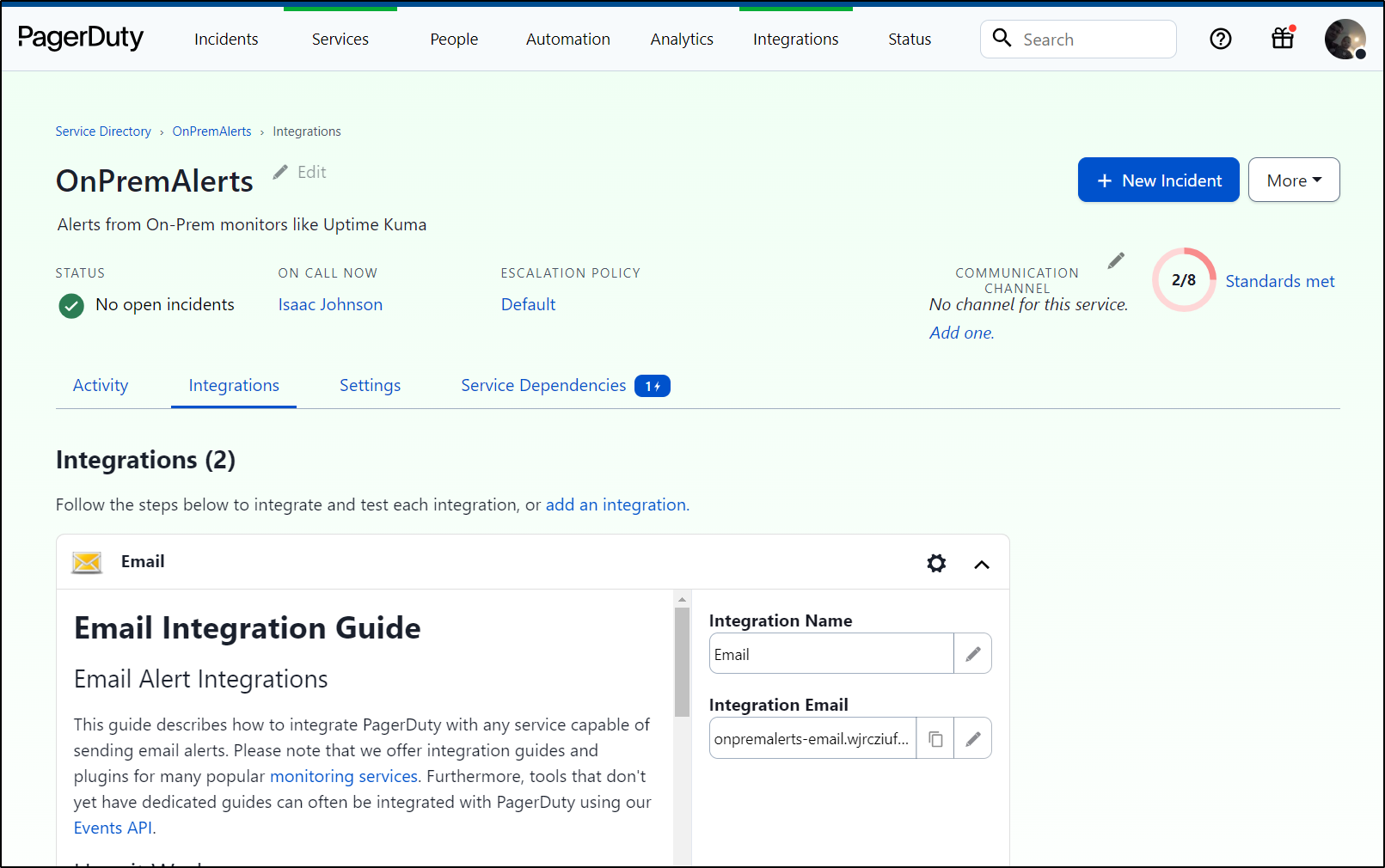
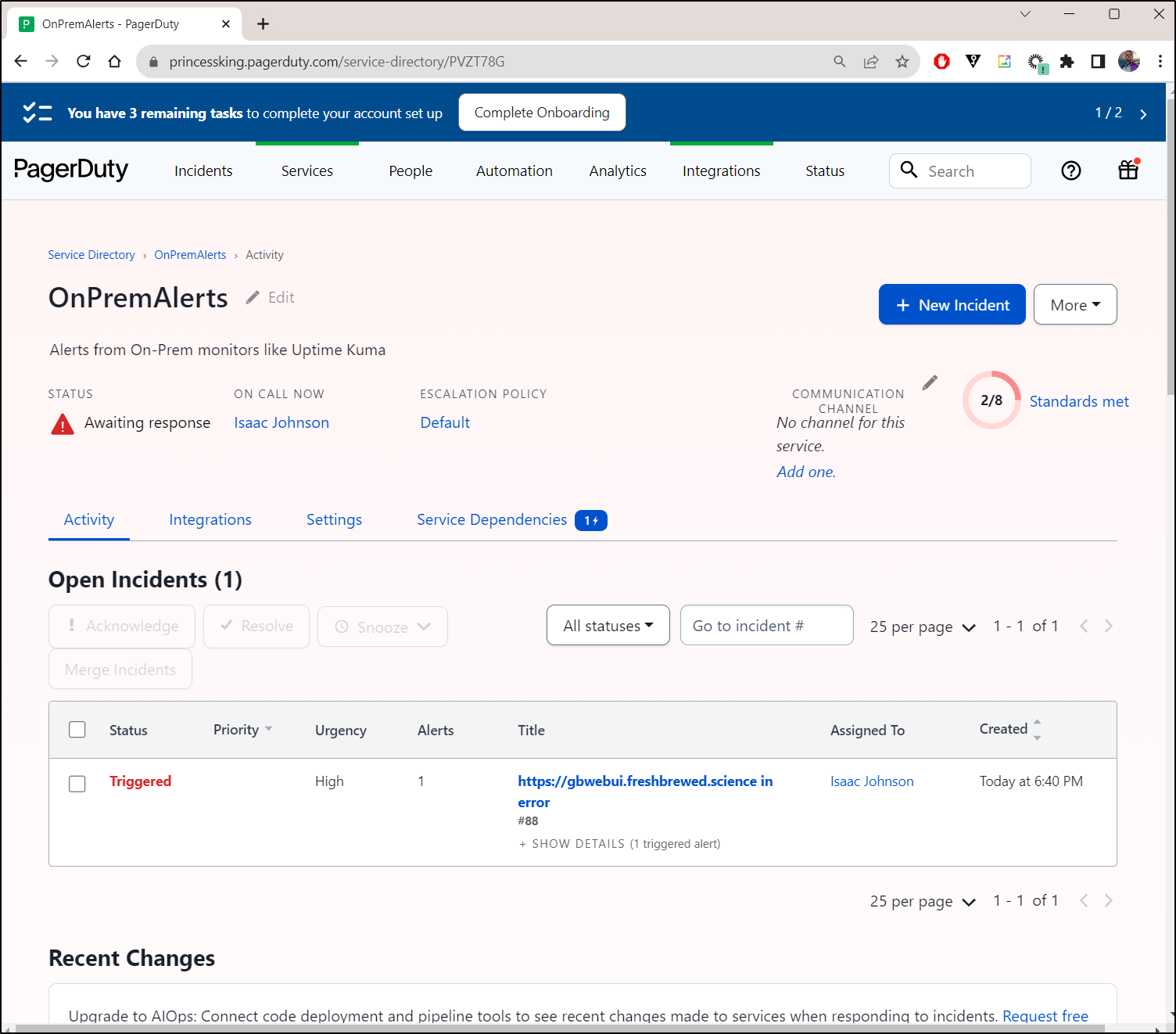
Next, I’ll do one more test with the gbwebui endpoint i know will fail
which triggered alerts
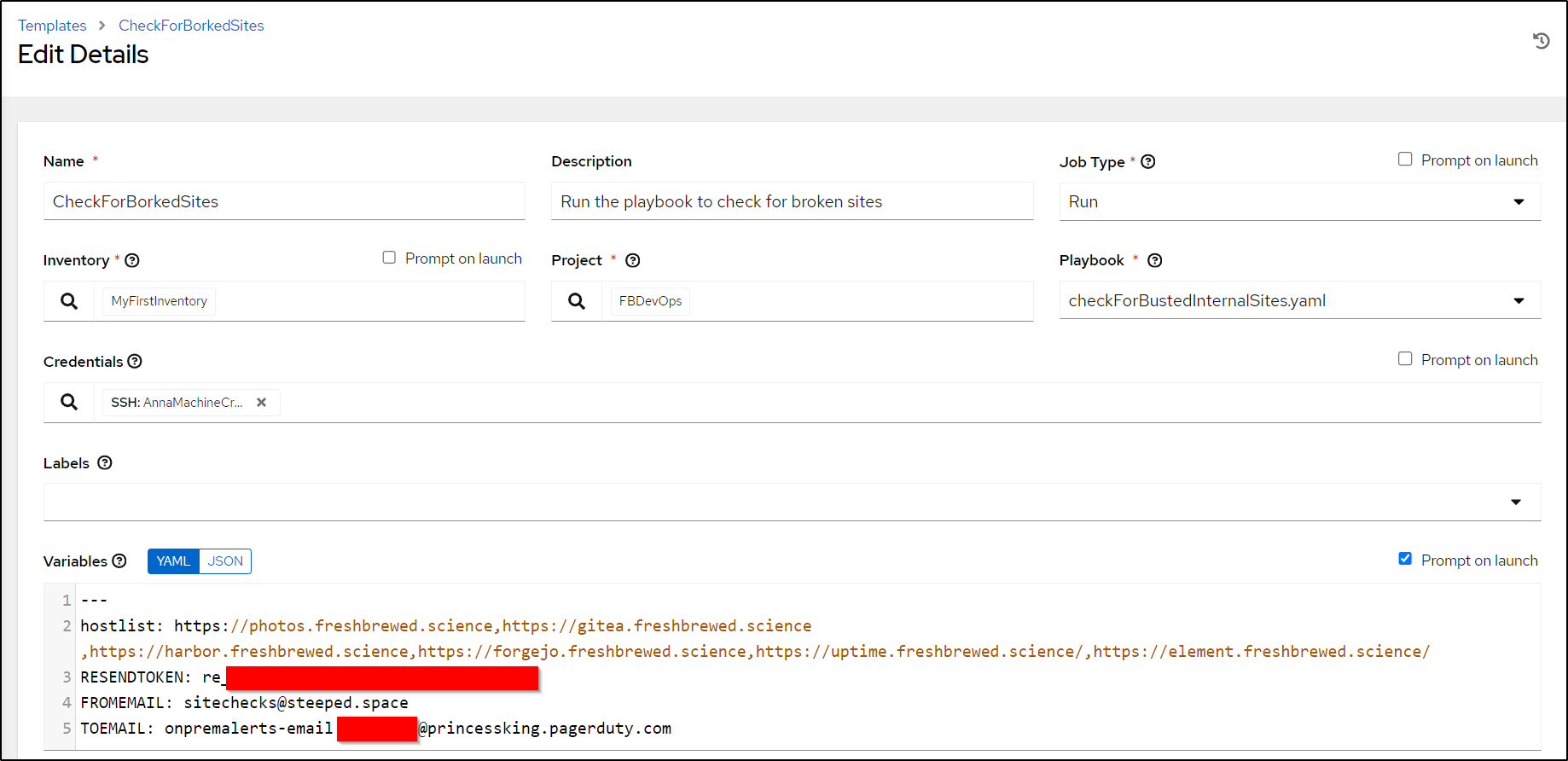
Now, I want to finish by setting just the services I care to monitor and using my monitoring email.
I’ll then add a schedule
Set to daily
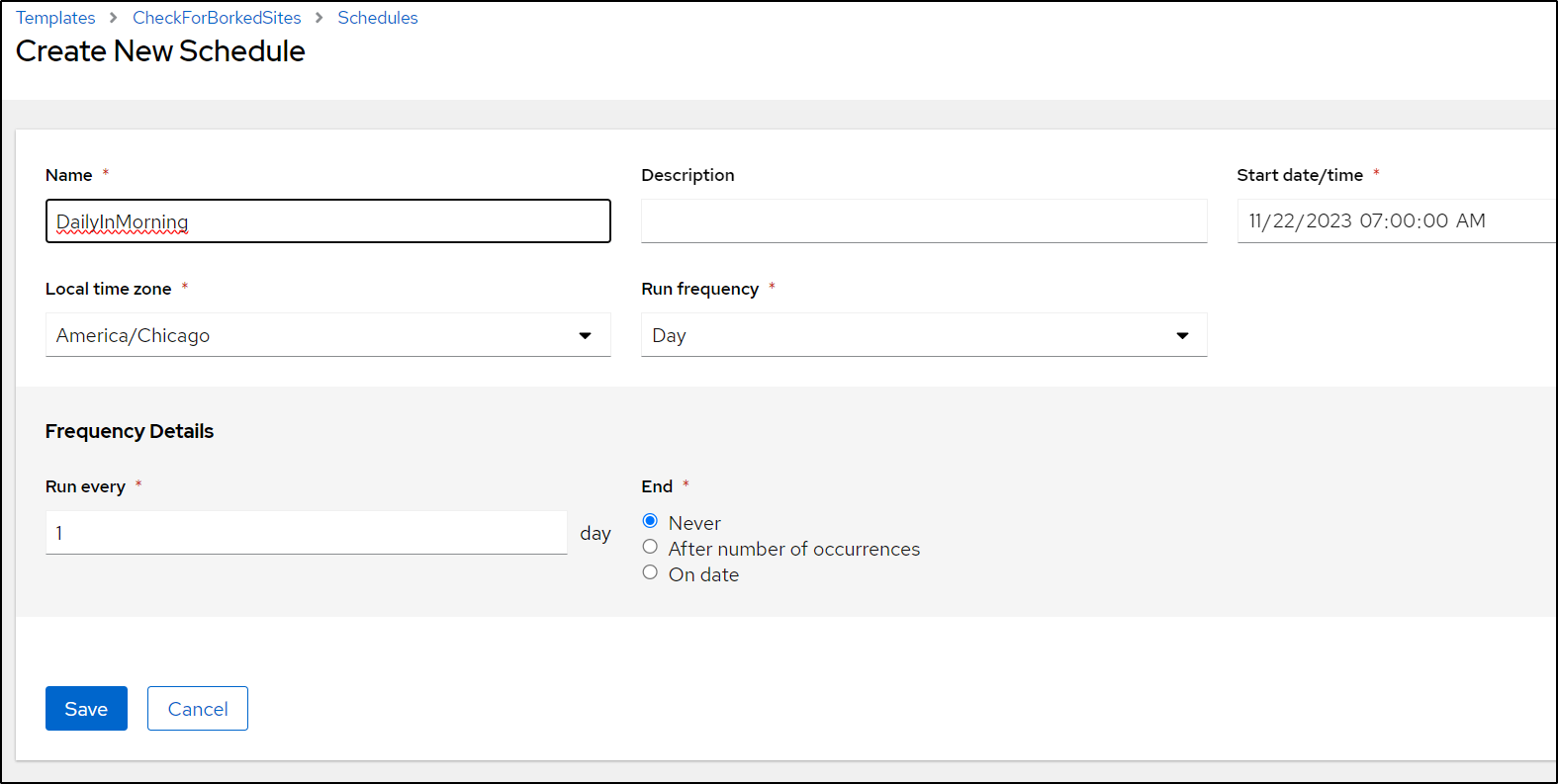
which I can see set once saved
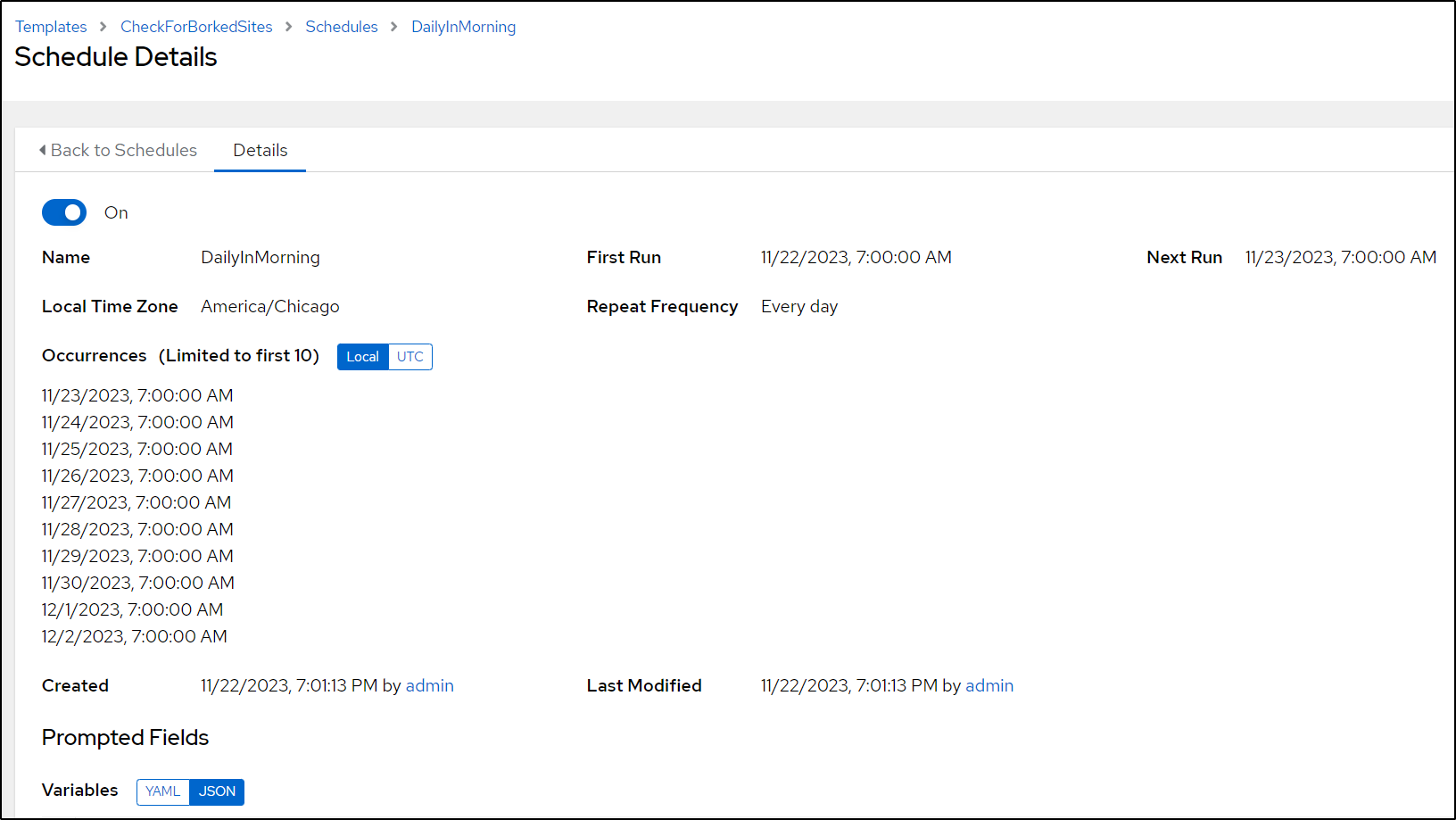
You can get both the script and playbook in my public Ansible library.
I should point out that you do need to verify a domain to send to other places (like the PagerDuty email integration).
I personally have been using Gandi for the last 15+ years for cheap domains.
One could also send emails using SendGrid or any other outgoing SMTP service.
Summary
My services took a dive, which happens from time to time. But it made me feel a bit silly calling myself an SRE Architect when I’m not actually doing the Site Reliability Engineering work on my own stuff.
Fixing the problem was a must, and that meant quickly mounting an equivalent PVC or local volume to a temporary pod. But beyond just getting the stuck system up and running, I should have had better monitoring in place to catch this in the first place.
To prevent it from happening again, I created the script and playbook to run on a schedule tied to Pagerduty. It’s low-tech but a reliable way to check (provided, of course, AWX doesn’t go down).
