Published: Nov 23, 2023 by Isaac Johnson
In our last post we covered setting up a Gitea based Resume Repo in my Gitea instance. We sorted out actions, PDF generation and syncing to a newly created Sonatype Nexus OSS instance in Kubernetes.
I think this is a marvelous way to keep it all in-house. All the tooling I used was Open-Source and self-hosted which is great for control. However, not everyone maintains a stack of laptops as a K3s cluster at home. We also saw how a larger Gitea update wiped my repo and I had to start over. We could chalk that up to a PEBKAC error, but regardless, there are drawbacks to self-hosting.
Let’s revisit this but stick with some industry leaders, Github and Gitlab. I would like to implement this same model through to completion in Github and show the ground work in Gitlab (I have nothing against Gitlab, but my identity is more rooted to Github presently).
Github repo
First, let’s talk about Github profiles because we are going to want to leverage them in this work. If we go to our icon and choose “Your profile”
You’ll come to a page that is https://github.com/$yourgithubuser. Here is mine with a nice summer headshot in a strawberry field
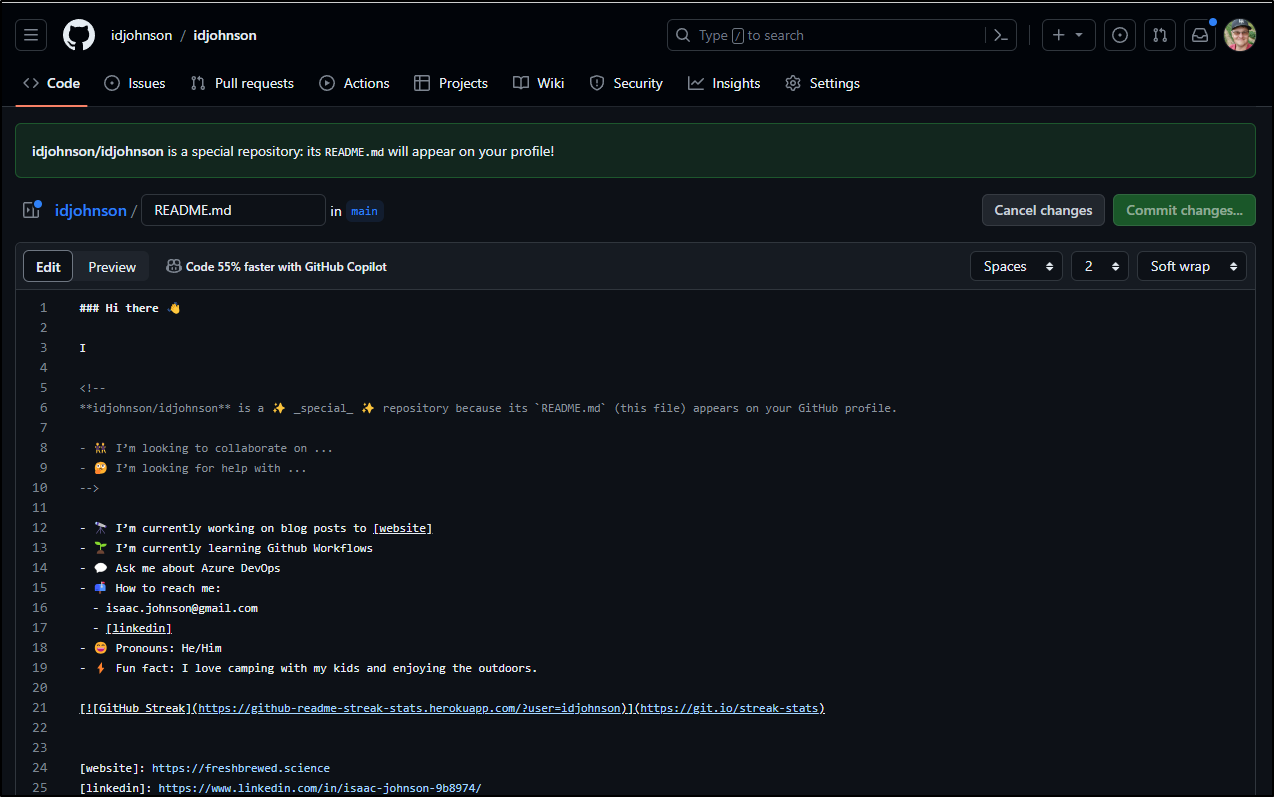
If you haven’t explored this, you may not realize it’s just a GIT repo with a Readme. Clicking the pencil icon takes us to edit the README (in my case https://github.com/idjohnson/idjohnson/edit/main/README.md)
We will be coming back to this later.
Creating a Resume repo
I’ll now create a new repo. I’ll make it public w/ Apache so everyone can copy from it.
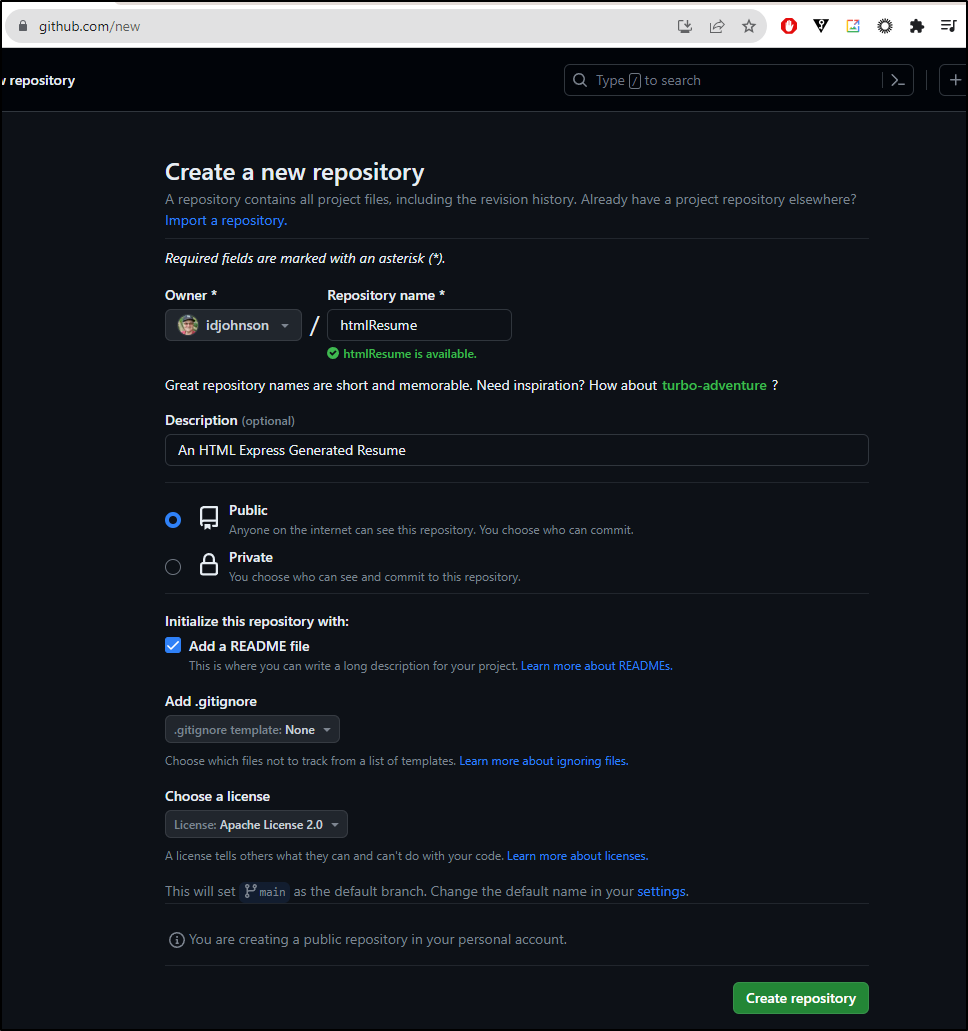
I’ve worked out a decent expressJs version with which we can start.
I’m using NodeJS v16.14.2
$ nvm use 16.14.2
Since I plan to work out some improvements here, I created a v0.0.1 release you can download.
We’ll npm install
$ npm install
up to date, audited 211 packages in 598ms
21 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Then run resume (I used :3080 instead of the normal :3000 as I have a docker container using 3000 at the moment)
$ npm run resume
> resumejs@1.0.0 resume
> node app.js
Server is running on http://localhost:3080
We can see the output as it stands
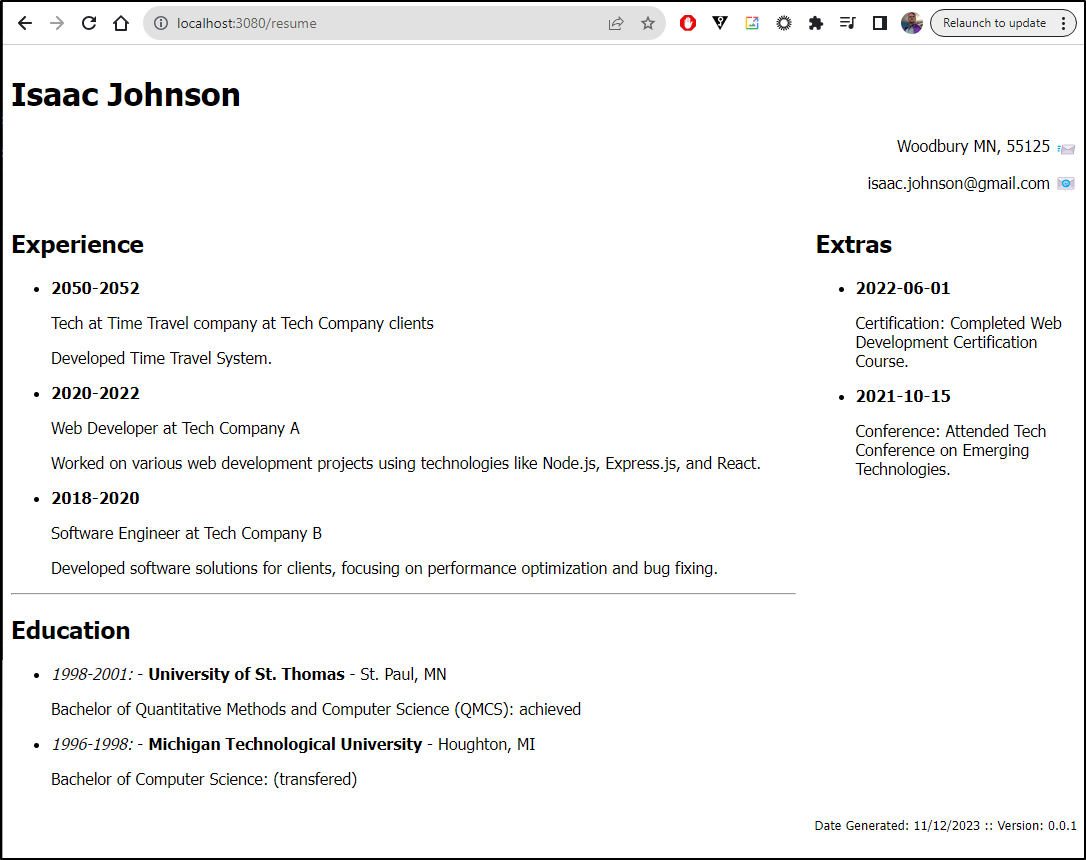
The sections
Each section stores the data as a JSON file and I’m using dates (YYYYMM) to postfix them. They’ll sort properly. I decided, logically, for experiences, start date makes more sense than end date.
Every section also has an ‘enabled’ modal we can leverage later. I already set an example address here.
I’m working on making the resume page itself a bit nicer looking, but as it stands, we can see the styles and the code to render it in views/resume.ejs
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Resume</title>
<style>
body {
font-family: 'Tahoma', sans-serif;
margin: 10;
padding: 10;
}
.resume-container {
display: flex;
flex-direction: column;
align-items: flex-start;
}
.contact-section {
width: 100%;
text-align: left;
}
.experience-section {
display: flex;
width: 100%;
}
.experience-list {
flex: 3;
width: 75%;
margin-right: 20px;
}
.extras-list {
flex: 1;
width: 25%;
}
.footer {
flex: 1;
width: 100%;
}
h1, h2, p, li {
font-family: 'Tahoma', sans-serif;
}
</style>
</head>
<body>
<div class="resume-container">
<div class="contact-section">
<p><h1><strong><%= names.name %></strong></h1></p>
<% contacts.reverse().forEach((contact) => { %>
<% if (contact.enabled === 'true') { %>
<p style="text-align: right;"><%= contact.value %> <%- contact.icon %></p>
<% } %>
<% }); %>
</div>
<div class="experience-section">
<div class="experience-list">
<h2>Experience</h2>
<ul>
<% experiences.reverse().forEach((experience) => { %>
<% if (experience.enabled === 'true') { %>
<li>
<strong><%= experience.year %></strong>
<p><%= experience.title %> at <%= experience.company %></p>
<p><%= experience.description %></p>
</li>
<% } %>
<% }); %>
</ul>
<hr/>
<h2>Education</h2>
<ul>
<% educations.reverse().forEach((education) => { %>
<% if (education.enabled === 'true') { %>
<li>
<i><%= education.year %>:</i> - <strong><%= education.institution %></strong> - <%= education.location %>
<p><%= education.degreeorcert %>: <%= education.status %></p>
</li>
<% } %>
<% }); %>
</ul>
</div>
<div class="extras-list">
<h2>Extras</h2>
<ul>
<% extras.reverse().forEach((extra) => { %>
<% if (extra.enabled === 'true') { %>
<li>
<strong><%= extra.date %></strong>
<p><%= extra.keyword %>: <%= extra.description %></p>
</li>
<% } %>
<% }); %>
</ul>
</div>
</div>
<div class="footer">
<p style="text-align: right; font-size: small;">Date Generated: <%= new Date().toLocaleDateString() %> :: Version: <%= version %></p>
</div>
</div>
</body>
</html>
I do want to highlight the contact details block which has icons rendered:
<p style="text-align: right;"><%= contact.value %> <%- contact.icon %></p>
If you want content to render HTML and not escape it (as with the icon) use <%- instead of <%=.
The other action added in packge.json was the generatePdf routine.
{
"name": "resumejs",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"generatepdf": "node generate-pdf.js",
"resume": "node app.js"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"ejs": "^3.1.9",
"express": "^4.18.2",
"puppeteer": "^21.5.1"
}
}
It’s none too complicated. It basically uses puppeteer to fire up our app then render out the PDF
$ cat generate-pdf.js
const puppeteer = require('puppeteer');
const { exec } = require('child_process');
const path = require('path');
// Start the Express application
const expressProcess = exec('node app.js');
expressProcess.stdout.on('data', (data) => {
console.log(`Express: ${data}`);
});
expressProcess.stderr.on('data', (data) => {
console.error(`Express Error: ${data}`);
});
expressProcess.on('close', (code) => {
console.log(`Express process exited with code ${code}`);
});
// Wait for the Express application to start (adjust the delay as needed)
setTimeout(generatePDF, 60);
async function generatePDF() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
// Load the resume page
const resumeURL = 'http://localhost:3080/resume'; // Update with your actual URL
await page.goto(resumeURL, { waitUntil: 'networkidle0' });
// Set the PDF options
const pdfOptions = {
path: path.join(__dirname, 'output', 'resume.pdf'), // Adjust the output path as needed
format: 'A4',
printBackground: true,
};
// Generate PDF
await page.pdf(pdfOptions);
await browser.close();
// Close the Express application after generating the PDF
expressProcess.kill();
}
generatePDF();
I find it sometimes hangs
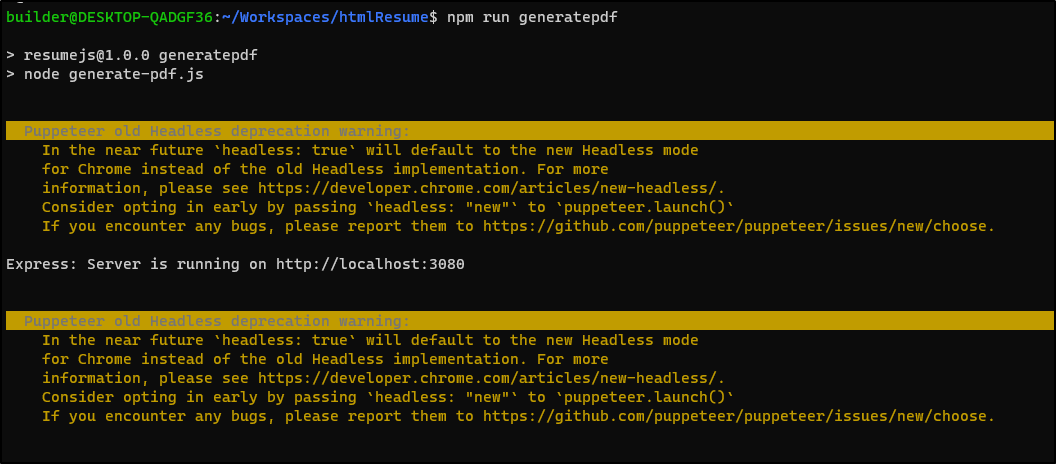
but generates a basic PDF

I’ve done a bit of work to tweak the styling. I’m a pretty poor CSS / front end dev so you are welcome to poke holes in how I tried to merge this styling in to my sheet.
But the updated render looks as such:
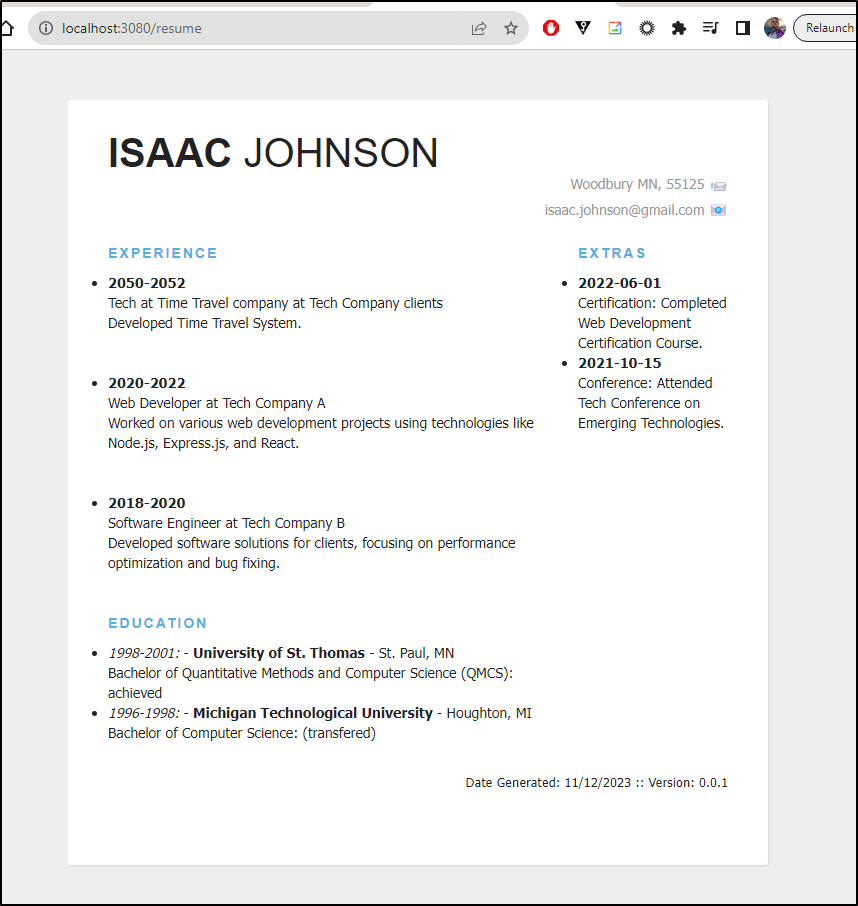
Public and Private sections
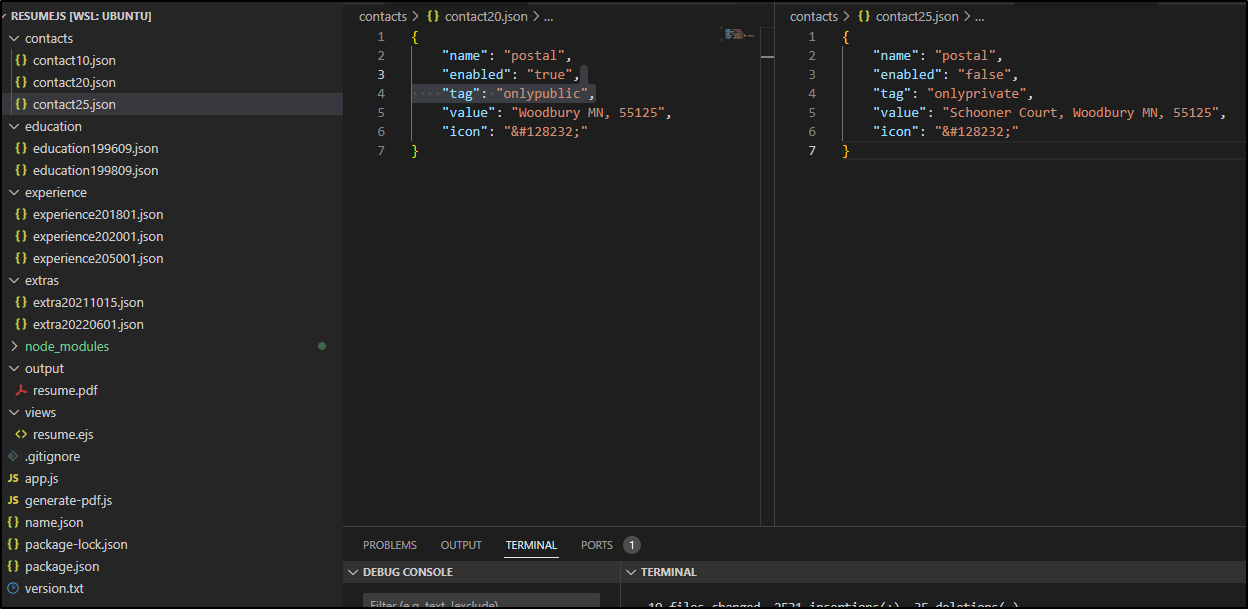
Let’s look at some of these sections that might be turned off and on
Here I have blocks for only publiconly and privateonly:
builder@DESKTOP-QADGF36:~/Workspaces/htmlResume$ cat contacts/contact10.json
{
"name": "email",
"enabled": "true",
"tag": "onlypublic",
"value": "isaac.johnson@gmail.com",
"icon": "📧"
}
builder@DESKTOP-QADGF36:~/Workspaces/htmlResume$ cat contacts/contact20.json
{
"name": "postal",
"enabled": "true",
"tag": "onlypublic",
"value": "Woodbury MN, 55125",
"icon": "📨"
}
builder@DESKTOP-QADGF36:~/Workspaces/htmlResume$ cat contacts/contact25.json
{
"name": "postal",
"enabled": "false",
"tag": "onlyprivate",
"value": "Schooner Court, Woodbury MN, 55125",
"icon": "✉"
}
builder@DESKTOP-QADGF36:~/Workspaces/htmlResume$ cat contacts/contact15.json
{
"name": "email",
"enabled": "false",
"tag": "onlyprivate",
"value": "isaac@freshbrewed.science",
"icon": "📧"
}
I can create a quick script that for all my main sections (contacts, education, experience, extras) it can turn on and off blocks:
The updateForPrivate.sh will set active private blocks (ignoring the untagged)
builder@DESKTOP-QADGF36:~/Workspaces/htmlResume$ cat updateForPrivate.sh
#!/bin/bash
# For Private
# Find all JSON files in subfolders
# Specify the subfolders to search
subfolders=("contacts" "education" "experience" "extras")
for folder in "${subfolders[@]}"; do
# Find all JSON files in the specified subfolder
find "$folder" -type f -name '*.json' -print0 |
while IFS= read -r -d '' file; do
# Check if the file contains the key "tag" with the value "onlyprivate"
if jq -e '.tag == "onlyprivate"' "$file" > /dev/null 2>&1; then
# Update the key "enabled" to "true"
jq '.enabled = "true"' "$file" > tmpfile && mv tmpfile "$file"
echo "Updated $file"
fi
done
find "$folder" -type f -name '*.json' -print0 |
while IFS= read -r -d '' file; do
# Check if the file contains the key "tag" with the value "onlyprivate"
if jq -e '.tag == "onlypublic"' "$file" > /dev/null 2>&1; then
# Update the key "enabled" to "false"
jq '.enabled = "false"' "$file" > tmpfile && mv tmpfile "$file"
echo "Updated $file"
fi
done
done
The updateForPublic.sh can do just the reverse:
$ cat updateForPublic.sh
#!/bin/bash
# For Private
subfolders=("contacts" "education" "experience" "extras")
for folder in "${subfolders[@]}"; do
# Find all JSON files in the specified subfolder
find "$folder" -type f -name '*.json' -print0 |
while IFS= read -r -d '' file; do
# Check if the file contains the key "tag" with the value "onlyprivate"
if jq -e '.tag == "onlyprivate"' "$file" > /dev/null 2>&1; then
# Update the key "enabled" to "true"
jq '.enabled = "false"' "$file" > tmpfile && mv tmpfile "$file"
echo "Updated $file"
fi
done
find "$folder" -type f -name '*.json' -print0 |
while IFS= read -r -d '' file; do
# Check if the file contains the key "tag" with the value "onlyprivate"
if jq -e '.tag == "onlypublic"' "$file" > /dev/null 2>&1; then
# Update the key "enabled" to "false"
jq '.enabled = "true"' "$file" > tmpfile && mv tmpfile "$file"
echo "Updated $file"
fi
done
done
Let’s show how that might work:
Docx
My next goal was to solve Word Doc (Docx). I tried a few avenues including pdftodocx and abiword
pdf2docx convert -d output/resume.docx output/resume.pdf
abiword --to=doc output/resume.pdf
However, the one that rendered things best was pandoc.
$ sudo apt install -y pandoc
$ wget -O resume.html http://localhost:3080/resume
$ pandoc resume.html -o "test.docx"

I have a script I plan to test in a Github workflow, however I know it will leave an app instance running
$ cat genDocx.sh
#!/bin/bash
npm run resume &
sleep 4
wget -O resume.html http://localhost:3080/resume
pandoc resume.html -o "resume.docx"
I’ll build out some Github Actions to use it:
name: GitHub Action For Resume
on:
push:
branches:
- main
- isaacreal
pull_request:
jobs:
HostedActions:
runs-on: ubuntu-latest
steps:
- name: Check out repository code
uses: actions/checkout@v2
- name: Install NodeJS
uses: actions/setup-node@v4
with:
node-version: 18
- run: npm install
- name: Create dir
run: |
#!/bin/bash
sudo apt update
sudo apt install -y pandoc
mkdir ./output || true
- run: npm run generatepdf
timeout-minutes: 5
- name: Generate Docx
run: |
./genDocx.sh
timeout-minutes: 5
- uses: actions/upload-artifact@v3
with:
name: resumeDocx
path: resume.docx
- uses: actions/upload-artifact@v3
with:
name: resumePDF
path: output/resume.pdf
We can see the workflow creates artifacts
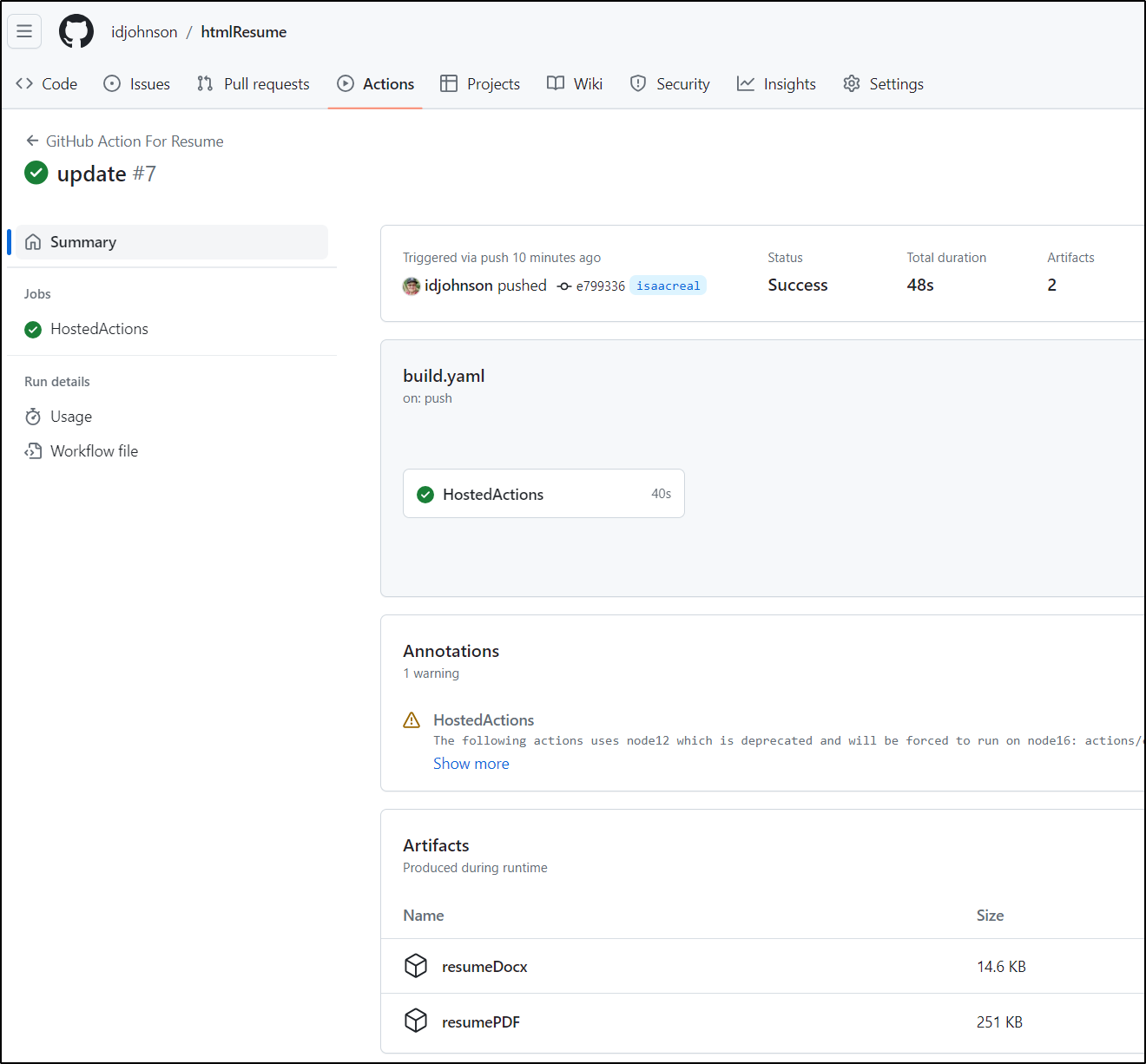
Which we can view
Adding to our Github profile
The next step was to add my GH PAT as a secret (my_pat)
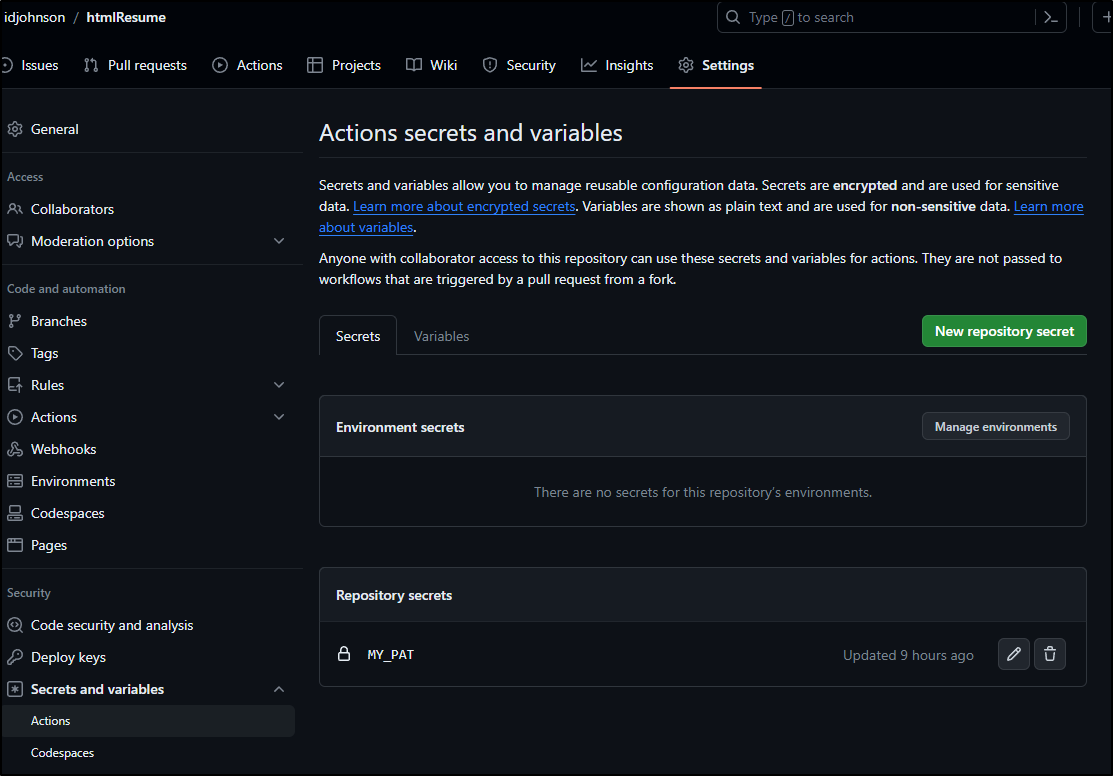
I could then add a block to clone my ‘idjohnson’ repo and upload the created PDF, and Docx Files
- name: Check out my other private repo
uses: actions/checkout@v4
with:
repository: idjohnson/idjohnson
token: $
path: 'idjohnson'
- name: debug
run: |
set -x
cd $GITHUB_WORKSPACE/idjohnson
git config --global user.email "isaac.johnson@example.com"
git config --global user.name "Isaac Johnson"
cp ../resume.docx ./
cp ../output/resume.pdf ./
git add resume.docx
git add resume.pdf
git commit -m 'add resume'
git push
Right now, we cannot see them on the Github public profile page
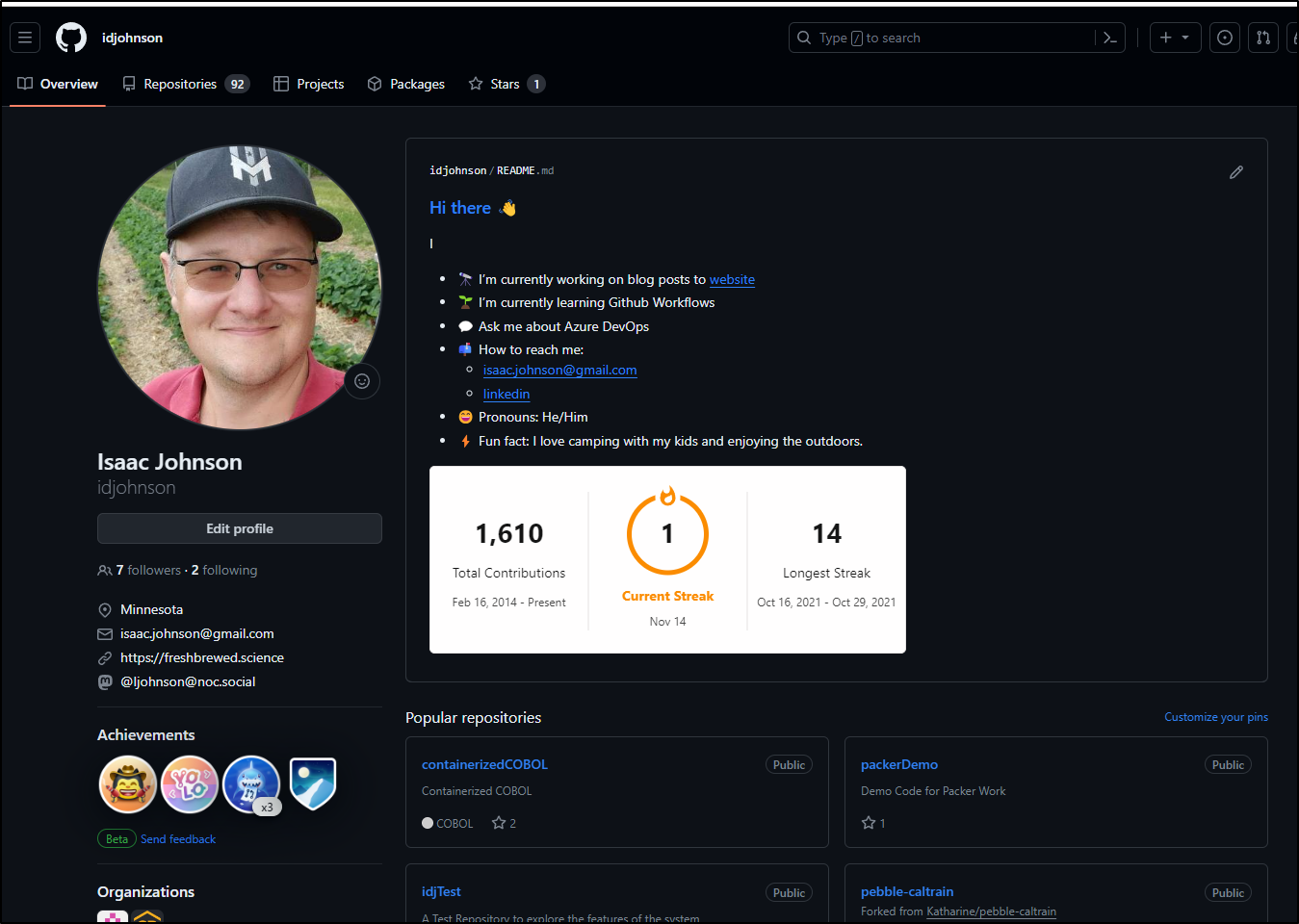
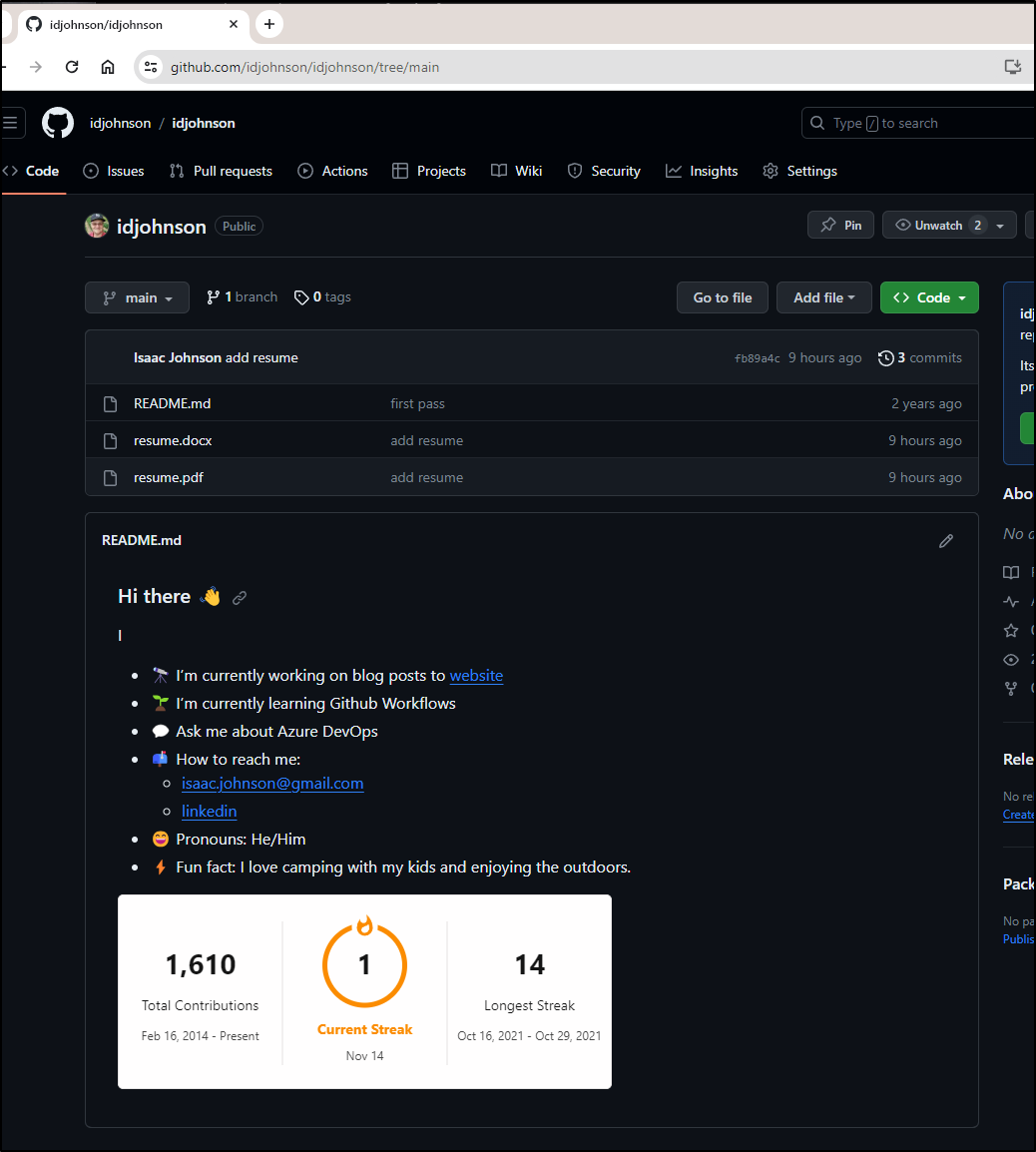
But if I click the pencil icon it brings me over to my idjohnson repo where I can see the files have been uploaded
Publishing your resume publicly poses the risk of spammers harvesting your contact information, such as your phone number and email address. Additionally, low-end recruiting firms may import your resume and contact you about irrelevant jobs, which can be frustrating.
While receiving a flood of calls about jobs can be flattering, if they are all for short-term contracts to update Windchill or tweak SunOS, it is not a good fit for me and only wastes my time. On the other hand, it is a small price to pay to be visible and accessible. Conversely, as a hiring manager, I view a low online profile as a negative sign in candidates.
I edited my README.md to add links for the resume versions (I’ll add HTML in a moment)
- 👯 Resume: [HTML](resume.html) | [PDF](resume.pdf) | [DOCX](resume.docx)
Let’s see it all in action.
And of course you can view the latest on my public Github profile
Summary
Last time we looked at a simple case of Markdown. Here we are taking it up a notch to drive a resume from JSON content. I likely need to add an address and phone but I haven’t sorted out where I would store that copy. Perhaps I could push it back to my NAS? Or email it to myself? I honestly plan to stew on this a bit to think through where I want it.
However, I cannot imagine the lack of a cell or full postal would be a barrier in any way. We’re in the 2020s now so 9 out of 10 times it’s a Teams/Zoom/Meet call, not cell. Also, I’m not really out looking for a new job (knock on wood). I’m very happy where I am, but I did like the challenge of flipping the idea of ‘resume driven development’ around to doing ‘development driven resume(s)’.
I hope you got something from this. I’ll point out again, the code is free to snag and use:
- Gitea Public Resume - the first blog, using Gitea and Markdown
- Github htmlResume - this post with the workflow and code. the branch isaacreal has the latest changes - but also all my actual experiences (I would find that kind of weird to have someone copy those, but if you want samples, go for it).
Probably the best way to kick off your own variant is to fork it and make it your own: