

Published: Apr 11, 2023 by Isaac Johnson
Cast.ai came up in a search for Open-Source Cost Management tools (that I have yet to try). While it isn’t open-source, at least as of a couple years ago, the founder promised to make it free for OS projects. I decided to give it a spin as they do have a rather usable free tier.
I’ll start off by saying this, at present, is rather married to the big three; AWS, Azure and Google. I’ll cover some rigging to apply to your on-prem K3s, but that is not what it is designed to manage.
Cast.ai is far more than just a Cost watching tool (like Ternary). It’s focused on Kubernetes only but also has a security scanning component as well as a custom autoscaler. They bill themselves as “the leading all-in-one platform for Kubernetes automation, optimization, security, and cost management.”
Let’s signup and see what we can do!
Signup
Let’s signup for Cast for free from the login page
It then has a wizard to ask me some basic info
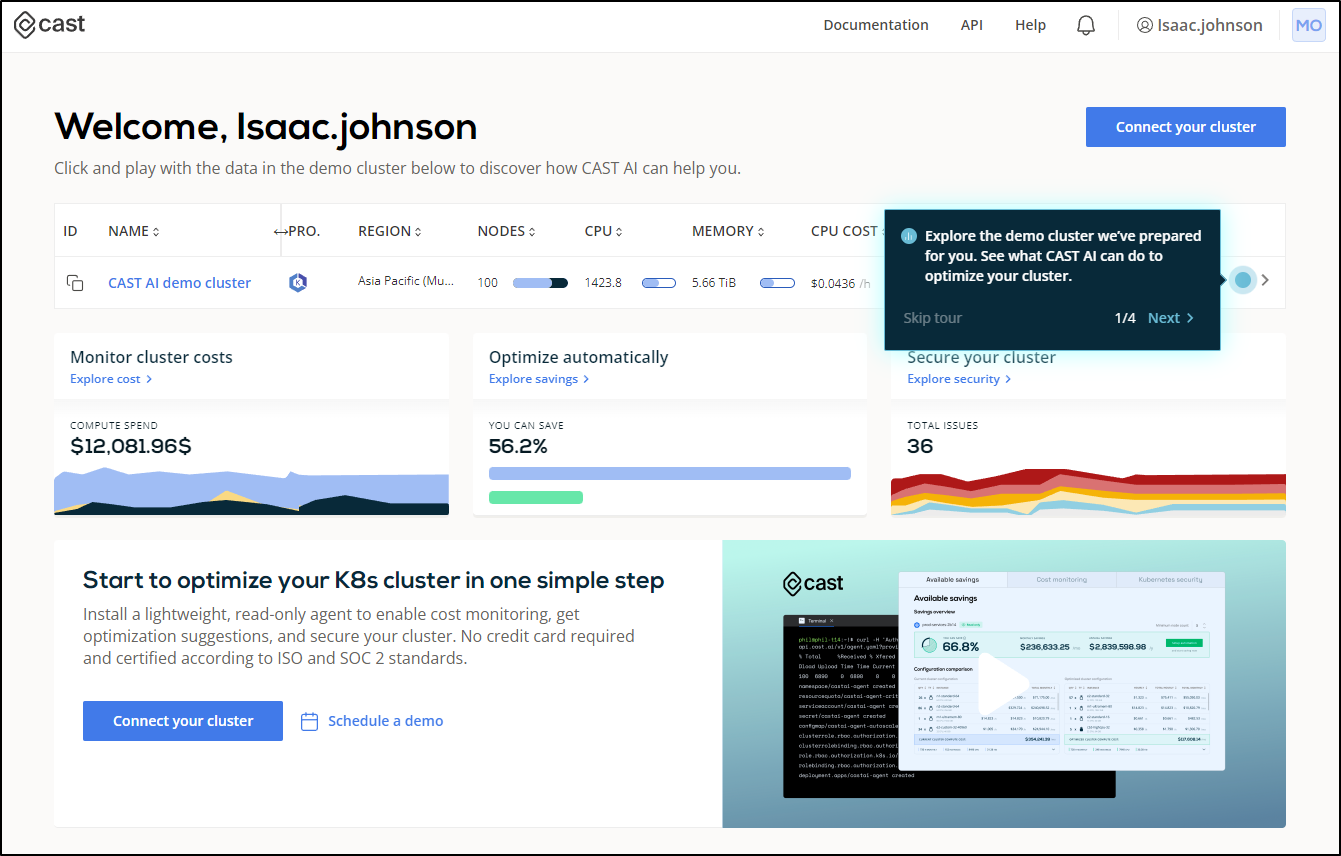
The constant ads and testominials make me suss…

Off the bat they added a ?fake? demo cluster to see their product in action
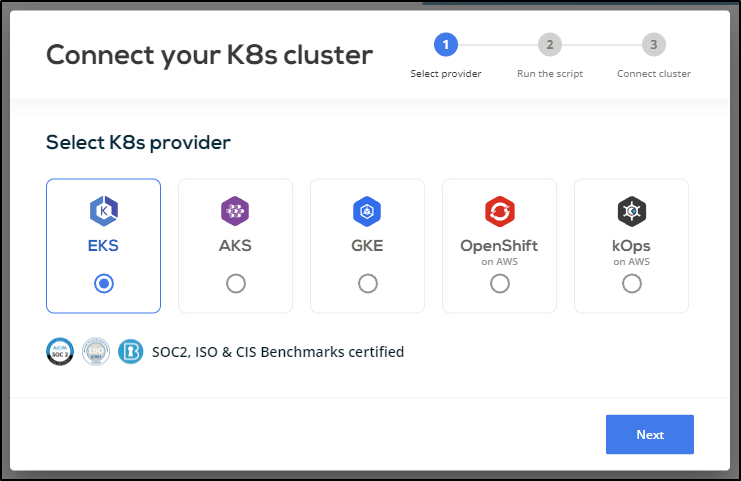
I’ll walk through the “Connect your cluster” wizard, but I was suprised that they just offer three cloud options. Granted, it is the big three. But what about on-prem or other providers like CIVO, Akamai (Linode), or IBM?
It gives a script to run
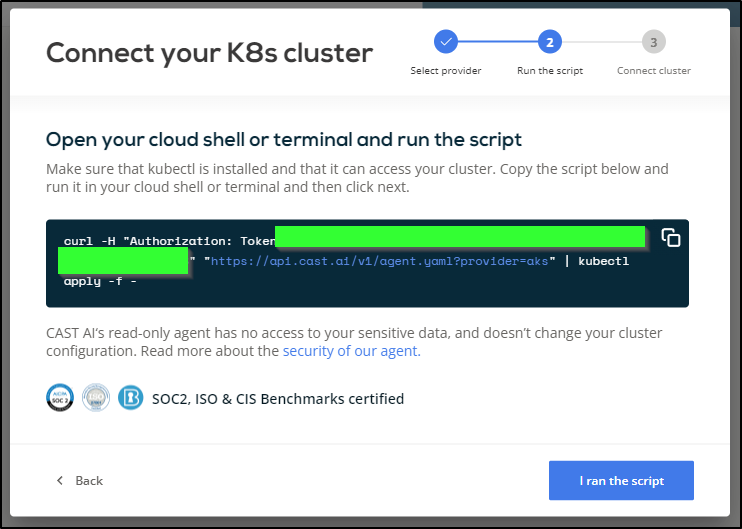
$ curl -H "Authorization: Token asdfasdfasdfsadfasdfasdfasdfasdfasdfasdfasdfasdfasdfasdfasdf" "https://api.cast.ai/v1/agent.yaml?provider=aks" | kubectl apply -f -
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 11276 0 11276 0 0 19644 0 --:--:-- --:--:-- --:--:-- 19644
namespace/castai-agent created
resourcequota/castai-agent-critical-pods created
serviceaccount/castai-agent created
secret/castai-agent created
configmap/castai-agent-autoscaler created
clusterrole.rbac.authorization.k8s.io/castai-agent created
clusterrolebinding.rbac.authorization.k8s.io/castai-agent created
role.rbac.authorization.k8s.io/castai-agent created
rolebinding.rbac.authorization.k8s.io/castai-agent created
deployment.apps/castai-agent-cpvpa created
deployment.apps/castai-agent created
It will then try to connect
Because I lied and really ran this on K3s, there was a consequence - it is crashing the agent pod because of missing env vars
$ kubectl logs -n castai-agent castai-agent-6b854bcd6c-nbjs8
time="2023-04-08T20:27:11Z" level=info msg="running agent version: GitCommit=\"2df460e1e2167de789384209344f7d81ad917b1f\" GitRef=\"refs/tags/v0.42.3\" Version=\"v0.42.3\"" version=v0.42.3
time="2023-04-08T20:27:11Z" level=info msg="platform URL: https://api.cast.ai" version=v0.42.3
time="2023-04-08T20:27:11Z" level=info msg="starting healthz on port: 9876" version=v0.42.3
time="2023-04-08T20:27:11Z" level=info msg="using provider \"aks\"" provider=aks version=v0.42.3
time="2023-04-08T20:27:11Z" level=info msg="starting with leader election" own_identity=b3cbb0a3-23fb-4d2f-9d7d-8fe6a92c4098 provider=aks version=v0.42.3
I0408 20:27:11.750194 1 leaderelection.go:248] attempting to acquire leader lease castai-agent/agent-leader-election-lock...
I0408 20:27:11.771887 1 leaderelection.go:258] successfully acquired lease castai-agent/agent-leader-election-lock
time="2023-04-08T20:27:11Z" level=info msg="started leading" own_identity=b3cbb0a3-23fb-4d2f-9d7d-8fe6a92c4098 provider=aks version=v0.42.3
time="2023-04-08T20:27:13Z" level=error msg="failed to retrieve instance metadata: Get \"http://169.254.169.254/metadata/instance?api-version=2021-05-01&format=json\": context deadline exceeded (Client.Timeout exceeded while awaiting headers)" provider=aks version=v0.42.3
time="2023-04-08T20:27:13Z" level=error msg="agent stopped with an error: registering cluster: autodiscovering cluster metadata: failed to get location metadata: provide required AKS_LOCATION environment variable" provider=aks version=v0.42.3
time="2023-04-08T20:27:13Z" level=info msg="stopped leading" own_identity=b3cbb0a3-23fb-4d2f-9d7d-8fe6a92c4098 provider=aks version=v0.42.3
time="2023-04-08T20:27:13Z" level=info msg="agent shutdown" provider=aks version=v0.42.3
Let’s check deployments
$ kubectl get deployments -n castai-agent
NAME READY UP-TO-DATE AVAILABLE AGE
castai-agent-cpvpa 1/1 1 1 4m40s
castai-agent 0/1 1 0 4m40s
and fix that
builder@DESKTOP-QADGF36:~/Workspaces/testDir$ kubectl get deployment castai-agent -n castai-agent -o yaml > castai-agent.dep.yaml
builder@DESKTOP-QADGF36:~/Workspaces/testDir$ kubectl get deployment castai-agent -n castai-agent -o yaml > castai-agent.dep.yaml.bak
builder@DESKTOP-QADGF36:~/Workspaces/testDir$ vi castai-agent.dep.yaml
builder@DESKTOP-QADGF36:~/Workspaces/testDir$ diff -C7 castai-agent.dep.yaml.bak castai-agent.dep.yaml
*** castai-agent.dep.yaml.bak 2023-04-08 15:30:39.115036005 -0500
--- castai-agent.dep.yaml 2023-04-08 15:32:14.358851045 -0500
***************
*** 69,82 ****
--- 69,84 ----
- env:
- name: API_URL
value: api.cast.ai
- name: PROVIDER
value: aks
- name: PPROF_PORT
value: "6060"
+ - name: AKS_LOCATION
+ value: centralus
+ - name: AKS_SUBSCRIPTION_ID
+ value: d955asdf-adfs-asdf-asf-asdf74cbb22d
+ - name: AKS_NODE_RESOURCE_GROUP
+ value: MyResourceGroup
envFrom:
- secretRef:
name: castai-agent
image: us-docker.pkg.dev/castai-hub/library/agent:v0.42.3
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
$ kubectl apply -f castai-agent.dep.yaml
deployment.apps/castai-agent configured
Now they are running
$ kubectl get pods -n castai-agent
NAME READY STATUS RESTARTS AGE
castai-agent-cpvpa-84d84596b6-skm7g 1/1 Running 0 14m
castai-agent-5666b456c6-h9hbf 1/1 Running 0 56s
I at least initially do not get much, other than a whole lot of server error warnings
Let us be fair, I did jamb this in as a fake AKS cluster.
There are things we can get however
Security Report
Cast.ai does show me by-container security reports which could be useful for finding problematic or risky workloads
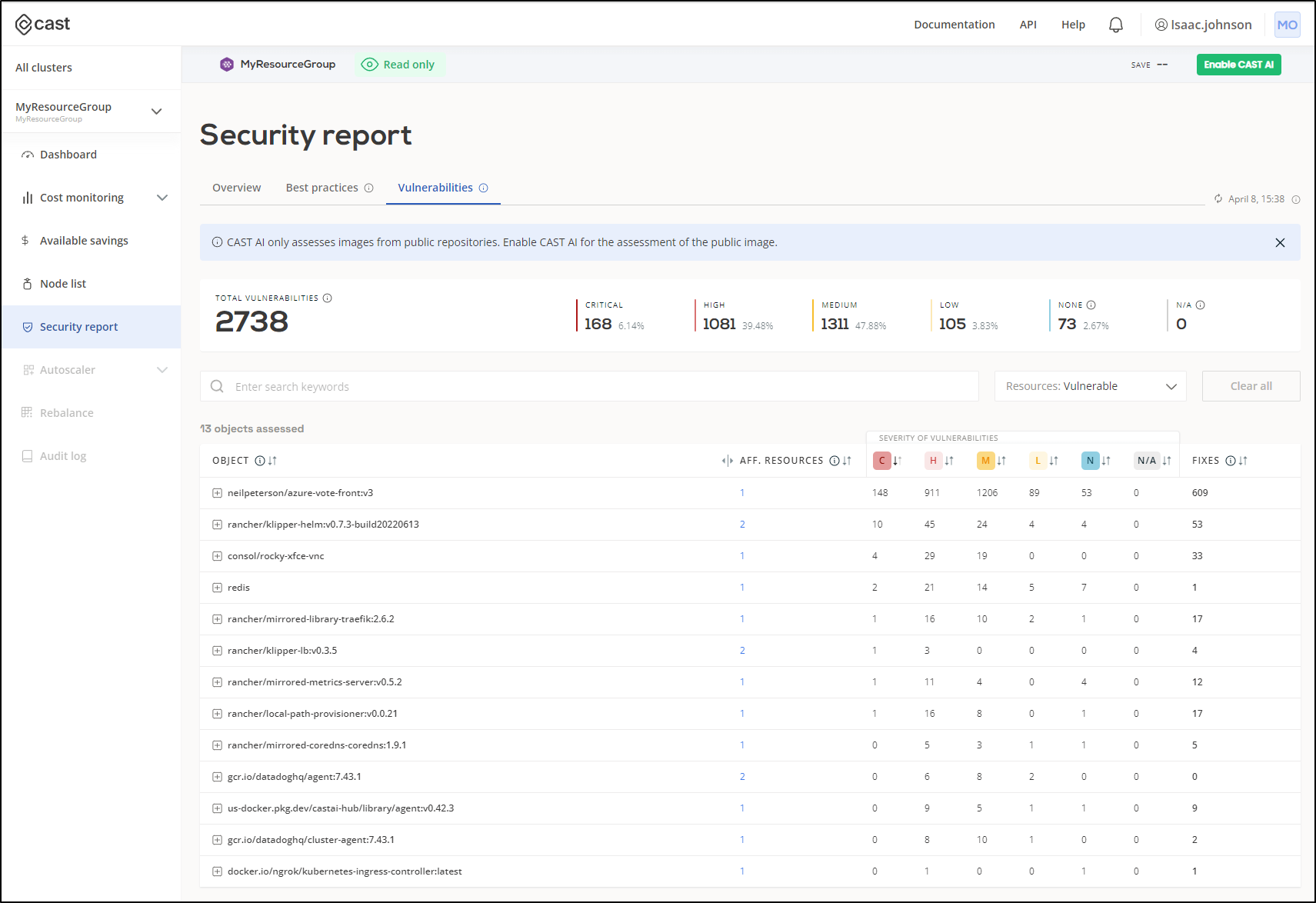
I was able to break down by app and OS a container’s security vulnerabilities and see the underlying CVEs referenced
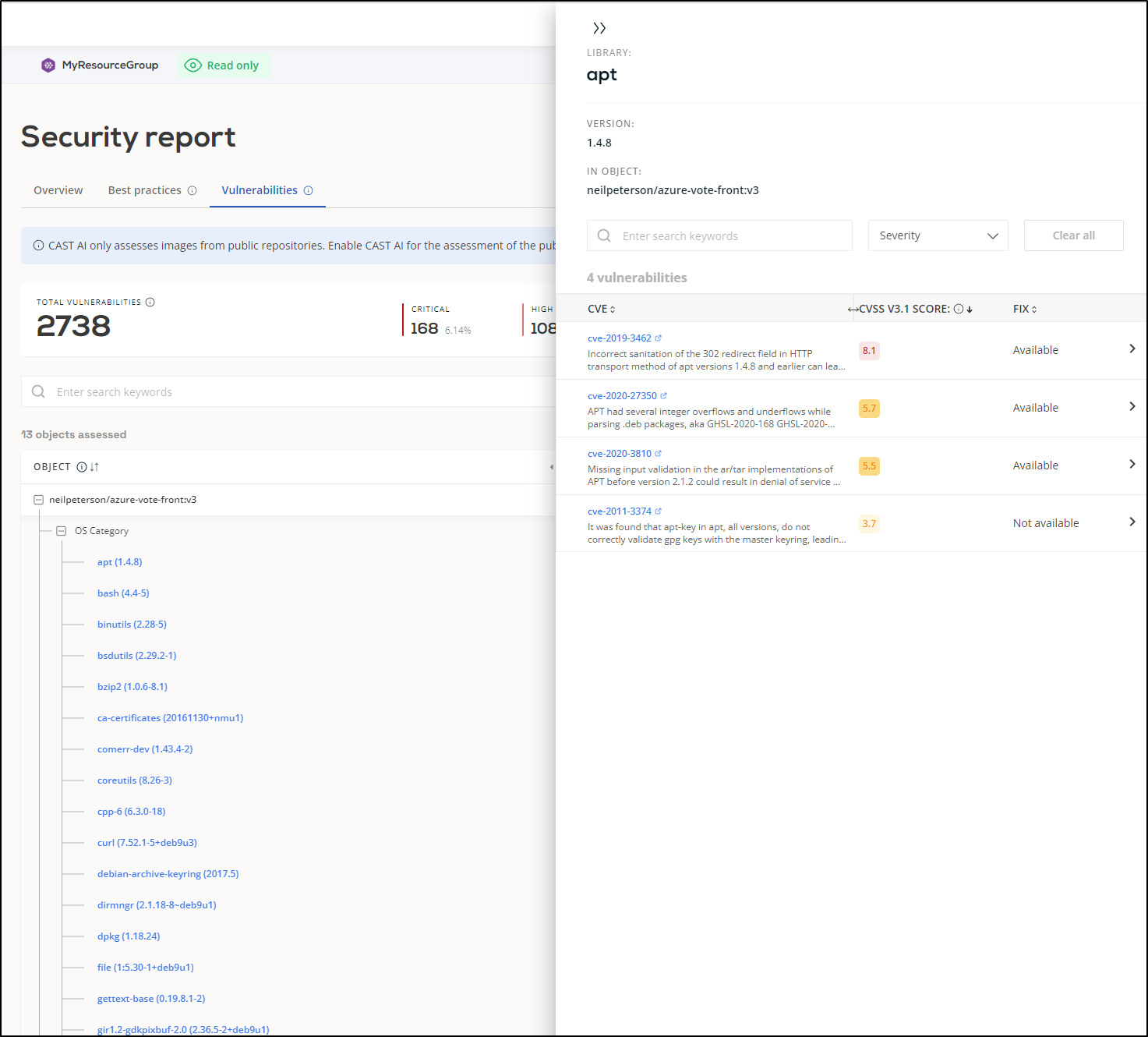
Let’ try updating just one. The oldest, the azure-vote-front:v3 does have an updated image of v4.
The Helm chart doesn’t expose the image, so I’ll have to tweak the deployment manually
$ kubectl get deployments vote-front-azure-vote-1678278477 -o yaml > avf.dep.yaml
builder@DESKTOP-QADGF36:~/Workspaces/testDir$ kubectl get deployments vote-front-azure-vote-1678278477 -o yaml > avf.dep.yaml.bak
$ vi avf.dep.yaml
$ diff -c5 avf.dep.yaml avf.dep.yaml.bak
*** avf.dep.yaml 2023-04-09 11:17:42.448045215 -0500
--- avf.dep.yaml.bak 2023-04-09 11:17:34.198045153 -0500
***************
*** 40,50 ****
value: Azure Vote App
- name: VOTE1VALUE
value: Cats
- name: VOTE2VALUE
value: Dogs
! image: neilpeterson/azure-vote-front:v4
imagePullPolicy: Always
name: azure-vote-front
ports:
- containerPort: 80
protocol: TCP
--- 40,50 ----
value: Azure Vote App
- name: VOTE1VALUE
value: Cats
- name: VOTE2VALUE
value: Dogs
! image: neilpeterson/azure-vote-front:v3
imagePullPolicy: Always
name: azure-vote-front
ports:
- containerPort: 80
protocol: TCP
$ kubectl apply -f avf.dep.yaml
Warning: resource deployments/vote-front-azure-vote-1678278477 is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
deployment.apps/vote-front-azure-vote-1678278477 configured
$ kubectl get pods | grep vote
vote-back-azure-vote-1678278477-7dc4cf9668-gfxvw 1/1 Running 0 8d
vote-front-azure-vote-1678278477-67bb8bb55c-k9cxj 1/1 Running 0 78s
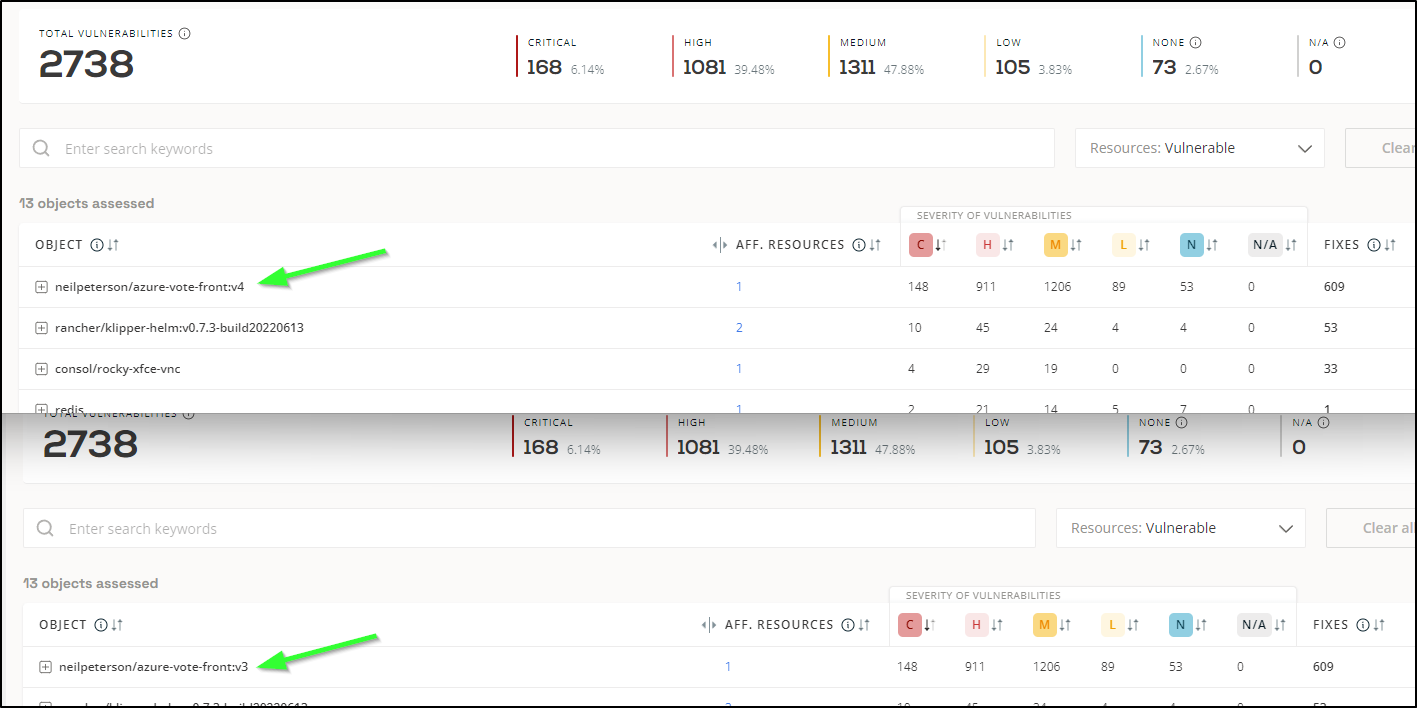
which within a few hours synced to the Vulnerabilities page (sadly, did not improve things)
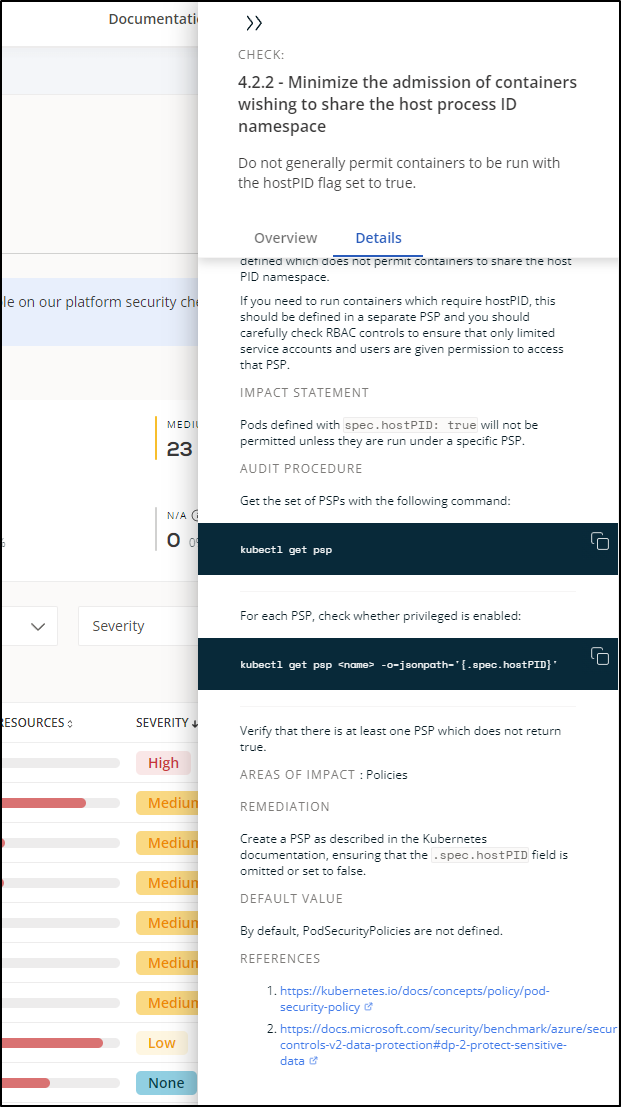
I can also see some “Best Practices”. The first was marked high “4.2.2 - Minimize the admission of containers wishing to share the host process ID namespace”.
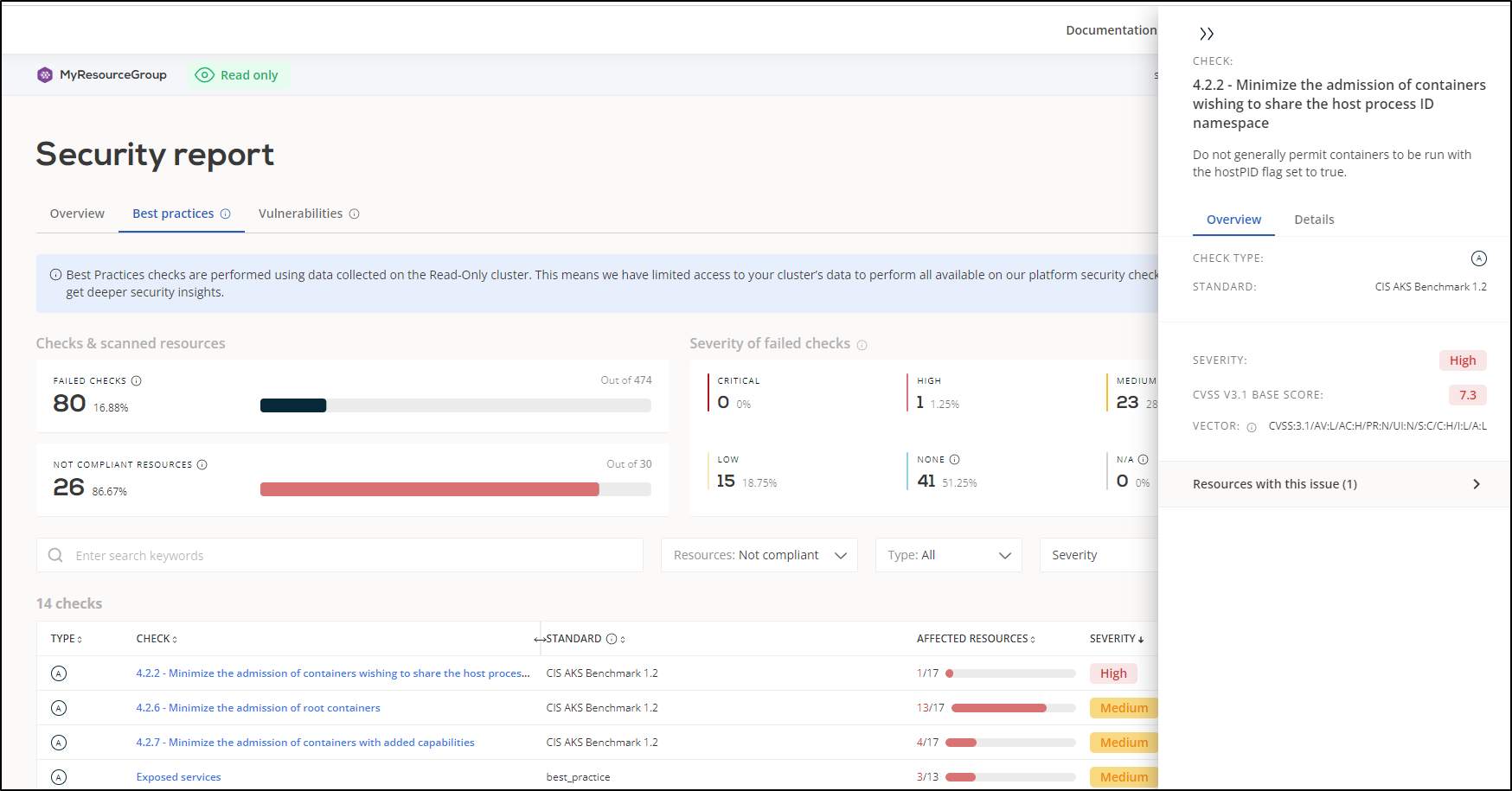
What was nice is that I could the “Resources with this issue (1)” item to see more details.
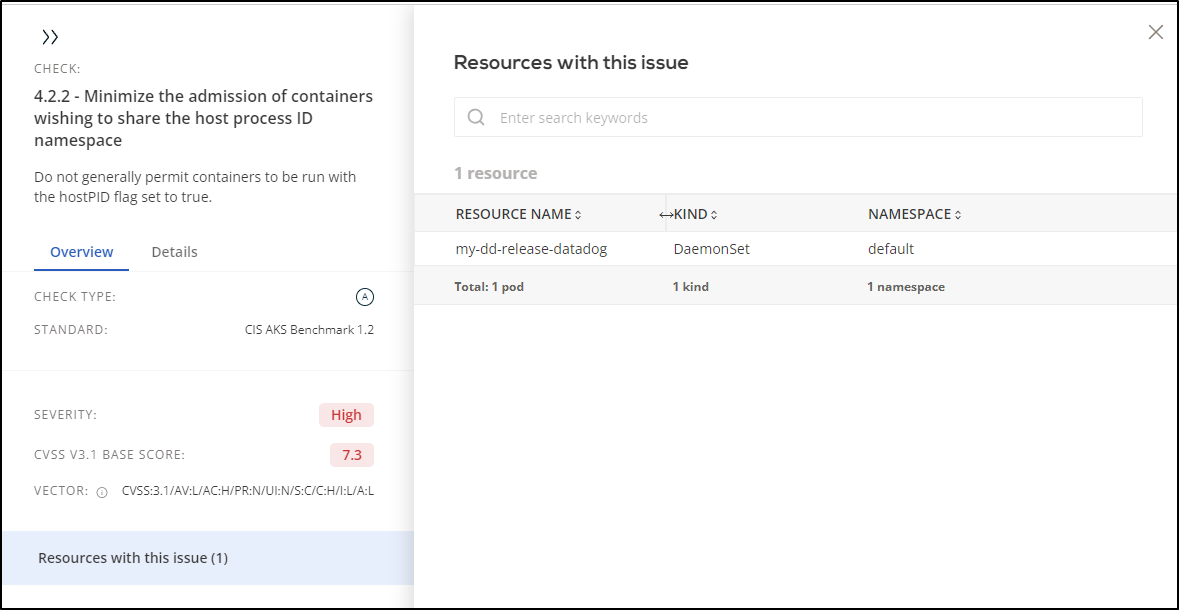
In this case, it’s my Datadog agent which I want to do low level monitoring, so it’s okay
The other super handy item, which makes Cast.ai exceed other tools like Whitesource Bolt, is the details that show both how to identity but more importantly, how to remediate the issue
Node list
It pointed out one of my nodes was having an issue
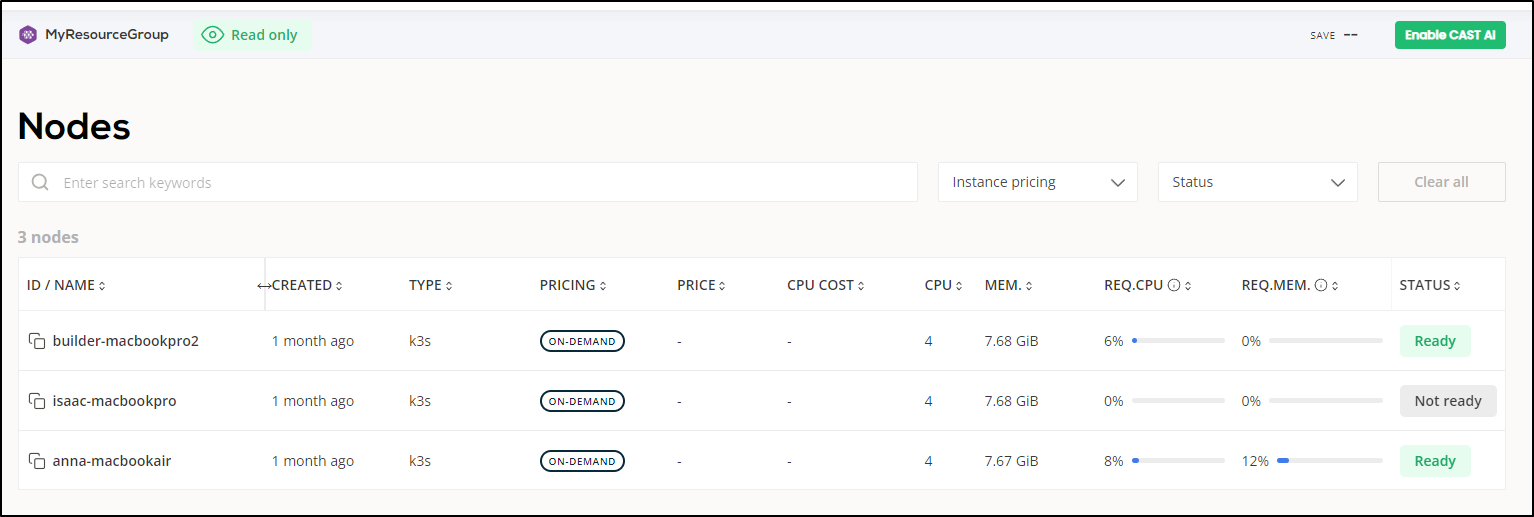
Which a local check confirmed
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
isaac-macbookpro NotReady <none> 32d v1.23.10+k3s1
anna-macbookair Ready control-plane,master 32d v1.23.10+k3s1
builder-macbookpro2 Ready <none> 32d v1.23.10+k3s1
Indeed, something had knocked the power cord from my old Macbook Pro node. I plugged it back in and powered up

Which, once booted, shows ready
AKS
Let’s create a real AKS cluster just to see it in action
I’ll make a basic AKS Dev/Test cluster
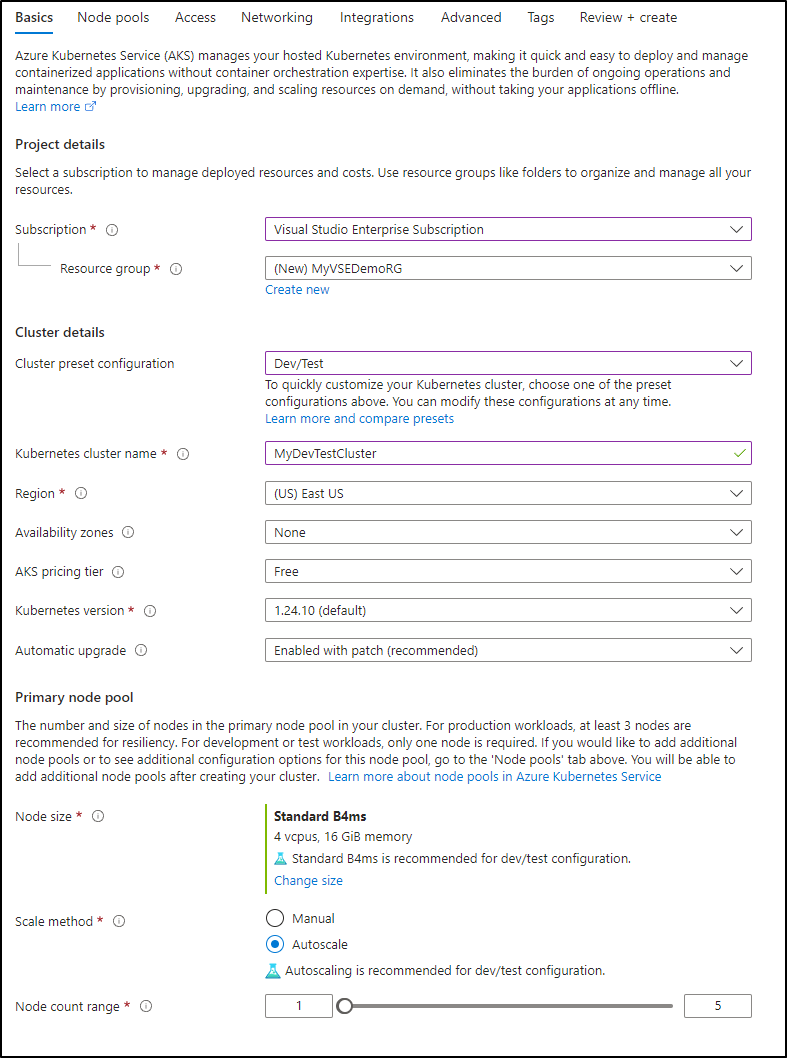
I’ll enable burstable nodes which means I must use Azure CNI networking

We can login to the cluster
$ az aks get-credentials --name MyDevTestCluster -g MyVSEDemoRG --admin
Merged "MyDevTestCluster-admin" as current context in /home/builder/.kube/config
$ kubectx
MyDevTestCluster-admin
Then add it
$ curl -H "Authorization: Token 96sdasdfasdfasdfasdfasdfasdfsadfasdfsadfasdfasdf35" "https://api.cast.ai/v1/agent.yaml?provider=aks" | kubectl apply -f -
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 11276 0 11276 0 0 49893 0 --:--:-- --:--:-- --:--:-- 49893
namespace/castai-agent created
resourcequota/castai-agent-critical-pods created
serviceaccount/castai-agent created
secret/castai-agent created
configmap/castai-agent-autoscaler created
clusterrole.rbac.authorization.k8s.io/castai-agent created
clusterrolebinding.rbac.authorization.k8s.io/castai-agent created
role.rbac.authorization.k8s.io/castai-agent created
rolebinding.rbac.authorization.k8s.io/castai-agent created
deployment.apps/castai-agent-cpvpa created
deployment.apps/castai-agent created
This time we can see results that look fine
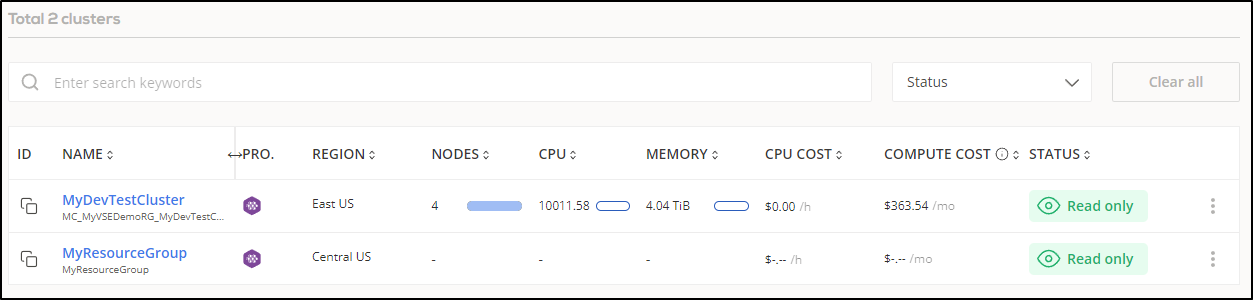
Right off the bat we can see some suggestions
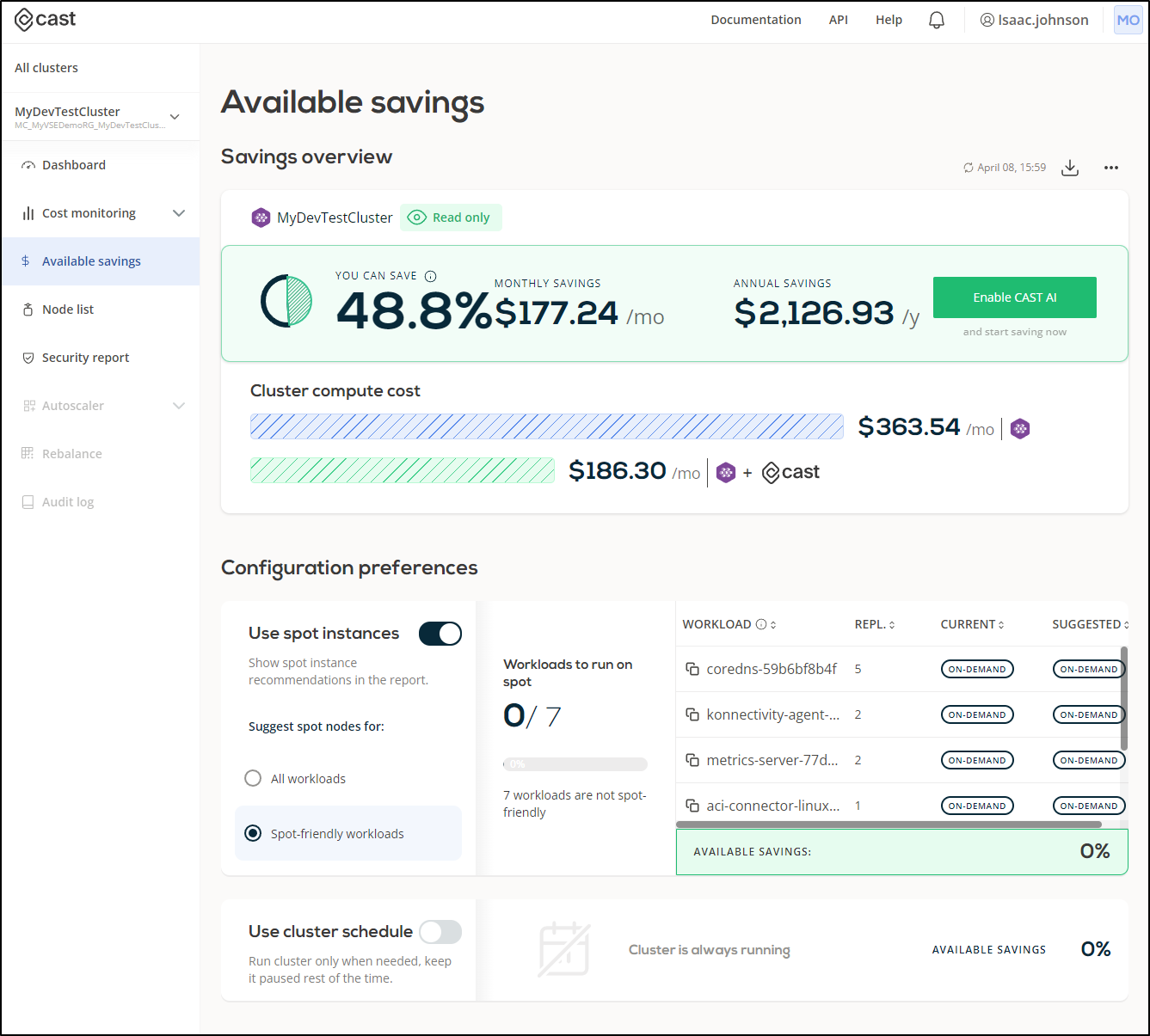
I’ll “Enable CAST AI”
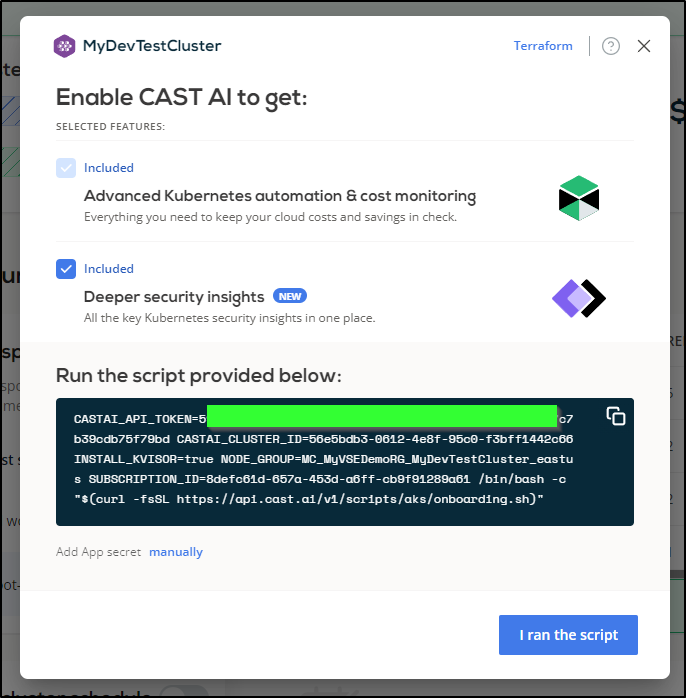
$ CASTAI_API_TOKEN=59530b23be91aa81fe237e53db2fbe4bda92fa5c489e09cd7c7b39cdb75f79bd CASTAI_CLUSTER_ID=56e5bdb3-0612-4e8f-95c0-f3bff1442c66 INSTALL_KVISOR=true NODE_GROUP=MC_MyVSEDemoRG_MyDevTestCluster_eastus SUBSCRIPTION_ID=8defc61d-657a-453d-a6ff-cb9f91289a61 /bin/bash -c "$(curl -fsSL https://api.cast.ai/v1/scripts/aks/onboarding.sh)"
Setting active subscription: Visual Studio Enterprise Subscription
Fetching cluster information
Creating custom role: 'CastAKSRole-56e5bdb3'
Creating app registration: 'CAST.AI MyDevTestCluster-56e5bdb3'
Creating app secret: 'MyDevTestCluster-castai'
Creating service principal
Assigning role to 'CAST.AI MyDevTestCluster-56e5bdb3' app
Role 'CastAKSRole-56e5bdb3' doesn't exist.
Still executing...
Installing castai-cluster-controller.
"castai-helm" has been added to your repositories
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "myharbor" chart repository
...Successfully got an update from the "freshbrewed" chart repository
...Successfully got an update from the "castai-helm" chart repository
...Successfully got an update from the "uptime-kuma" chart repository
...Successfully got an update from the "confluentinc" chart repository
...Successfully got an update from the "adwerx" chart repository
...Successfully got an update from the "kuma" chart repository
...Successfully got an update from the "actions-runner-controller" chart repository
...Successfully got an update from the "ngrok" chart repository
...Successfully got an update from the "dapr" chart repository
...Successfully got an update from the "azure-samples" chart repository
...Successfully got an update from the "rhcharts" chart repository
...Successfully got an update from the "sonarqube" chart repository
...Successfully got an update from the "hashicorp" chart repository
...Successfully got an update from the "novum-rgi-helm" chart repository
...Successfully got an update from the "epsagon" chart repository
...Successfully got an update from the "longhorn" chart repository
...Successfully got an update from the "sumologic" chart repository
...Successfully got an update from the "open-telemetry" chart repository
...Successfully got an update from the "nginx-stable" chart repository
...Successfully got an update from the "lifen-charts" chart repository
...Successfully got an update from the "kubecost" chart repository
...Successfully got an update from the "rook-release" chart repository
...Successfully got an update from the "elastic" chart repository
...Successfully got an update from the "datadog" chart repository
...Successfully got an update from the "harbor" chart repository
...Successfully got an update from the "argo-cd" chart repository
...Successfully got an update from the "incubator" chart repository
...Successfully got an update from the "rancher-latest" chart repository
...Successfully got an update from the "crossplane-stable" chart repository
...Successfully got an update from the "newrelic" chart repository
...Successfully got an update from the "gitlab" chart repository
...Successfully got an update from the "bitnami" chart repository
Update Complete. ⎈Happy Helming!⎈
Release "cluster-controller" does not exist. Installing it now.
NAME: cluster-controller
LAST DEPLOYED: Sat Apr 8 16:01:47 2023
NAMESPACE: castai-agent
STATUS: deployed
REVISION: 1
TEST SUITE: None
Finished installing castai-cluster-controller.
Installing castai-spot-handler.
Release "castai-spot-handler" does not exist. Installing it now.
NAME: castai-spot-handler
LAST DEPLOYED: Sat Apr 8 16:01:50 2023
NAMESPACE: castai-agent
STATUS: deployed
REVISION: 1
TEST SUITE: None
Finished installing castai-azure-spot-handler.
Installing castai-evictor.
Release "castai-evictor" does not exist. Installing it now.
NAME: castai-evictor
LAST DEPLOYED: Sat Apr 8 16:01:52 2023
NAMESPACE: castai-agent
STATUS: deployed
REVISION: 1
TEST SUITE: None
Finished installing castai-evictor.
Release "castai-kvisor" does not exist. Installing it now.
NAME: castai-kvisor
LAST DEPLOYED: Sat Apr 8 16:01:54 2023
NAMESPACE: castai-agent
STATUS: deployed
REVISION: 1
TEST SUITE: None
Finished installing castai-kvisor.
--------------------------------------------------------------------------------
Your generated credentials:
{ "subscriptionId": "8defc61d-657a-453d-a6ff-cb9f91289a61", "tenantId": "15d19784-ad58-4a57-a66f-ad1c0f826a45", "clientId": "97c90266-f530-4f22-8964-5e207dbc46e5", "clientSecret": "glO8Q~j-U6OZ43RPQ4Y.4eIhCTz-1QP.yvfILcYO" }
Sending credentials to CAST AI console...
Request failed with error: {"message":"Bad Request", "fieldViolations":[{"field":"credentials", "description":"invalid credentials: graphrbac.ApplicationsClient#GetServicePrincipalsIDByAppID: Failure responding to request: StatusCode=401 -- Original Error: autorest/azure: Service returned an error. Status=401 Code=\"Unknown\" Message=\"Unknown service error\" Details=[{\"odata.error\":{\"code\":\"Authorization_IdentityNotFound\",\"date\":\"2023-04-08T21:01:57\",\"message\":{\"lang\":\"en\",\"value\":\"The identity of the calling application could not be established.\"},\"requestId\":\"e8fb9964-1ab3-4bc8-978f-eaf0ee627f76\"}}]"}]}
Will retry after 10 seconds ...
Still executing...
Successfully sent.
We can see it came back with a Security Insights indicator
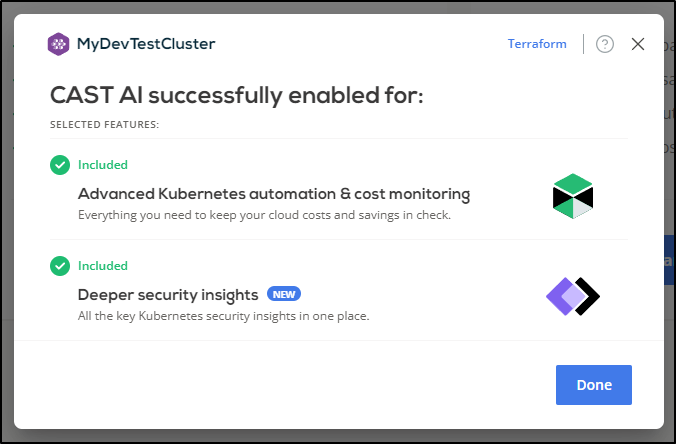
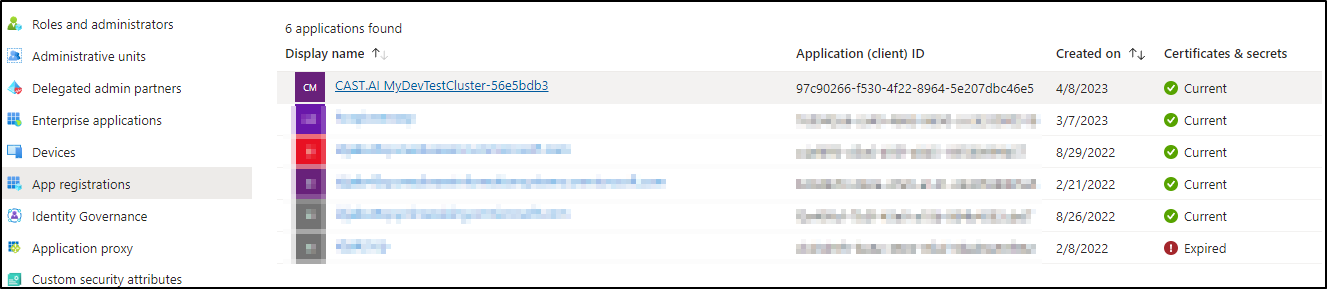
I was a bit surprised to see it actually created a new App Reg/SP ID during the process
Though it didn’t add any excessive perms
We can setup Cast AI to be the autoscaler
We can set some policies to scale and use spot instances
We can see current costs
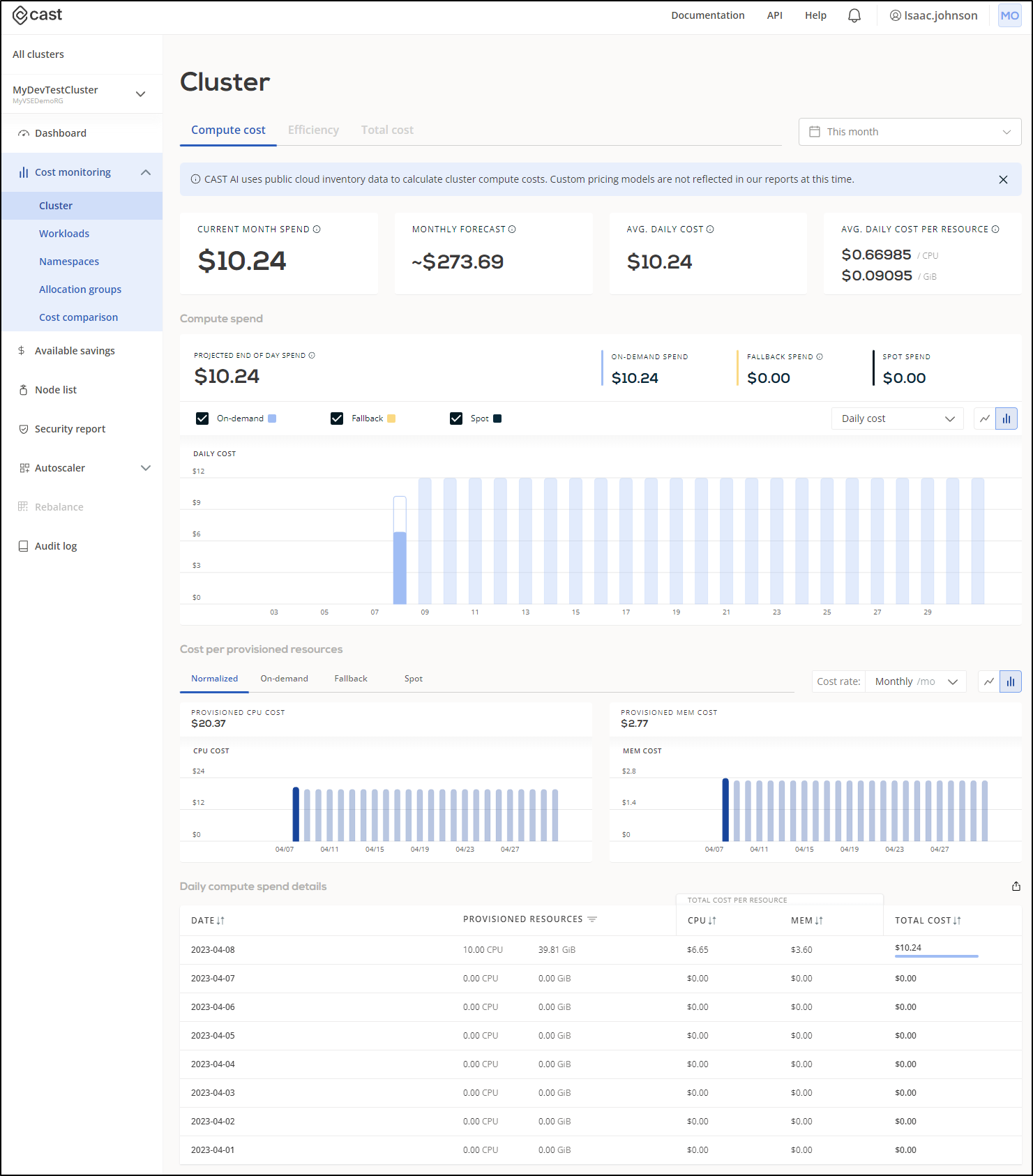
This is actually pretty handy as even after 12h, Azure had yet to put together cost reporting, but I could see some specifics in cast
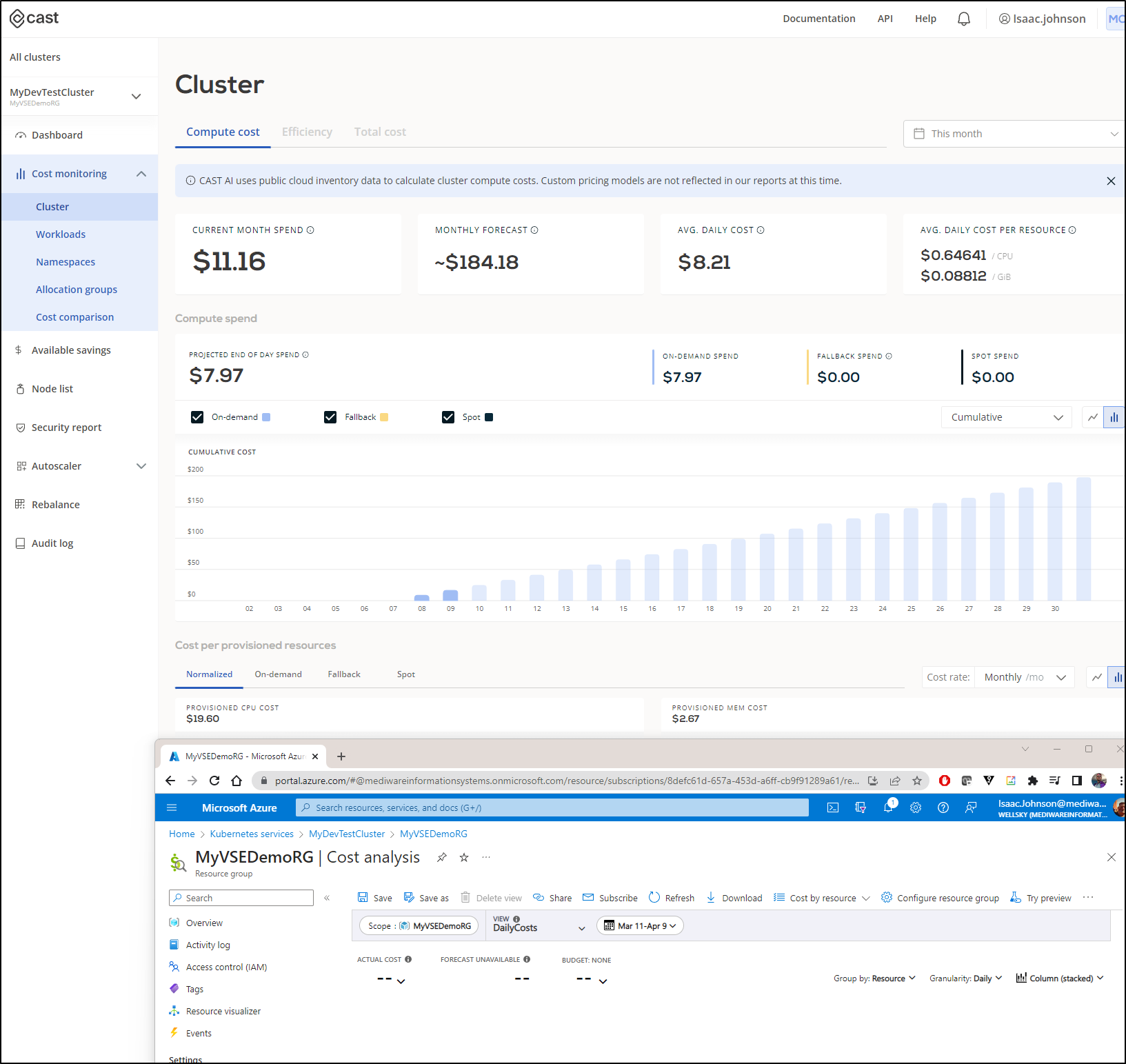
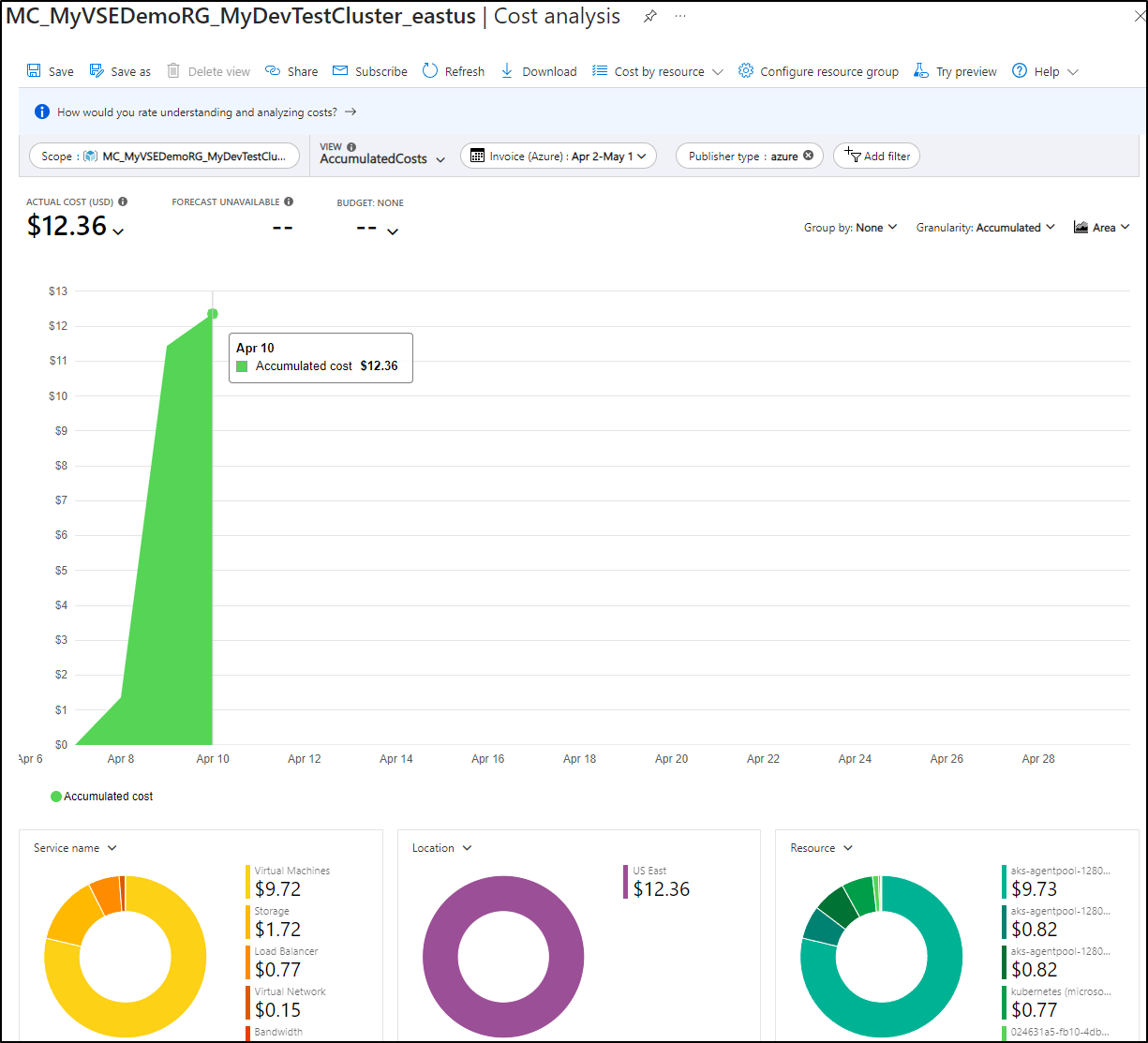
The question remains about accuracy. For instance, the report above suggests I’ve spent US$11.16 this month on the cluster. However, I chose a Dev/Test class cluster where the control plane is free (boo Microsoft. It used to be always free). So I just need to see the results of the MC (managed cluster) resource group to see current spent:
This shows it is more like $0.61 thus far. I’ll give it a few days and check back to see if they are just time shifted, but that is a pretty big difference
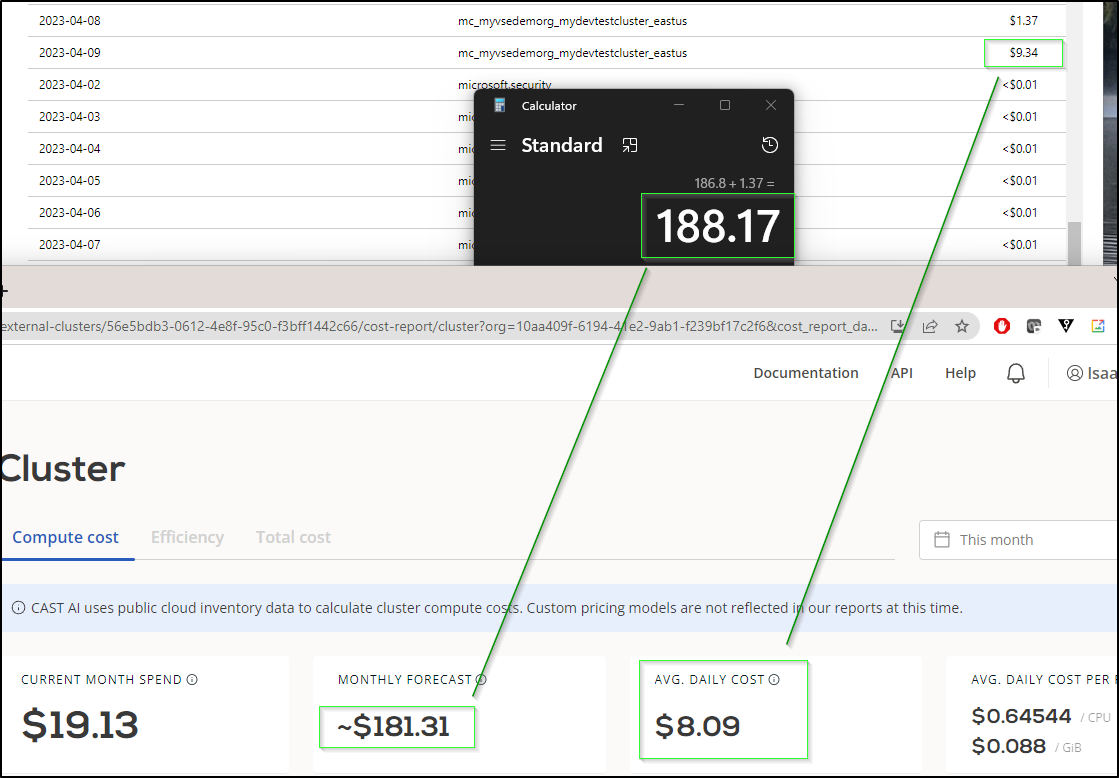
I came back the next day and saw that Cast predicted EOD spend to be US$19.13
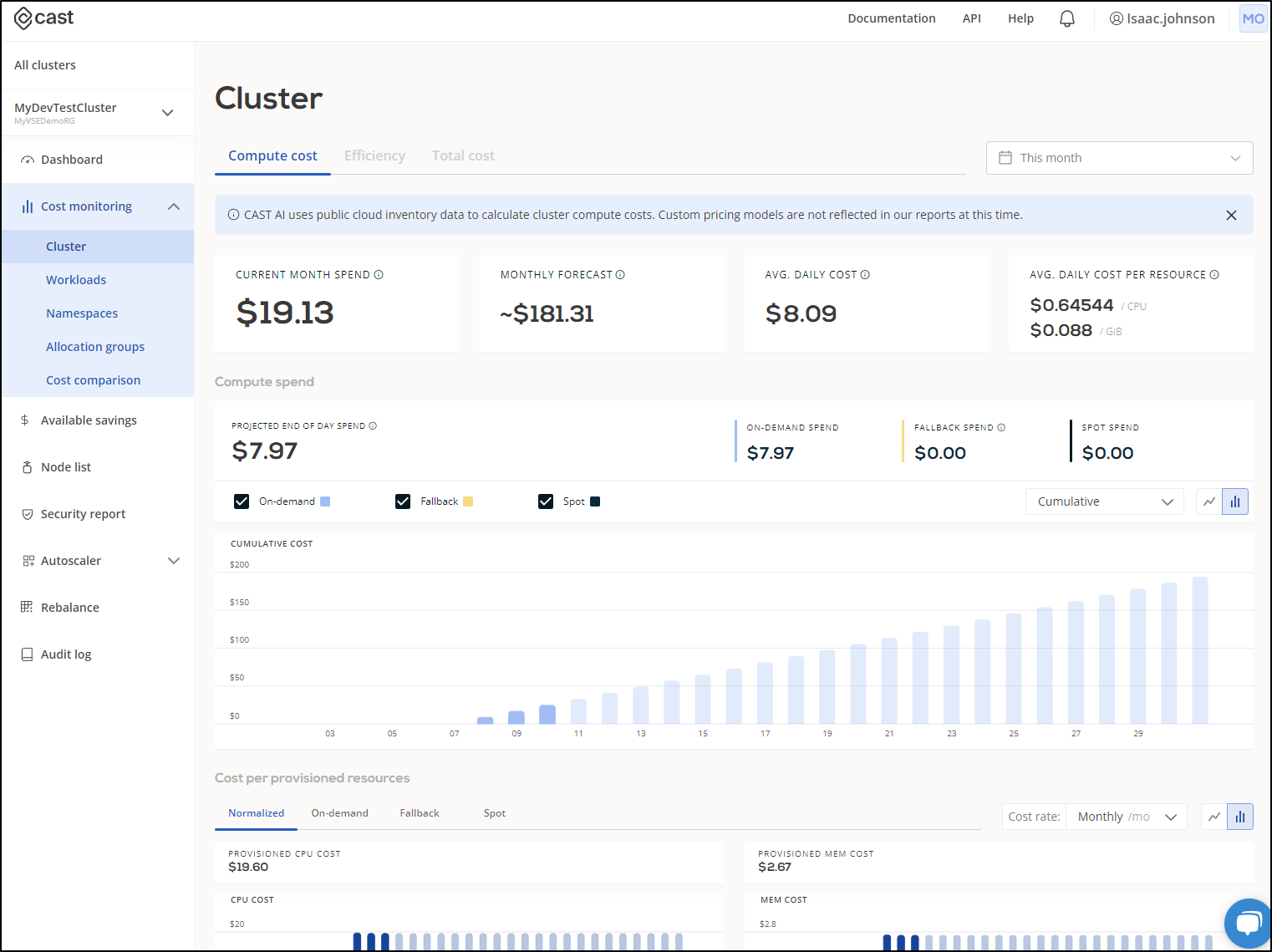
Azure showed the billed amount for yesterday was $10.71. I suspect the number will get closer inline over time.
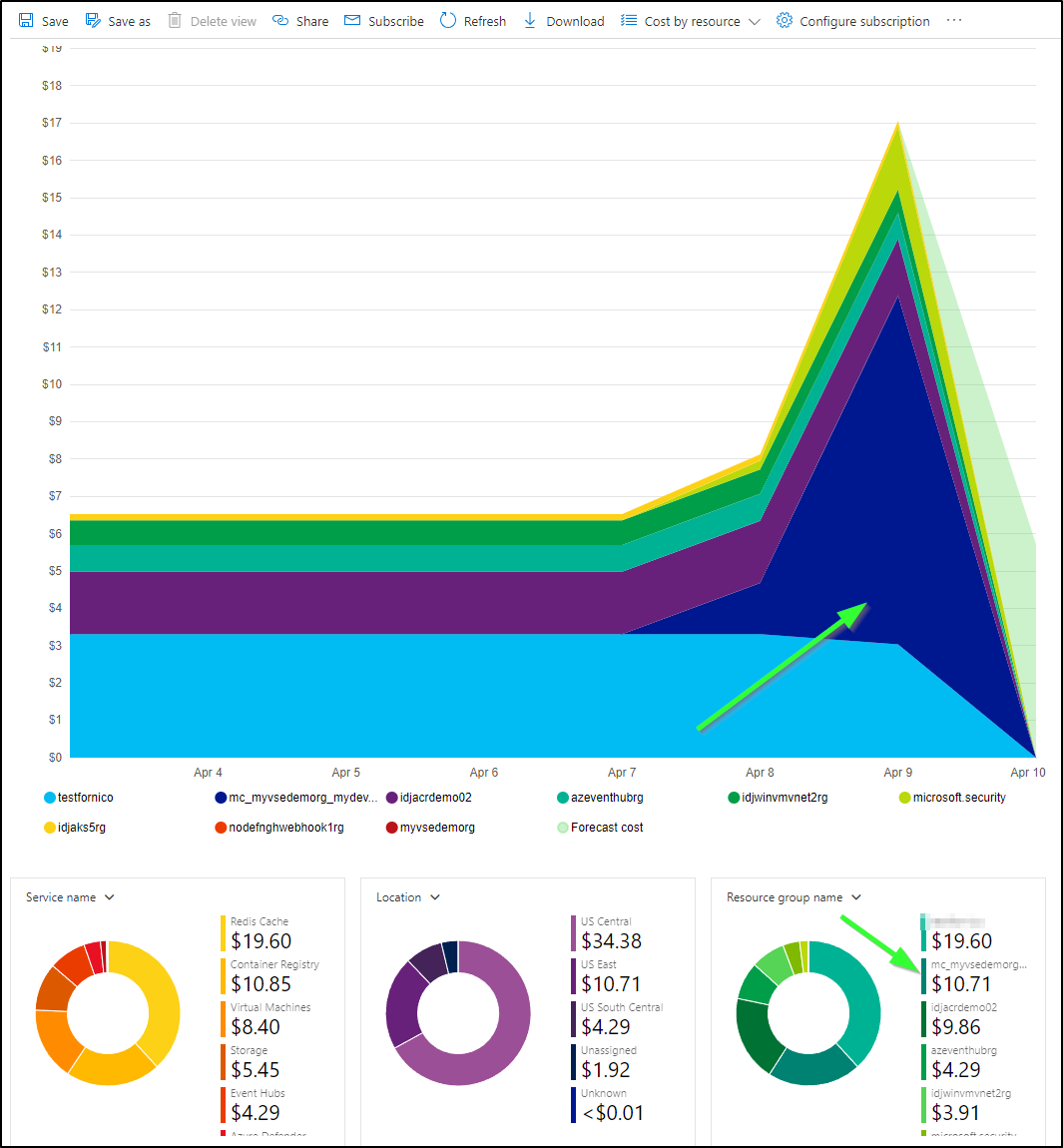
In fact, if I add the initial $1.37 to the current daily $9.34 and project out to the end of April (20*9.34 + 1.37) that would total $188.17 which is pretty darn close
Cost by Workload
This assumes we can trust the total cost, however, assuming that we can see a breakdown of relative cost by namespaces
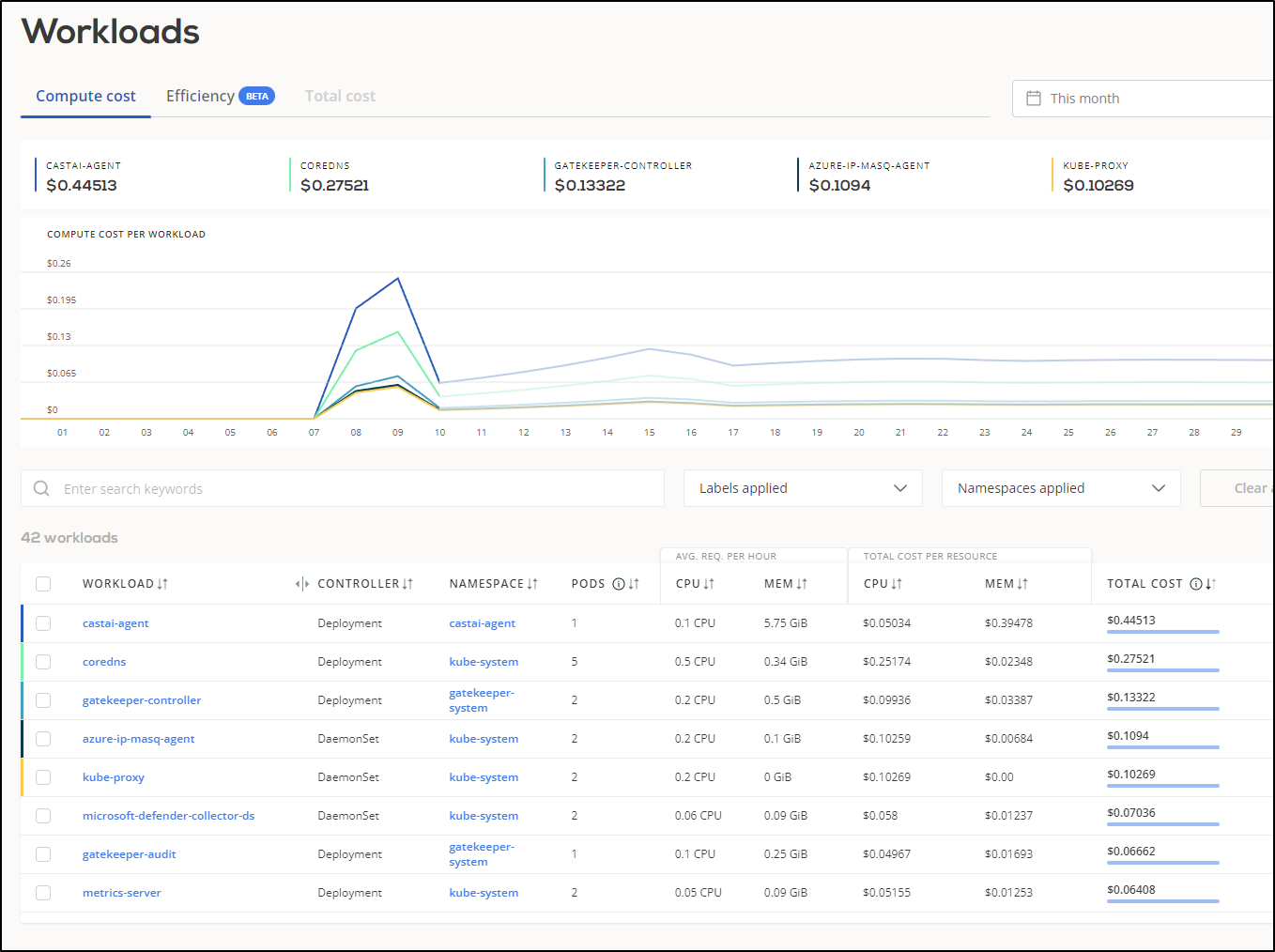
Which is either an aggregation or subset of what Azure calls workloads
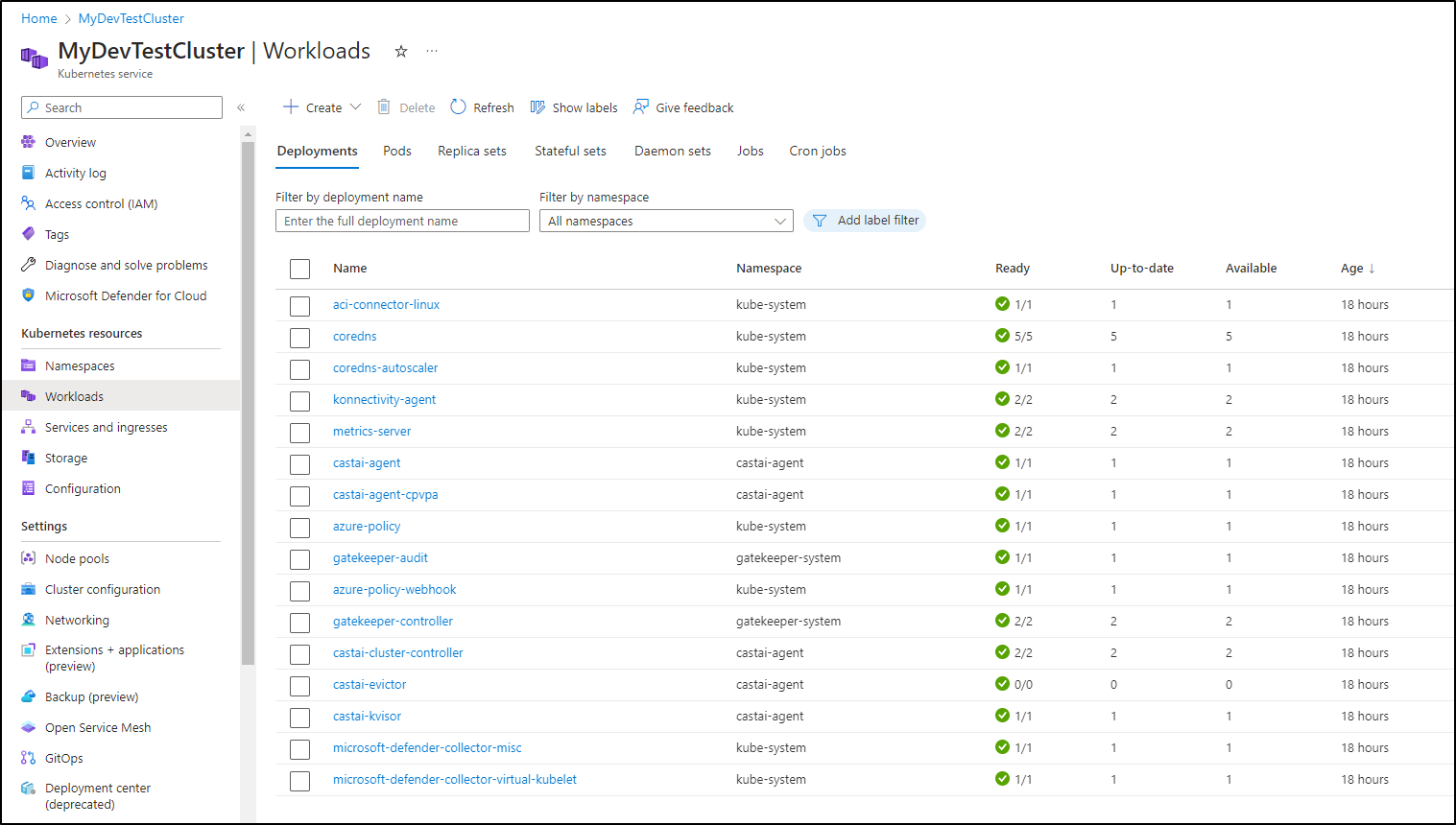
The results in Azure match deployments
$ kubectl get deployments --all-namespaces
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
castai-agent castai-agent 1/1 1 1 18h
castai-agent castai-agent-cpvpa 1/1 1 1 18h
castai-agent castai-cluster-controller 2/2 2 2 18h
castai-agent castai-evictor 0/0 0 0 18h
castai-agent castai-kvisor 1/1 1 1 18h
gatekeeper-system gatekeeper-audit 1/1 1 1 18h
gatekeeper-system gatekeeper-controller 2/2 2 2 18h
kube-system aci-connector-linux 1/1 1 1 18h
kube-system azure-policy 1/1 1 1 18h
kube-system azure-policy-webhook 1/1 1 1 18h
kube-system coredns 5/5 5 5 18h
kube-system coredns-autoscaler 1/1 1 1 18h
kube-system konnectivity-agent 2/2 2 2 18h
kube-system metrics-server 2/2 2 2 18h
kube-system microsoft-defender-collector-misc 1/1 1 1 17h
kube-system microsoft-defender-collector-virtual-kubelet 1/1 1 1 17h
I thought perhaps Helm deploys, but I only see Cast.ai there
$ helm list --all-namespaces
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
castai-evictor castai-agent 1 2023-04-08 16:01:52.386588429 -0500 CDT deployed castai-evictor-0.21.23 7b8ac7fa265461f86ffb5c255e7891e7b1e5e353
castai-kvisor castai-agent 1 2023-04-08 16:01:54.618311791 -0500 CDT deployed castai-kvisor-0.16.24 v0.27.1
castai-spot-handler castai-agent 1 2023-04-08 16:01:50.351671727 -0500 CDT deployed castai-spot-handler-0.18.1 v0.11.0
cluster-controller castai-agent 1 2023-04-08 16:01:47.560913705 -0500 CDT deployed castai-cluster-controller-0.49.1 v0.34.2
The number of Nodes I’ve add thus far is 3, with one being a spot instance
$ kubectl get nodes --all-namespaces
NAME STATUS ROLES AGE VERSION
aks-agentpool-12803503-vmss000000 Ready agent 18h v1.24.10
aks-agentpool-12803503-vmss000003 Ready agent 18h v1.24.10
virtual-node-aci-linux Ready agent 18h v1.19.10-vk-azure-aci-1.4.8
I believe that 3rd Virtual is there for when needed, but doesn’t actually exist as provisioned infrastructure until used
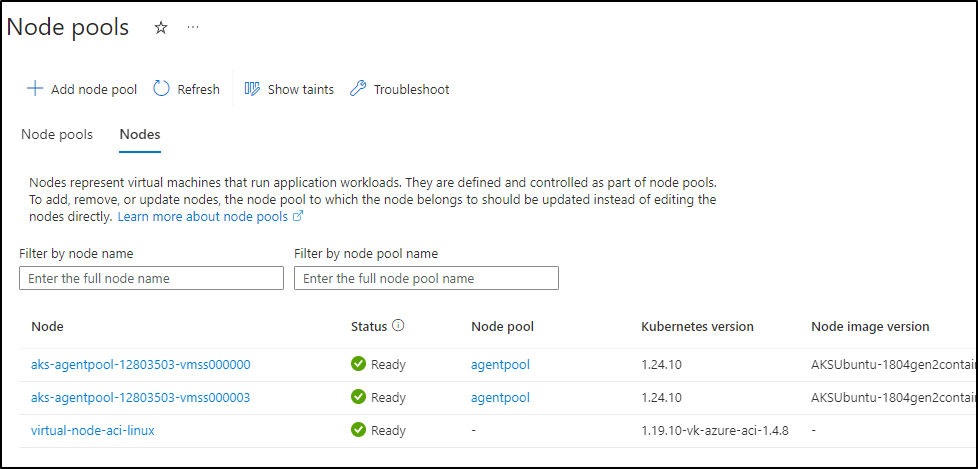
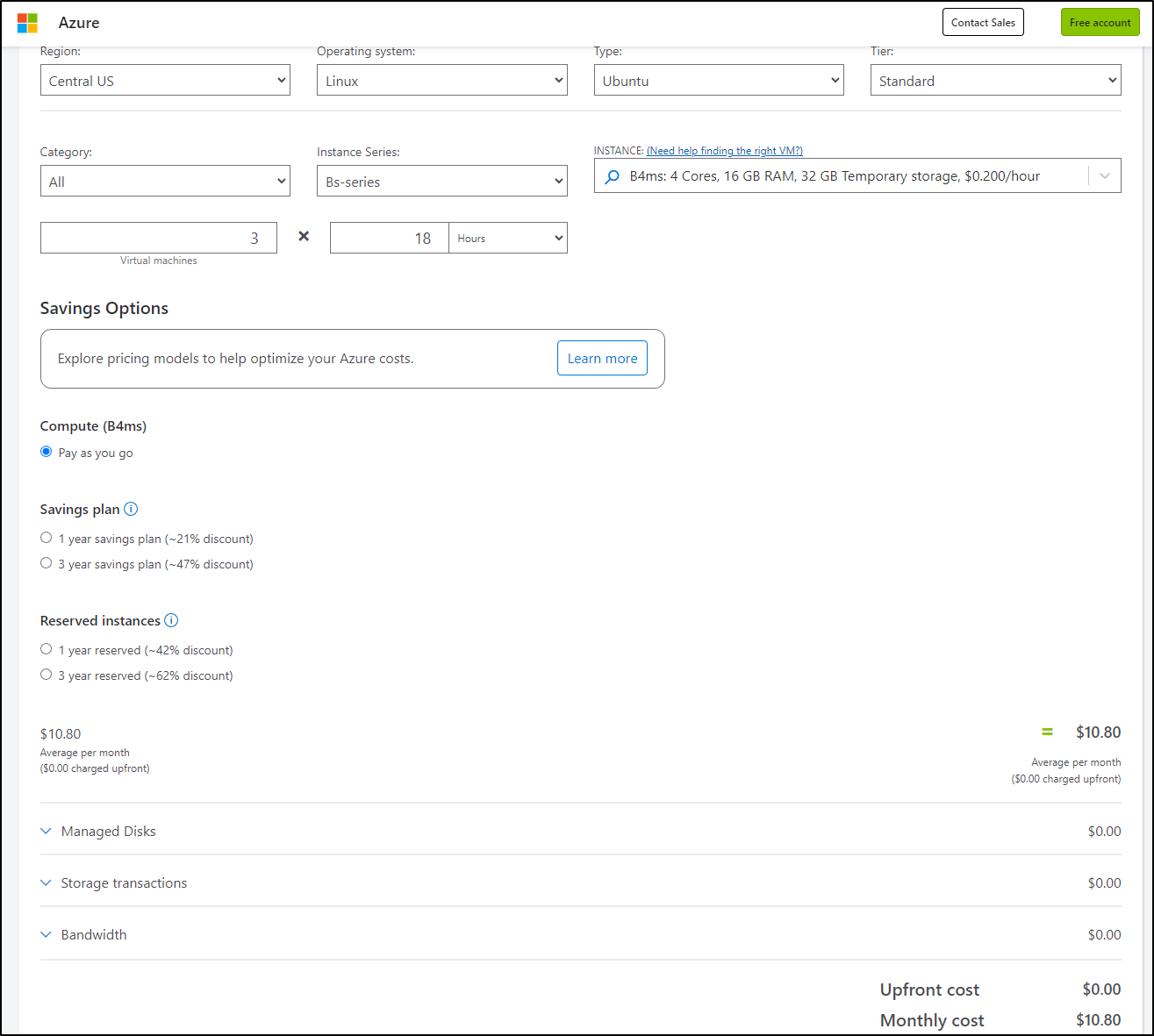
If Cast.ai didn’t really account for the Virtual, it might see 3 nodes and know the class is B4ms. Totaling the 18 hours, that would get close the total we saw
One thing I noticed is that after I had setup Cast.ai to optimize the cluster, it created some Cast Node Pools
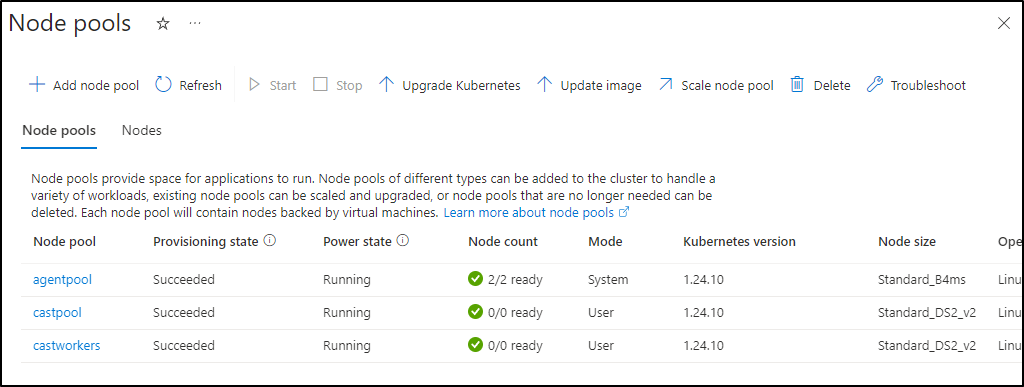
I see they have taints to keep them from scheduling. But both pools were set to not use Azure Spot Instances.
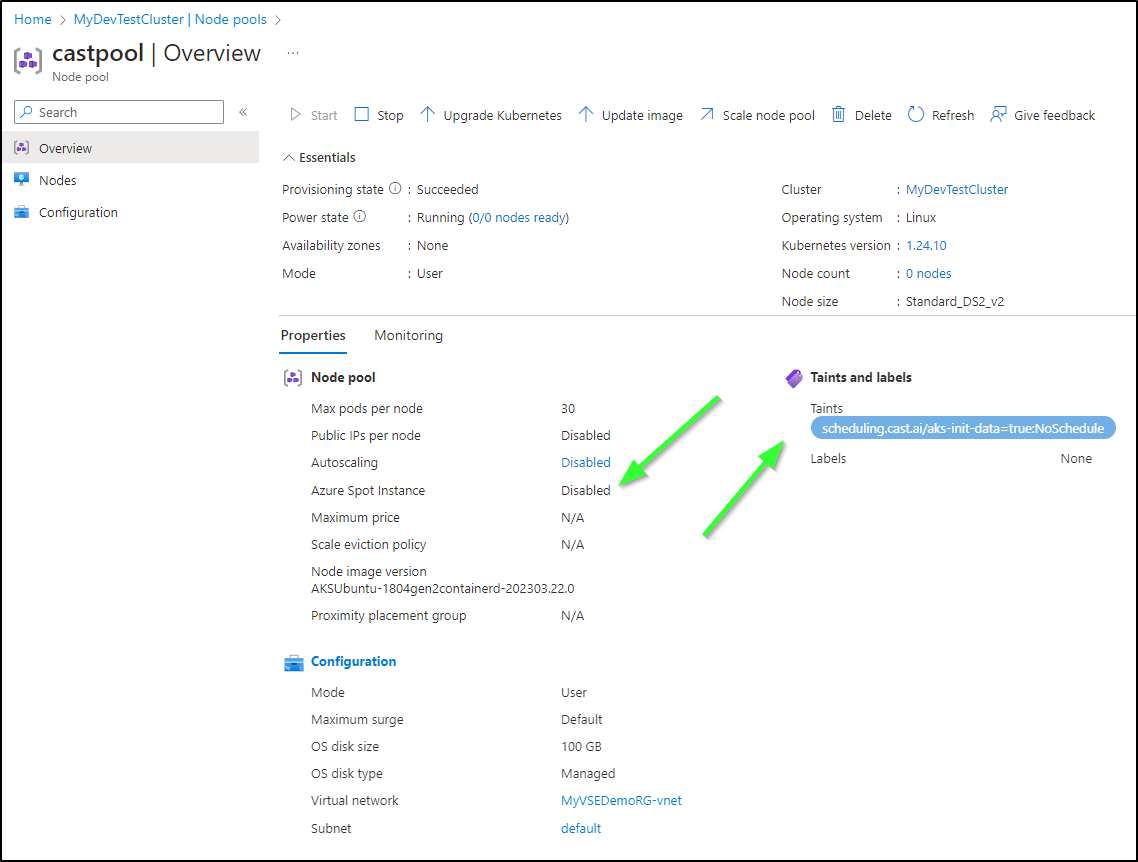
This is where I have a touch of a struggle. My cluster was setup to use Azure Virtual Nodes which essentially scale out to ACI for per-second pricing on pods. If there is sustained usage, then a VM is scheduled.
Slam the Cluster
Let’s slam the cluster with 100 Busy Boxes. I used a JFelten chart (which I modified here)
builder@DESKTOP-QADGF36:~/Workspaces/ijohnson-helm-charts$ helm install hundredbusyboxes ./charts/busybox/ --set replicaCount=100
NAME: hundredbusyboxes
LAST DEPLOYED: Mon Apr 10 06:17:29 2023
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Congratulations your kubernetes cluster is even busier!
To get busy with this pod:
export POD_NAME=$(kubectl get pods --namespace default -l "app=hundredbusyboxes-busybox" -o jsonpath="{.items[0].metadata.name}")
kubectl exec -it $POD_NAME sh
builder@DESKTOP-QADGF36:~/Workspaces/ijohnson-helm-charts$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hundredbusyboxes-busybox-d95874867-27fgx 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-2q72x 0/1 Running 0 25s
hundredbusyboxes-busybox-d95874867-2rk42 1/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-44ghm 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-488xx 0/1 Running 0 25s
hundredbusyboxes-busybox-d95874867-4fnx2 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-4hn77 0/1 Running 0 24s
hundredbusyboxes-busybox-d95874867-4jgwk 0/1 Pending 0 26s
hundredbusyboxes-busybox-d95874867-4p9nn 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-4rtld 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-5c8fg 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-5n926 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-5px9l 0/1 ContainerCreating 0 28s
hundredbusyboxes-busybox-d95874867-6cnvt 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-6hxdx 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-6w4zg 0/1 Running 0 25s
hundredbusyboxes-busybox-d95874867-728xh 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-76chl 1/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-777gw 0/1 Pending 0 28s
hundredbusyboxes-busybox-d95874867-79kxx 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-7dcbp 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-7dpnn 0/1 Running 0 25s
hundredbusyboxes-busybox-d95874867-7fsdr 0/1 Running 0 26s
hundredbusyboxes-busybox-d95874867-8wwgb 0/1 Running 0 26s
hundredbusyboxes-busybox-d95874867-9462c 0/1 Pending 0 25s
hundredbusyboxes-busybox-d95874867-b84qw 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-bdf4q 0/1 ContainerCreating 0 25s
hundredbusyboxes-busybox-d95874867-bgp9t 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-cbfnv 0/1 Pending 0 28s
hundredbusyboxes-busybox-d95874867-cblhp 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-cxssm 0/1 Pending 0 26s
hundredbusyboxes-busybox-d95874867-d2ppc 0/1 Pending 0 26s
hundredbusyboxes-busybox-d95874867-d9n72 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-dwbv5 0/1 ContainerCreating 0 28s
hundredbusyboxes-busybox-d95874867-f2cqb 0/1 Running 0 26s
hundredbusyboxes-busybox-d95874867-f6992 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-f6lv8 0/1 Running 0 26s
hundredbusyboxes-busybox-d95874867-f8d9d 1/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-fgpr9 0/1 ContainerCreating 0 28s
hundredbusyboxes-busybox-d95874867-fjkrj 0/1 Running 0 28s
hundredbusyboxes-busybox-d95874867-fw7sm 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-fwfdh 0/1 Running 0 27s
hundredbusyboxes-busybox-d95874867-fzvcw 0/1 Pending 0 25s
hundredbusyboxes-busybox-d95874867-g28cb 0/1 Running 0 25s
hundredbusyboxes-busybox-d95874867-g92gf 0/1 ContainerCreating 0 25s
hundredbusyboxes-busybox-d95874867-gkwnb 0/1 Running 0 26s
... snip ...
within a minute or so they were all running
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
hundredbusyboxes-busybox-d95874867-27fgx 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-2q72x 1/1 Running 0 6m13s
hundredbusyboxes-busybox-d95874867-2rk42 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-44ghm 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-488xx 1/1 Running 0 6m13s
hundredbusyboxes-busybox-d95874867-4fnx2 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-4hn77 1/1 Running 0 6m12s
hundredbusyboxes-busybox-d95874867-4jgwk 1/1 Running 0 6m14s
hundredbusyboxes-busybox-d95874867-4p9nn 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-4rtld 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-5c8fg 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-5n926 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-5px9l 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-6cnvt 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-6hxdx 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-6w4zg 1/1 Running 0 6m13s
hundredbusyboxes-busybox-d95874867-728xh 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-76chl 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-777gw 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-79kxx 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-7dcbp 1/1 Running 0 6m15s
hundredbusyboxes-busybox-d95874867-7dpnn 1/1 Running 0 6m13s
hundredbusyboxes-busybox-d95874867-7fsdr 1/1 Running 0 6m14s
hundredbusyboxes-busybox-d95874867-8wwgb 1/1 Running 0 6m14s
hundredbusyboxes-busybox-d95874867-9462c 1/1 Running 0 6m13s
hundredbusyboxes-busybox-d95874867-b84qw 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-bdf4q 1/1 Running 0 6m13s
hundredbusyboxes-busybox-d95874867-bgp9t 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-cbfnv 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-cblhp 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-cxssm 1/1 Running 0 6m14s
hundredbusyboxes-busybox-d95874867-d2ppc 1/1 Running 0 6m14s
hundredbusyboxes-busybox-d95874867-d9n72 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-dwbv5 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-f2cqb 1/1 Running 0 6m14s
hundredbusyboxes-busybox-d95874867-f6992 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-f6lv8 1/1 Running 0 6m14s
hundredbusyboxes-busybox-d95874867-f8d9d 1/1 Running 0 6m16s
hundredbusyboxes-busybox-d95874867-fgpr9 1/1 Running 0 6m16s
...
Yet I had no new nodes
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-12803503-vmss000000 Ready agent 38h v1.24.10
aks-agentpool-12803503-vmss000003 Ready agent 38h v1.24.10
virtual-node-aci-linux Ready agent 38h v1.19.10-vk-azure-aci-1.4.8
Now I’m rather stumped on how to push this cluster over the edge.
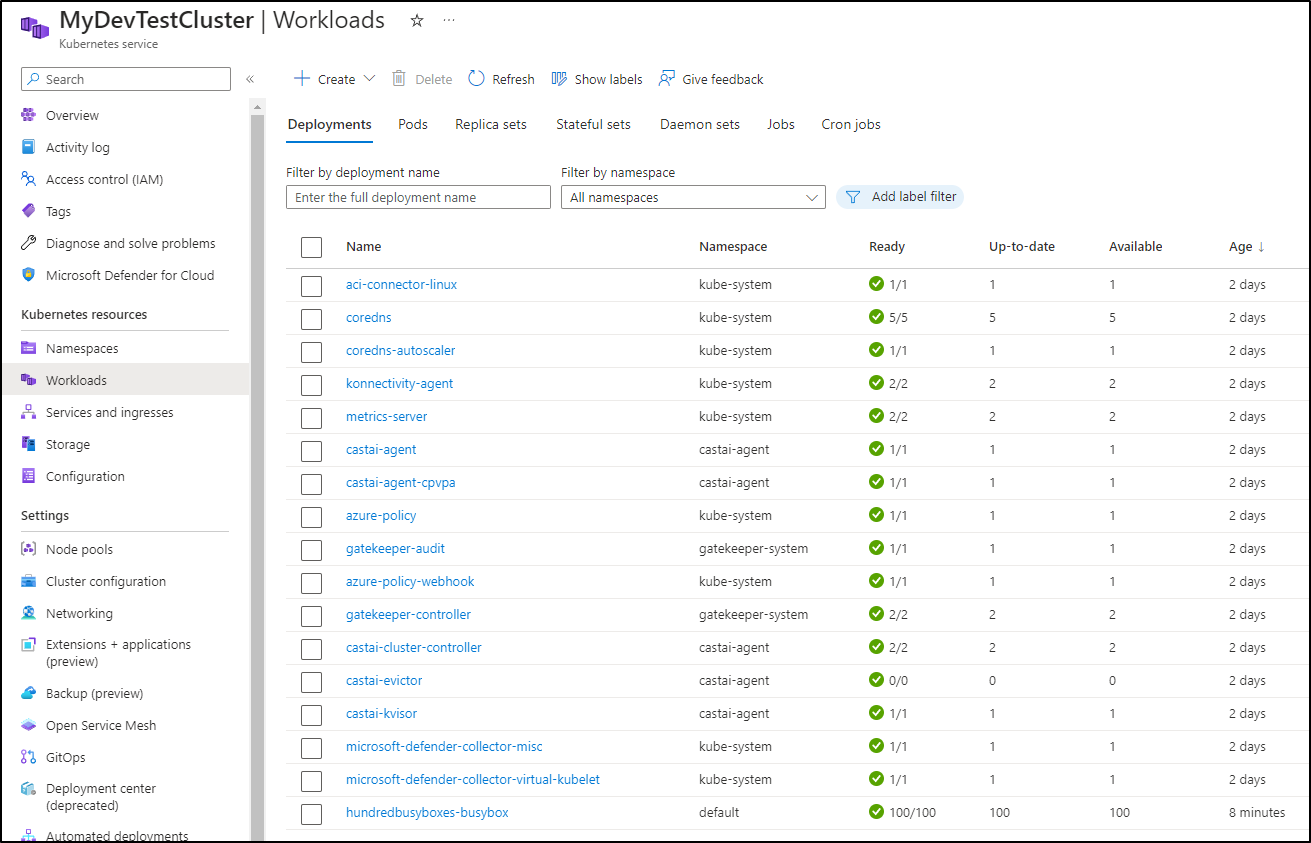
As they all seem to fit on one node
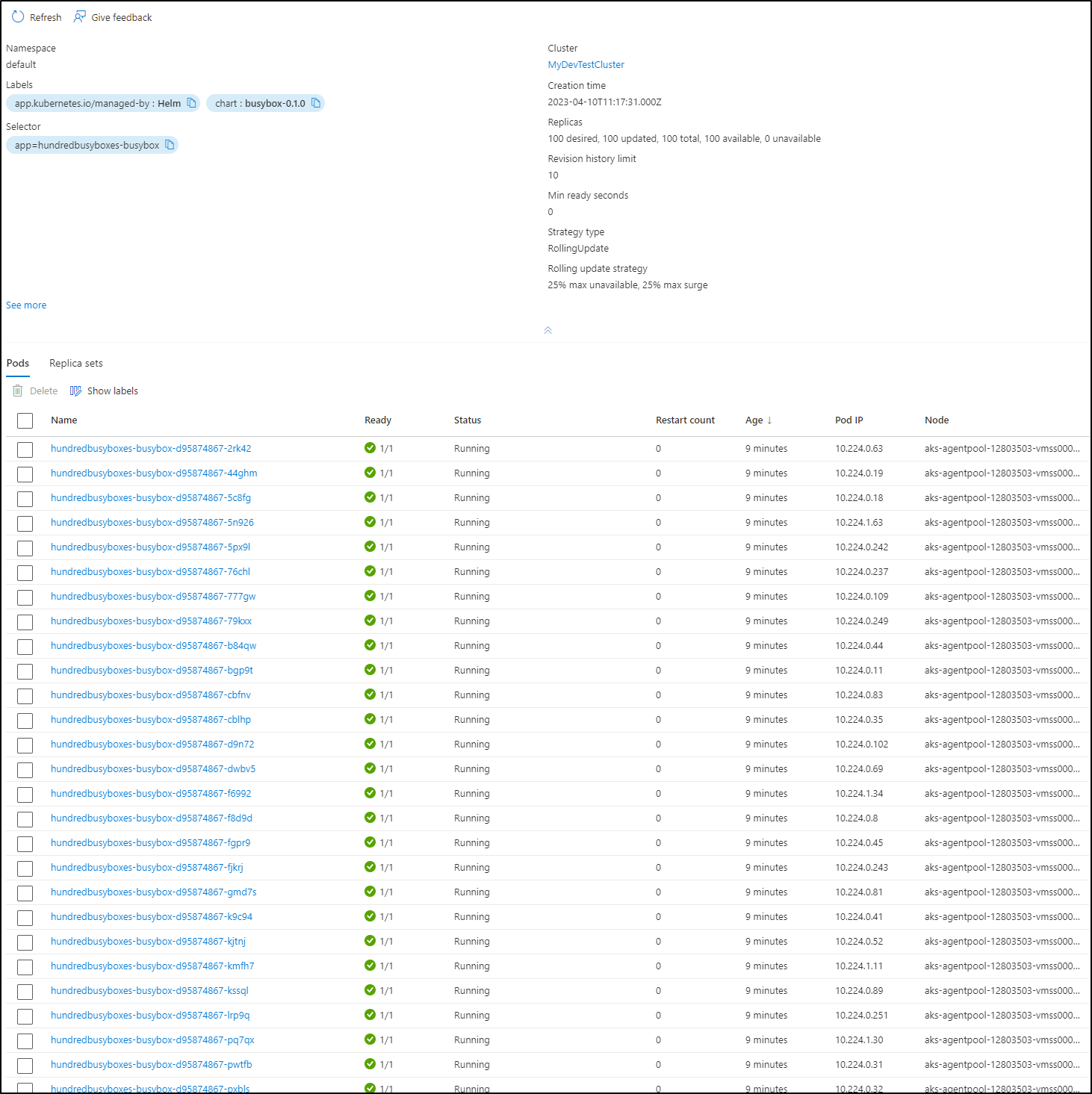
What about 1000?
$ helm upgrade hundredbusyboxes ./charts/busybox/ --set replicaCount=1000
Release "hundredbusyboxes" has been upgraded. Happy Helming!
NAME: hundredbusyboxes
LAST DEPLOYED: Mon Apr 10 06:27:08 2023
NAMESPACE: default
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
Congratulations your kubernetes cluster is even busier!
To get busy with this pod:
export POD_NAME=$(kubectl get pods --namespace default -l "app=hundredbusyboxes-busybox" -o jsonpath="{.items[0].metadata.name}")
kubectl exec -it $POD_NAME sh
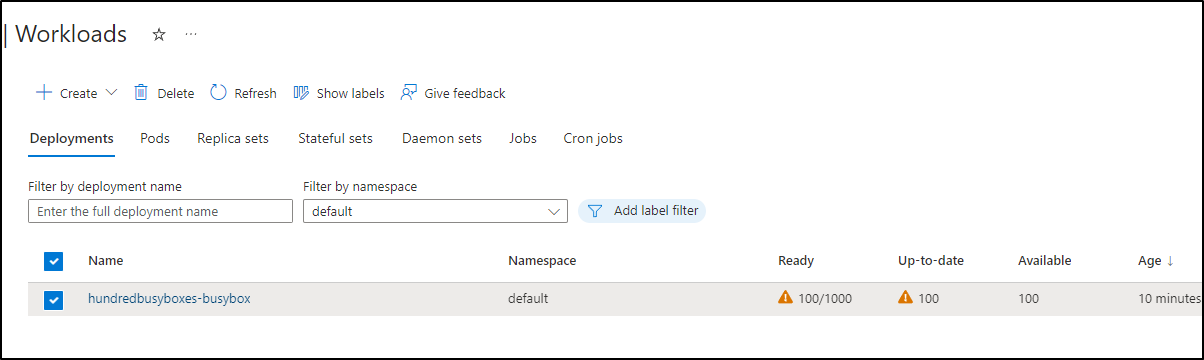
That seemed to add some nodes
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-12803503-vmss000000 Ready agent 38h v1.24.10
aks-agentpool-12803503-vmss000003 Ready agent 38h v1.24.10
aks-agentpool-12803503-vmss000004 NotReady <none> 1s v1.24.10
aks-agentpool-12803503-vmss000005 NotReady <none> 3s v1.24.10
aks-agentpool-12803503-vmss000006 NotReady <none> 4s v1.24.10
virtual-node-aci-linux Ready agent 38h v1.19.10-vk-azure-aci-1.4.8
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-agentpool-12803503-vmss000000 Ready agent 38h v1.24.10
aks-agentpool-12803503-vmss000003 Ready agent 38h v1.24.10
aks-agentpool-12803503-vmss000004 Ready agent 28s v1.24.10
aks-agentpool-12803503-vmss000005 Ready agent 30s v1.24.10
aks-agentpool-12803503-vmss000006 Ready agent 31s v1.24.10
virtual-node-aci-linux Ready agent 38h v1.19.10-vk-azure-aci-1.4.8
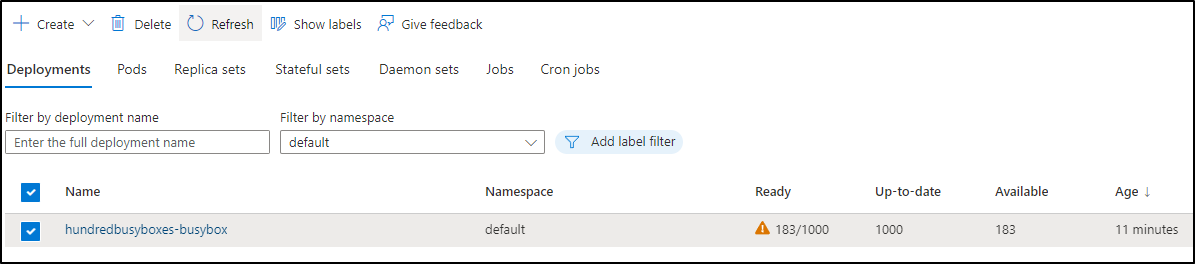
However, as it scales out, nothing is failing just yet
$ kubectl get pods -o json | jq -r '.items[] | .status.phase' | sort -u
Pending
Running
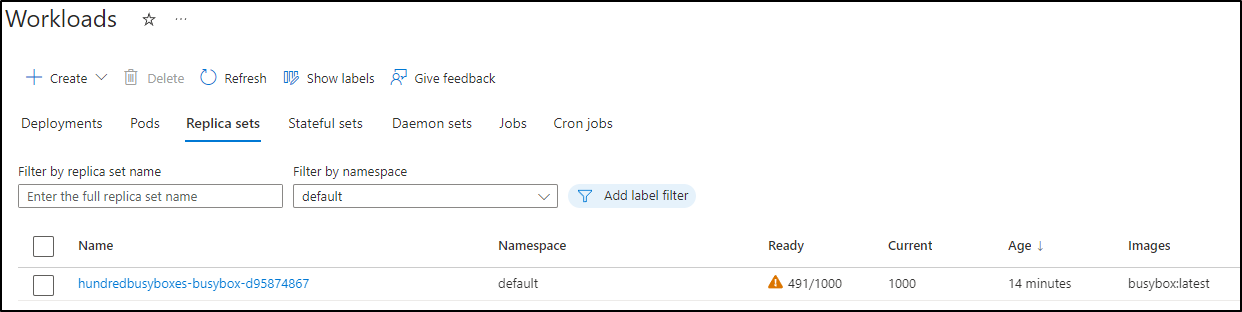
$ kubectl get pods -o json | jq -r '.items[] | .status.phase' | sort -u
Pending
Running
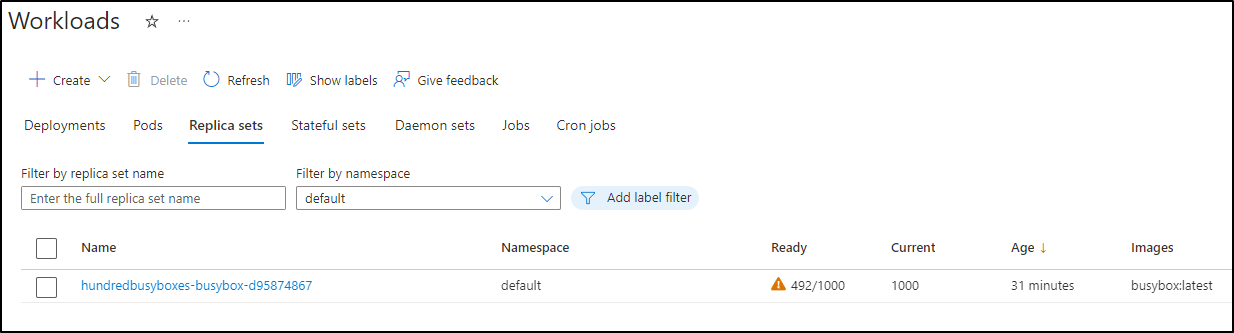
I gave this a full size hours to see if it would scale out to a Cast.ai provisioned node, however, 6 hours in and we have less than half our scheduled pods:
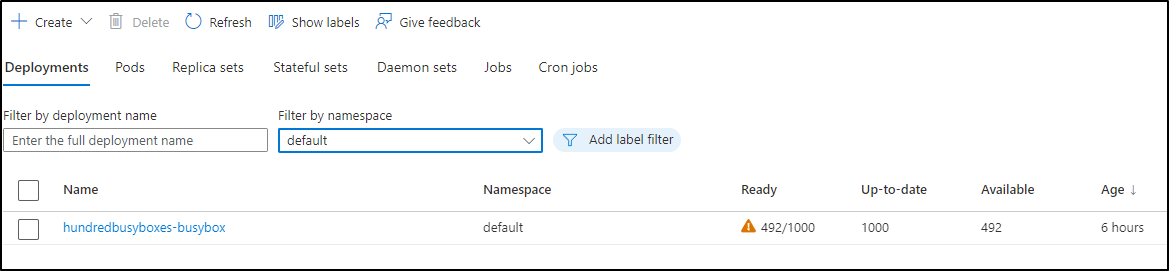
Yet none marked as failed
$ kubectl get pods -o json | jq -r '.items[] | .status.phase' | sort -u
Pending
Running
And no Cast based worker nodes scheduled
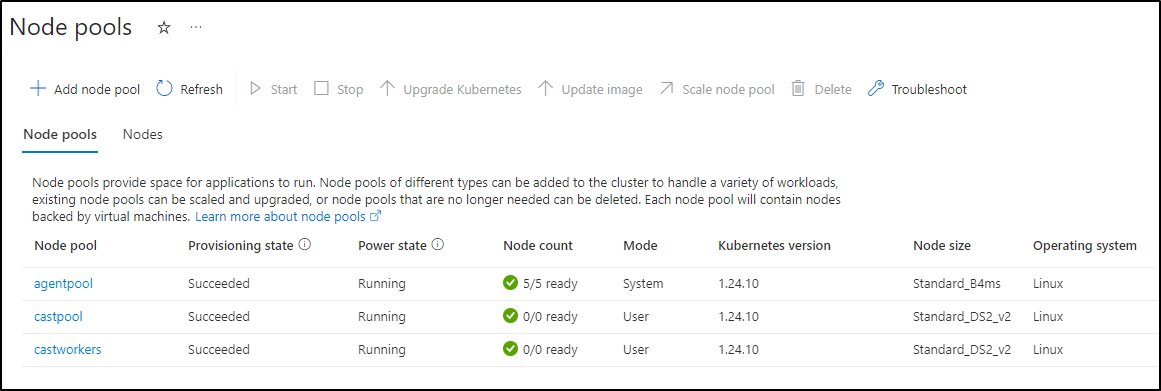
I even got an automated alert on pegged CPU, yet no new workers
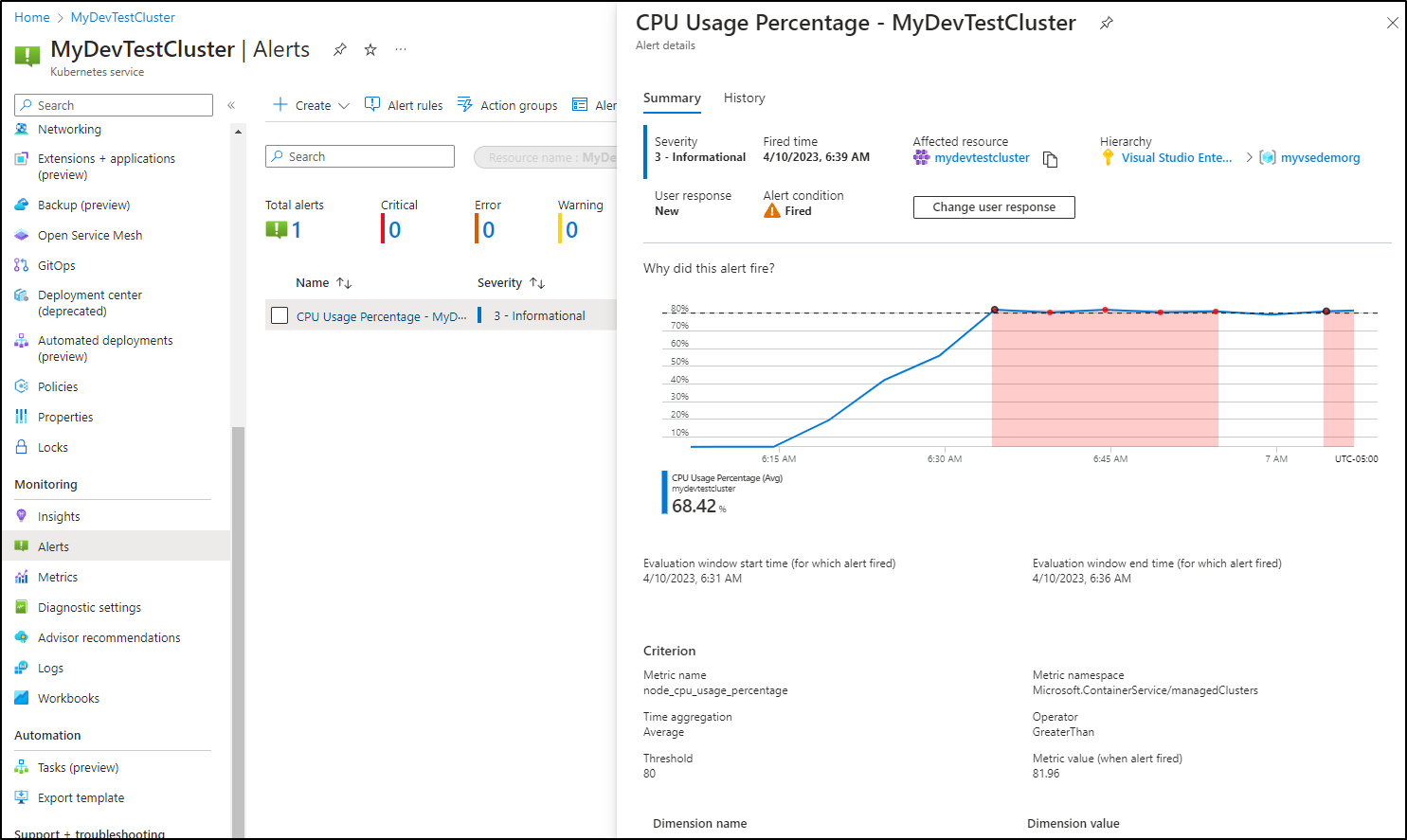
I can also see a growing spike in costs
GKE
Let’s try Google as well.
I’ll create a new cluster
Let’s try Autopilot first. I think this might confuse Cast.ai, but it’s worth seeing the results
I’ll give it a name and region
and accept defaults for the rest, then click “Create Cluster” to create
Once created, I can “connect”
which reminds me the handy one-liner to get the kubeconfig
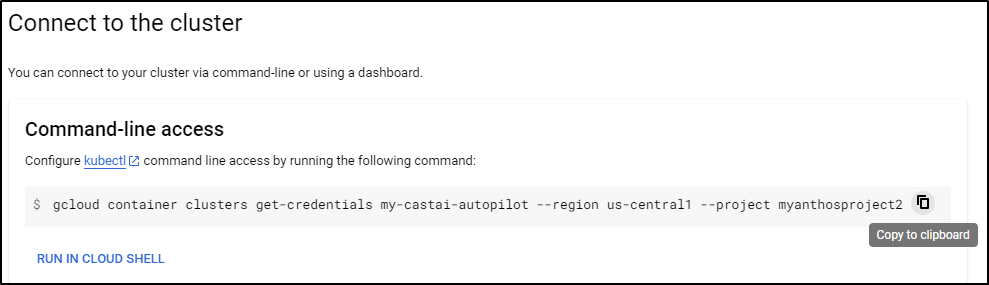
$ gcloud container clusters get-credentials my-castai-autopilot --region us-central1 --project myanthosproject2
Fetching cluster endpoint and auth data.
kubeconfig entry generated for my-castai-autopilot.
To take a quick anonymous survey, run:
$ gcloud survey
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gk3-my-castai-autopilot-default-pool-55392129-29f2 Ready <none> 8m41s v1.24.10-gke.2300
gk3-my-castai-autopilot-default-pool-957044a2-lgk3 Ready <none> 8m40s v1.24.10-gke.2300
Back in Cast, I’ll get the GKE command to run
$ curl -H "Authorization: Token d1asdfasdfasdfasdfasdfasdfasdfasdfasdfasdfasdf26" "https://api.cast.ai/v1/agent.yaml?provider=gke" | kubectl apply -f -
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 11276 0 11276 0 0 18762 0 --:--:-- --:--:-- --:--:-- 18730
namespace/castai-agent created
resourcequota/castai-agent-critical-pods created
serviceaccount/castai-agent created
secret/castai-agent created
configmap/castai-agent-autoscaler created
clusterrole.rbac.authorization.k8s.io/castai-agent created
clusterrolebinding.rbac.authorization.k8s.io/castai-agent created
role.rbac.authorization.k8s.io/castai-agent created
rolebinding.rbac.authorization.k8s.io/castai-agent created
Warning: Autopilot set default resource requests for Deployment castai-agent/castai-agent-cpvpa, as resource requests were not specified. See http://g.co/gke/autopilot-defaults
deployment.apps/castai-agent-cpvpa created
Warning: Autopilot increased resource requests for Deployment castai-agent/castai-agent to meet requirements. See http://g.co/gke/autopilot-resources
deployment.apps/castai-agent created
Which then notes it was added successfully
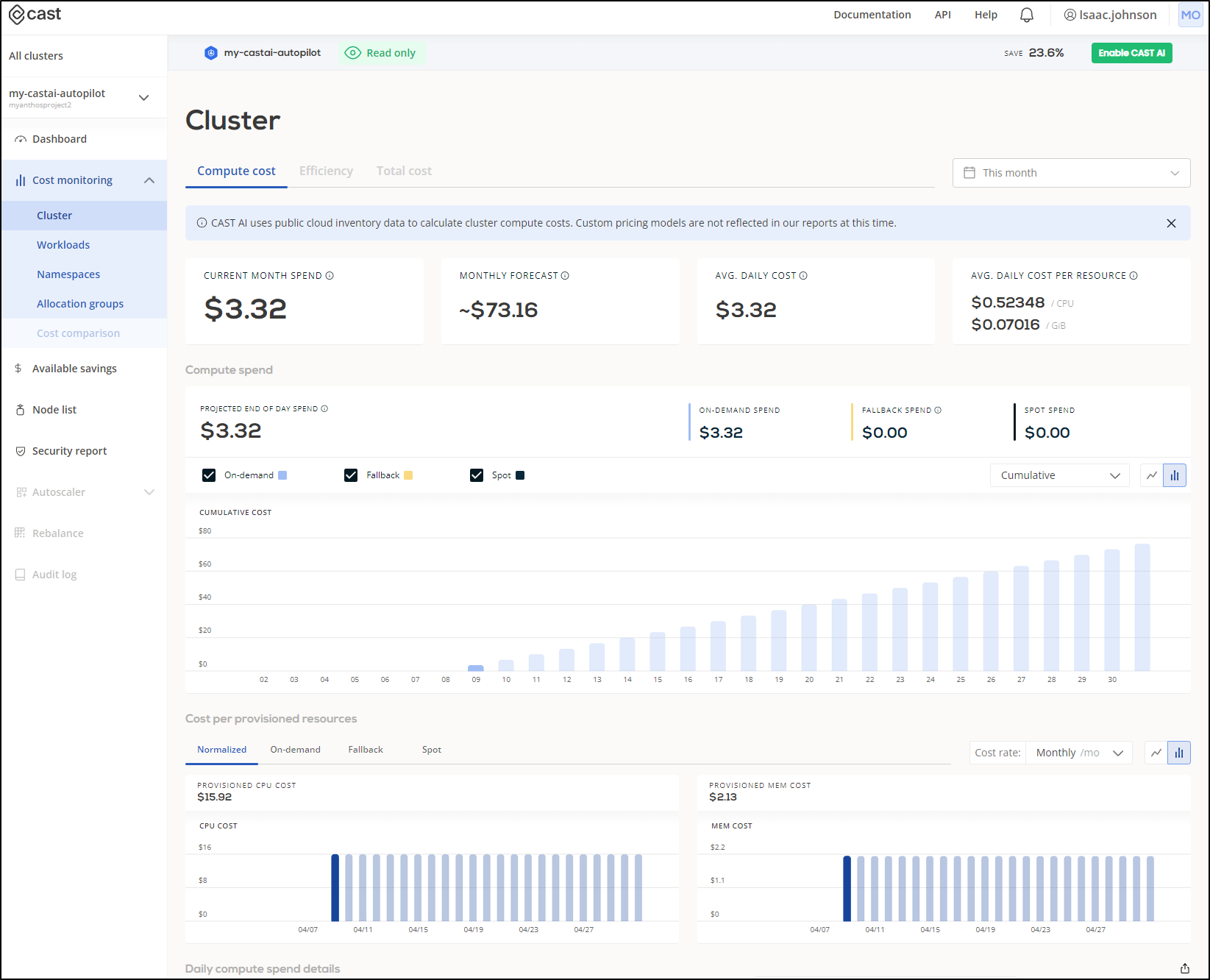
Quite immediately I see we are at US$3.65 for the cluster. I have to assume this is just an estimation for end of day (since it matches “Daily cost”)
The addition of Cast.ai caused the cluster to add a node immediately
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gk3-my-castai-autopilot-default-pool-55392129-29f2 Ready <none> 14m v1.24.10-gke.2300
gk3-my-castai-autopilot-default-pool-957044a2-79ww Ready <none> 3m6s v1.24.10-gke.2300
gk3-my-castai-autopilot-default-pool-957044a2-lgk3 Ready <none> 14m v1.24.10-gke.2300
I noticed I couldn’t get details in GCP Console. The alert let me know an API was absent
So i went and enabled it
Since Google won’t show me the instance type in any window I can find, I can pull it from the node details.
$ kubectl describe node | grep node.kubernetes.io/instance-type
node.kubernetes.io/instance-type=e2-medium
node.kubernetes.io/instance-type=e2-medium
node.kubernetes.io/instance-type=e2-medium
However, we can also get this data from teh “Node list” area of Cast.ai
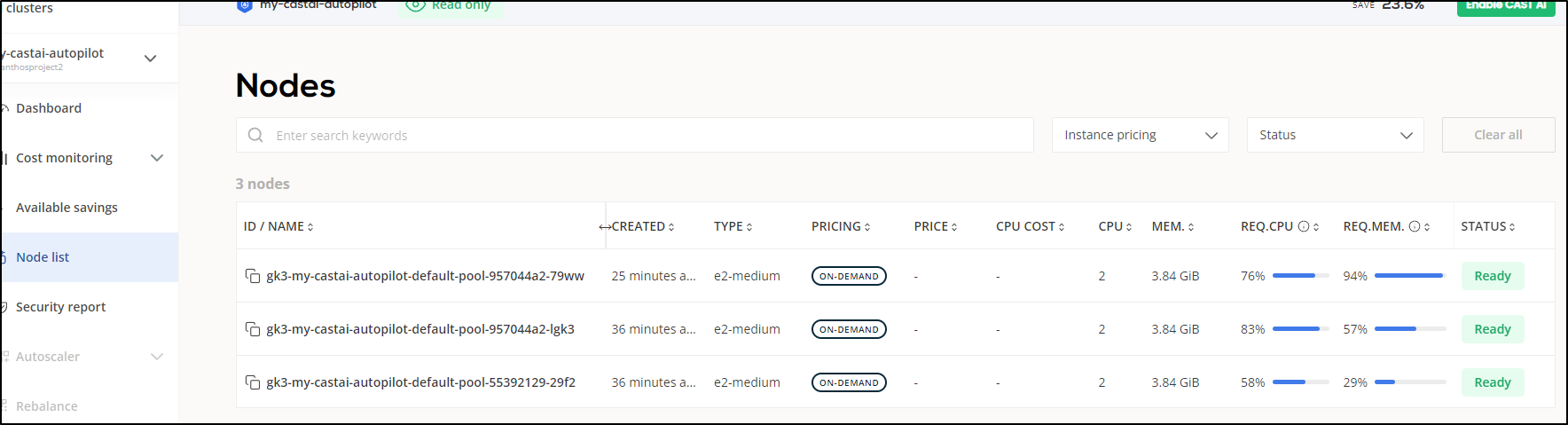
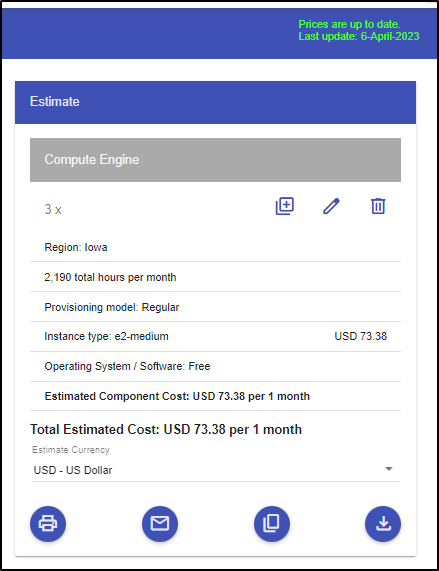
It’s a rough guess but for the region and class, we are looking at 73.38/mo or about US$2.36/day not counting storage or control plane, for a 3 node cluster of e2-mediums.
There does not appear to be a Cast.ai autoscaler for GKE yet based on the UI
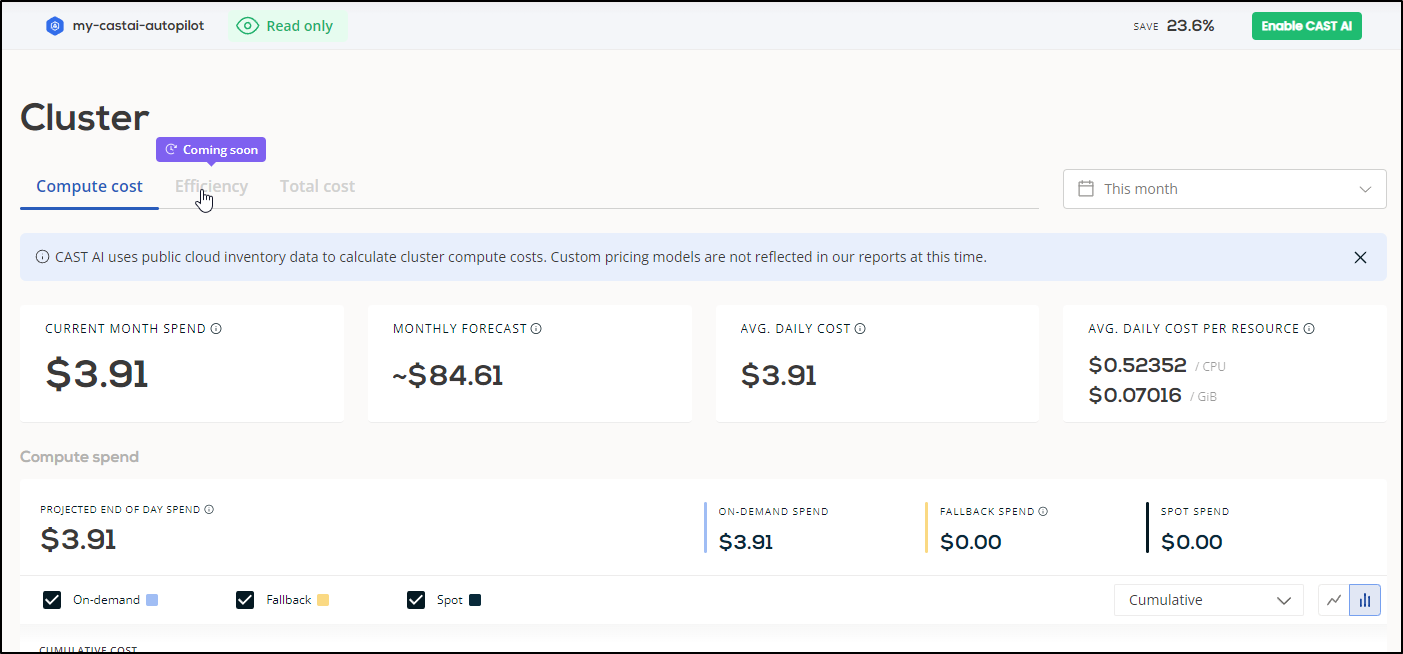
When I delete a cluster
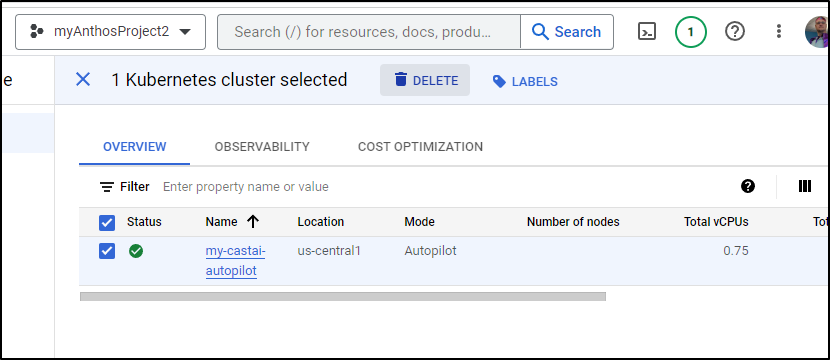
It soon shows as disconnected. I can then leave it, reconnect or delete the cluster from the list using the triple dot menu.

Terraform
One can add cast.ai through Terraform.
There are examples here.
For instance, for AKS
data "azurerm_subscription" "current" {}
provider "castai" {
api_token = var.castai_api_token
}
provider "helm" {
kubernetes {
host = azurerm_kubernetes_cluster.this.kube_config.0.host
client_certificate = base64decode(azurerm_kubernetes_cluster.this.kube_config.0.client_certificate)
client_key = base64decode(azurerm_kubernetes_cluster.this.kube_config.0.client_key)
cluster_ca_certificate = base64decode(azurerm_kubernetes_cluster.this.kube_config.0.cluster_ca_certificate)
}
}
# Configure AKS cluster connection to CAST AI using CAST AI aks-cluster module.
module "castai-aks-cluster" {
source = "castai/aks/castai"
aks_cluster_name = var.cluster_name
aks_cluster_region = var.cluster_region
node_resource_group = azurerm_kubernetes_cluster.this.node_resource_group
resource_group = azurerm_kubernetes_cluster.this.resource_group_name
delete_nodes_on_disconnect = var.delete_nodes_on_disconnect
subscription_id = data.azurerm_subscription.current.subscription_id
tenant_id = data.azurerm_subscription.current.tenant_id
default_node_configuration = module.castai-aks-cluster.castai_node_configurations["default"]
node_configurations = {
default = {
disk_cpu_ratio = 25
subnets = [azurerm_subnet.internal.id]
tags = var.tags
}
}
}
and GKE
module "gke" {
source = "terraform-google-modules/kubernetes-engine/google"
version = "24.1.0"
project_id = var.project_id
name = var.cluster_name
region = var.cluster_region
zones = var.cluster_zones
network = module.vpc.network_name
subnetwork = module.vpc.subnets_names[0]
ip_range_pods = local.ip_range_pods
ip_range_services = local.ip_range_services
http_load_balancing = false
network_policy = false
horizontal_pod_autoscaling = true
filestore_csi_driver = false
node_pools = [
{
name = "default-node-pool"
machine_type = "e2-medium"
min_count = 2
max_count = 10
local_ssd_count = 0
disk_size_gb = 100
disk_type = "pd-standard"
image_type = "COS_CONTAINERD"
auto_repair = true
auto_upgrade = true
preemptible = false
initial_node_count = 2
},
]
}
Company Profile
Cast.ai is based out of Miami, FL and has around 74 employees (or 50). It’s last financing deal was a 2023 Series B/Series A2 in March of this year for $20.14M with Cota Capital and Creandum. It’s privately held and VC backed. It was founded in Oct 2019 by Laurent Gil (Chief Product Officer), Leon Kuperman (CTO), Vilius Zukauskas (Director of Operations), and Yuri Frayman (CEO).
The four of them had sold Zenedge to Oracle in 2018 and went away thinking about how large their cloud bills were. They bill themselves as a “cloud optimization platform that reduces cloud costs, optimizes DevOps, and automates disaster recovery.” While it’s HQ is in Florida, the Director of Engineering, Augustinas Stirbis is in Lithuania. I checked their job board and saw listings for Europe, US and India, all Fully Remote.
So just a fun fact.. I checked ZenEdge in the wayback machine.. It clearly was updated through 2018
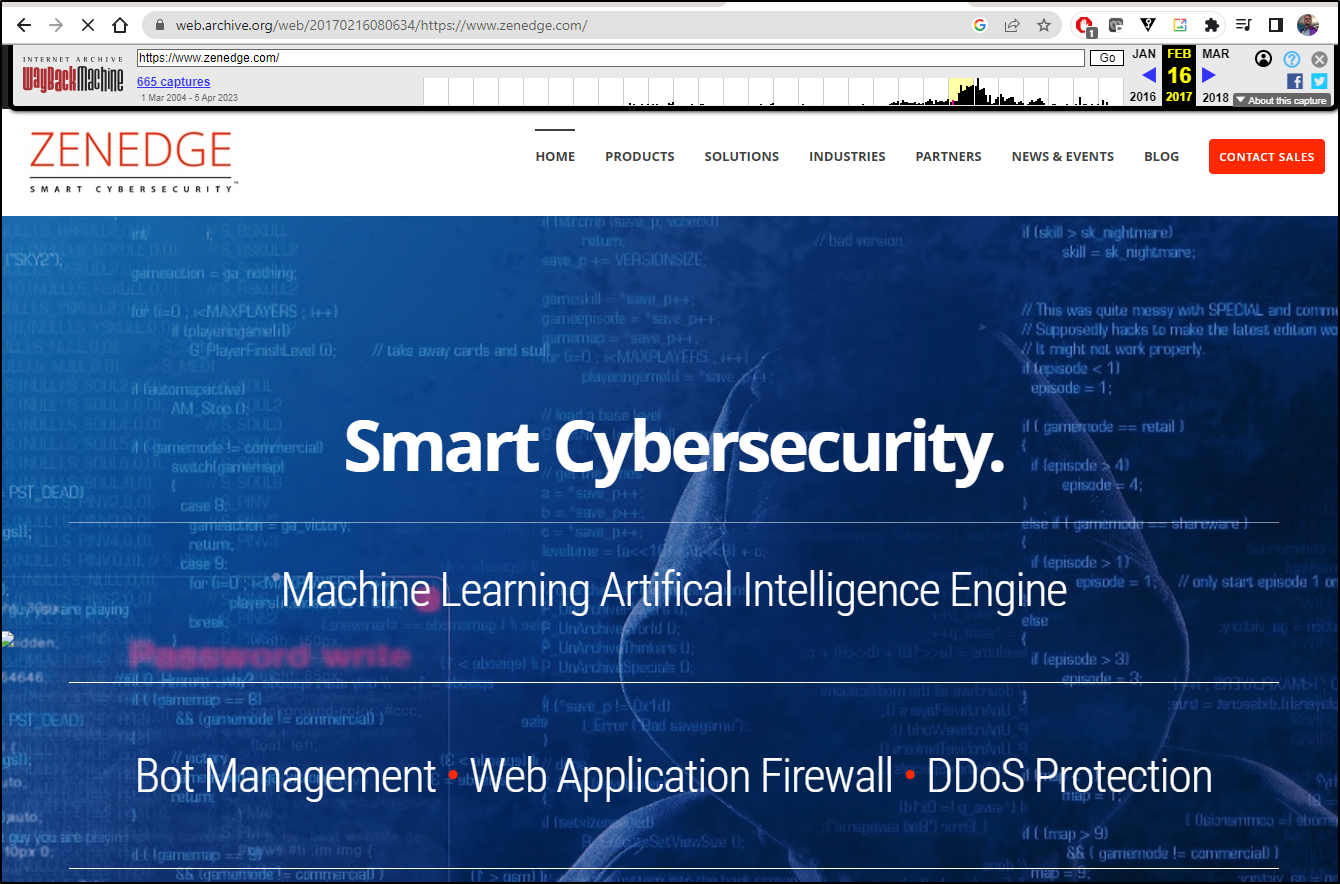
But Oracle evidentally didn’t renew the domain so now its some placeholder for an Indonesian Casino site

Costs
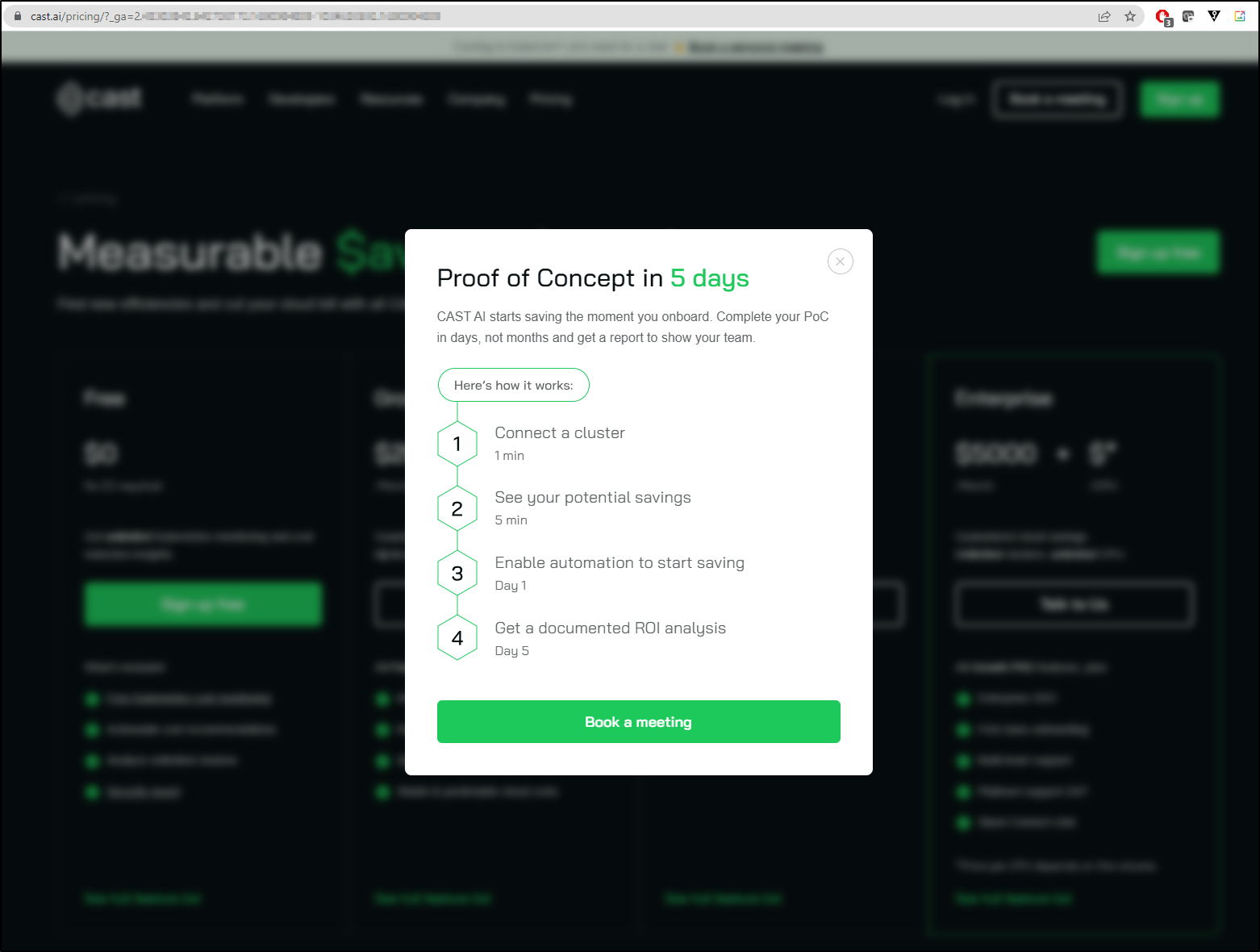
Cast.ai has a few plans. I really like all that is bundled thus far with the free plan.

However, that odd desperation kicked in… In the time it took to just write the first sentence in this description while looking at the pricing page, it popped up yet another pitch on POC… the page background blurring is all them. Guys - I’m on the pricing page, wouldn’t that mean I’m somewhat interested? Why blur it and put another pitch in my face?
Summary
Cast.ai makes a pretty solid suite that offers a lot of value for a relative low cost. I could easily see myself using it if they expanded to self managed clusters. That said, if one self-manages, I’m not sure how they could really use an autoscaler unless I opened a path to provisioning new hardware.
That said, I see a value play in just scanning my cluster for Security issues and suggested workload optimizations. Personally, I rather trust my cloud provider the most to properly scale - I do not really want to add a dependency on a third-party that would need to upgrade alongside the cluster to work accurately.
One area I would love to see them improve upon is reporting and alerting. Their UI is fabulous, however, I shy away from systems that require me to constantly watch a dashboard. I would much prefer some form of alerting and escalation paths. Here, I’m thinking of things like AWS Budgets that ping me when my spend exceed some preset limits. An alert that someone deployed a high-vulnerability workload, or a node scale out exceeded norms; these kind of things could be very useful.
