

Published: Dec 31, 2020 by Isaac Johnson
Most recently in conversation with my colleague Jason, I brought up the power of VMSS backed agents. I covered them in my WhizLabs course, but haven’t discussed them, to date, here in the blog.
When it comes to Azure DevOps agents, there are several ways to specify an agent. We will dig into Provided (Microsoft-Hosted), containerized and lastly VMSS agents and compare their usages.
Microsoft Hosted Azure Agents
The first and most common is to use the Microsoft-hosted agent pools. You can see some of the list here.
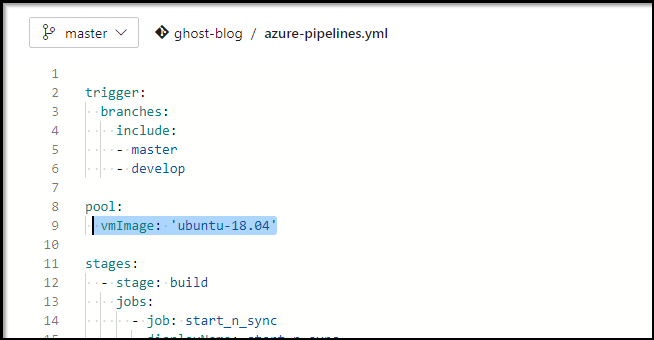
And in classicUI pipelines here:
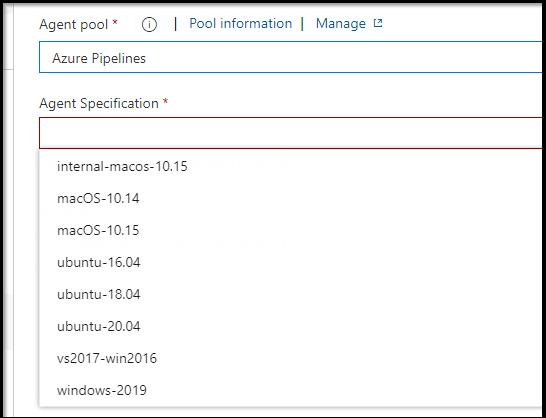
The “Azure Pipelines” pool gives you one for free and in all other cases you pay per parallel agent.
But as with all things “free”, free is not really free. You get (at present) 30h a month and buid stages cannot exceed 60m (which has bitten me a couple times here). When you pay for additional agents it costs $40/agent/mo but the 60m is changed to 6hours (max).
I should add that public projects get up to 10 free parallel jobs with 6 hour limits (more info here).
One thing to also consider is that Microsoft periodically retires a class (such as Ubuntu 16.04 which will disappear in April 2021 when it’s EOL’ed). In some cases there is an agent type that is fluid such as ‘ubuntu-latest’.
Self-hosted Agents
The second way you can do it is with a self hosted agent. You use a Personal Access Token (PAT) that will eventually expire to register an agent on the machine of your choosing. All it needs to do is reach back to Azure (often on 443 on *.dev.azure.com).
These operate as a dumb slave does in Jenkins and so the agent needs to reach up to Azure DevOps (but not vice versa; your agent must be able to see Azure Devops but Azure DevOps needs no ingress into your network). These are great for agents needed on-prem or behind a firewall. These also handle uniquely configured machines either built with tools like sysprep, packer, or chef just to name a few.
With the free tier you get one agent (in parallel) to use and each additional is $15 a month (the reason for a charge is to cover bandwidth and usage).
I should also note that there are some basic requirements on the servers themselves. If linux, they must be able to run .NET Core 2.1 which can limit usage on some lower-end 32bit machines. You can see more specifics here.
Containerized Agents
A related option is running agents in a container. There used to be a vsts agent microsoft provided (vsts-agent-docker) but they deprecatedit and now recommend building your own.
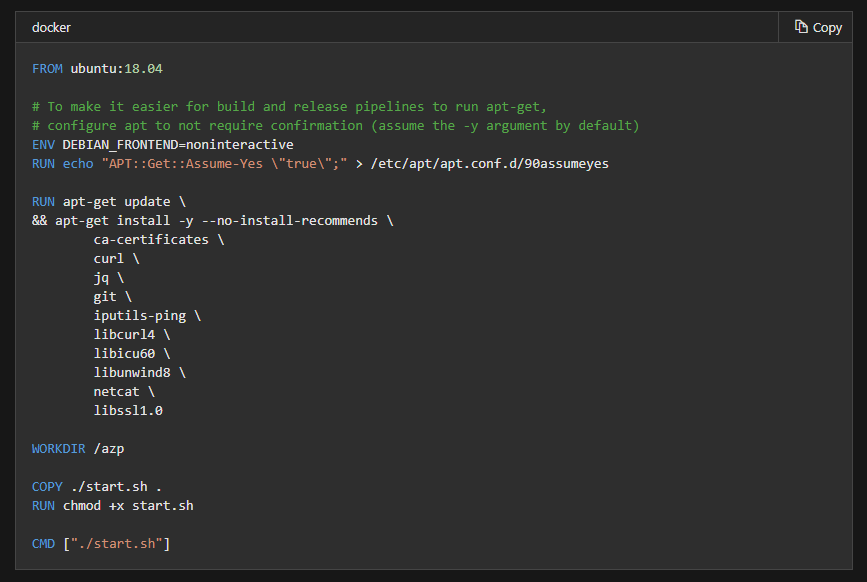
If you wish to use kubernetes as I often do, you can use a simple deployment yaml:
apiVersion: v1
kind: Secret
metadata:
name: azdo-newsecrets
namespace: #{ENV-AKS-NAMESPACE}#
type: Opaque
data:
ENV_AZDO_TOKEN: #{ENV-AZDO-TOKEN}#
---
apiVersion: v1
kind: ConfigMap
metadata:
name: azdo-newconfigs
namespace: #{ENV-AKS-NAMESPACE}#
data:
VSTS_POOL: #{VSTS_POOL}#
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: azdo-newagent-deployment
namespace: #{ENV-AKS-NAMESPACE}#
labels:
app: azdo-newagent
spec:
replicas: 1
selector:
matchLabels:
app: azdo-newagent
template:
metadata:
labels:
app: azdo-newagent
spec:
containers:
- name: azdo-agent
image: us.icr.io/freshbrewedcr/my-vsts-agent:latest
env:
- name: AZP_URL
value: 'https://dev.azure.com/princessking/'
- name: AZP_TOKEN
valueFrom:
secretKeyRef:
key: ENV_AZDO_TOKEN
name: azdo-newsecrets
- name: AZP_AGENT_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: AZP_POOL
valueFrom:
configMapKeyRef:
key: VSTS_POOL
name: azdo-newconfigs
- name: AZP_WORK
value: /var/vsts/$(AZP_AGENT_NAME)-agent
You can use sed or similar to replace the tokens. I tend to use a simple plugin for this:
- task: qetza.replacetokens.replacetokens-task.replacetokens@3
displayName: 'Replace tokens in **/*.yaml'
inputs:
rootDirectory: '$(System.DefaultWorkingDirectory)'
targetFiles: '**/deployment.yaml'
writeBOM: false
escapeType: none
In fact, my entire yaml pipeline looks a bit like this:
trigger:
- develop
- main
pool:
vmImage: 'ubuntu-latest'
variables:
- group: azdodev
stages:
- stage: build
jobs:
- job: build_container
displayName: build_container
continueOnError: false
steps:
- bash: |
#!/bin/bash -x
export
displayName: 'DEBUG - show values'
- task: Docker@2
inputs:
containerRegistry: 'IBMCR'
repository: 'freshbrewedcr/my-vsts-agent'
command: 'buildAndPush'
Dockerfile: '**/Dockerfile'
tags: |
$(Build.BuildId)
latest
- task: PublishBuildArtifacts@1
displayName: 'Publish Artifact: drop'
inputs:
PathtoPublish: deployment.yaml
- stage: release_infra
dependsOn: build
condition: and(succeeded(), eq(variables['Build.SourceBranch'], 'refs/heads/main'))
jobs:
- template: agent-release.yaml
parameters:
aksns: standuptime
vstspoolname: Kubernetes-Agent-Pool
- stage: release_test_infra
dependsOn: build
condition: and(succeeded(), startsWith(variables['Build.SourceBranch'], 'refs/heads/feature/'))
jobs:
- template: agent-release.yaml
parameters:
aksns: standuptime
vstspoolname: Kubernetes-Infrastructure-Testing-Pool
Agent-release.yaml:
jobs:
- job:
pool:
vmImage: 'ubuntu-latest'
steps:
- task: DownloadBuildArtifacts@0
inputs:
buildType: "current"
downloadType: 'single'
artifactName: 'drop'
downloadPath: '$(System.DefaultWorkingDirectory)'
- script: echo '##vso[task.setvariable variable=VSTS_POOL]$'
displayName: Set VSTS_POOL var
- script: echo '##vso[task.setvariable variable=ENV-AKS-NAMESPACE]$'
displayName: Set ENV-AKS-NAMESPACE var
- task: qetza.replacetokens.replacetokens-task.replacetokens@3
displayName: 'Replace tokens in **/*.yaml'
inputs:
rootDirectory: '$(System.DefaultWorkingDirectory)'
targetFiles: '**/deployment.yaml'
writeBOM: false
escapeType: none
- bash: |
#!/bin/bash -x
# show configmaps
find . -type f -name \*.yaml -exec cat {} \; -print
displayName: 'DEBUG - show values'
- task: KubernetesManifest@0
inputs:
action: 'deploy'
kubernetesServiceConnection: 'Homek8s-standuptime-1609428203486'
namespace: 'standuptime'
manifests: '**/deployment.yaml'
imagePullSecrets: 'ibm-docker-registry'
I had to set up a SA and “Environment” to use this:
apiVersion: v1
kind: Namespace
metadata:
labels:
name: standuptime
role: developer
name: standuptime
spec:
finalizers:
- kubernetes
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: azdo-standuptime-sa
namespace: standuptime
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: admin-azdo-standuptime-access
namespace: standuptime
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: admin
subjects:
- kind: ServiceAccount
name: azdo-standuptime-sa
namespace: standuptime
If you haven’t actually created the agent pool or your Token isnt correct (like you forget to base64 it like i initially did), you’ll get an error in the logs
standuptime azdo-newagent-deployment-5b6b489cb6-zj6lt 0/1 CrashLoopBackOff 4 3m3s
builder@DESKTOP-JBA79RT:~/Workspaces/StandupTime$ kubectl logs azdo-newagent-deployment-5b6b489cb6-zj6lt -n standuptime
1. Determining matching Azure Pipelines agent...
error: could not determine a matching Azure Pipelines agent - check that account 'https://dev.azure.com/princessking/' is correct and the token is valid for that account

The deployment yaml above assumes a CR secret was applied to pull from IBM CR (However, I could just make the image public or use dockerhub):
$ kubectl create secret docker-registry ibm-docker-registry --docker-server=us.icr.io --docker-username=iamapikey --docker-password=c ********************************************* C --docker-email=isaac.johnson@gmail.com -n standuptime
secret/ibm-docker-registry created
That above is a token for pulling not pushing. IBMCR is a service connection I added above to my IBM Cloud Registry. You can learn more about that onthis blog post.’
And we assume we have a proper PAT base64 encoded in the library (either via AKV or as an AzDO secret) that will be applied into kubernetes:
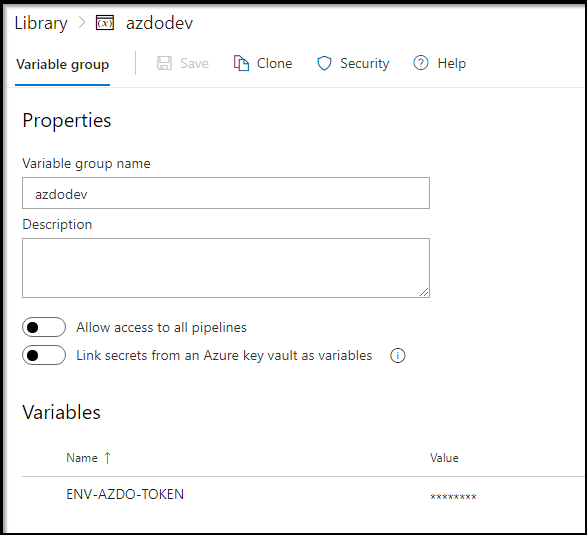
When all is said and done, we essentially have built a small on-prem containerized agent who uses a container hosted in IBM-Cloud Registry:
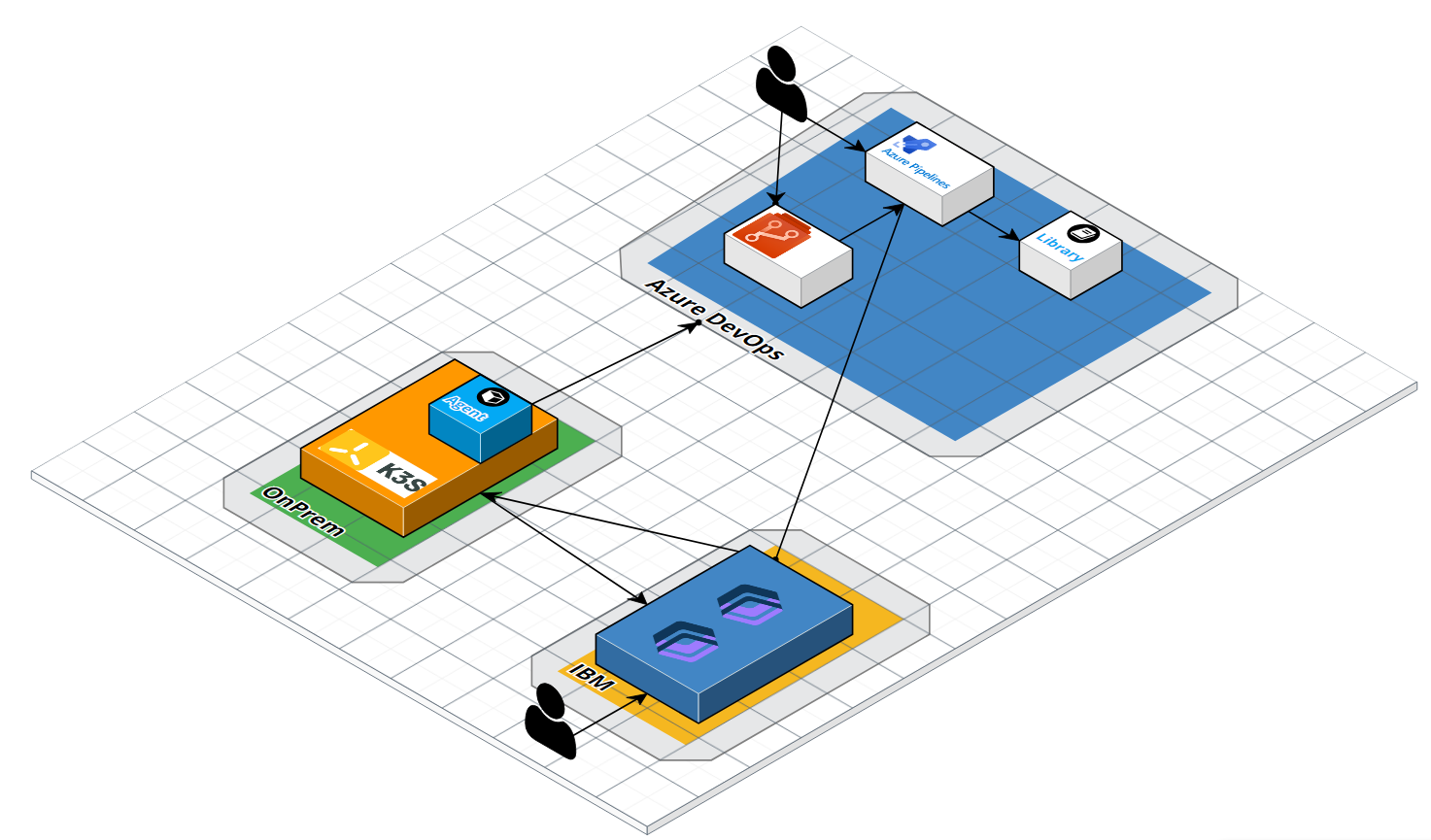
VMSS Agents
There is one more type of agent pool that can handle really interesting problems. This is the Virtual Machine Scale Set type agent pool.
A VMSS, similar to an AWS ASG, is an Azure object that describes both a type (class, OS, etc) and a minimum and maximum number of instances. We often tie this to a scaling policy (ASG) or an autoscale policy with scaling conditions (VMSS).
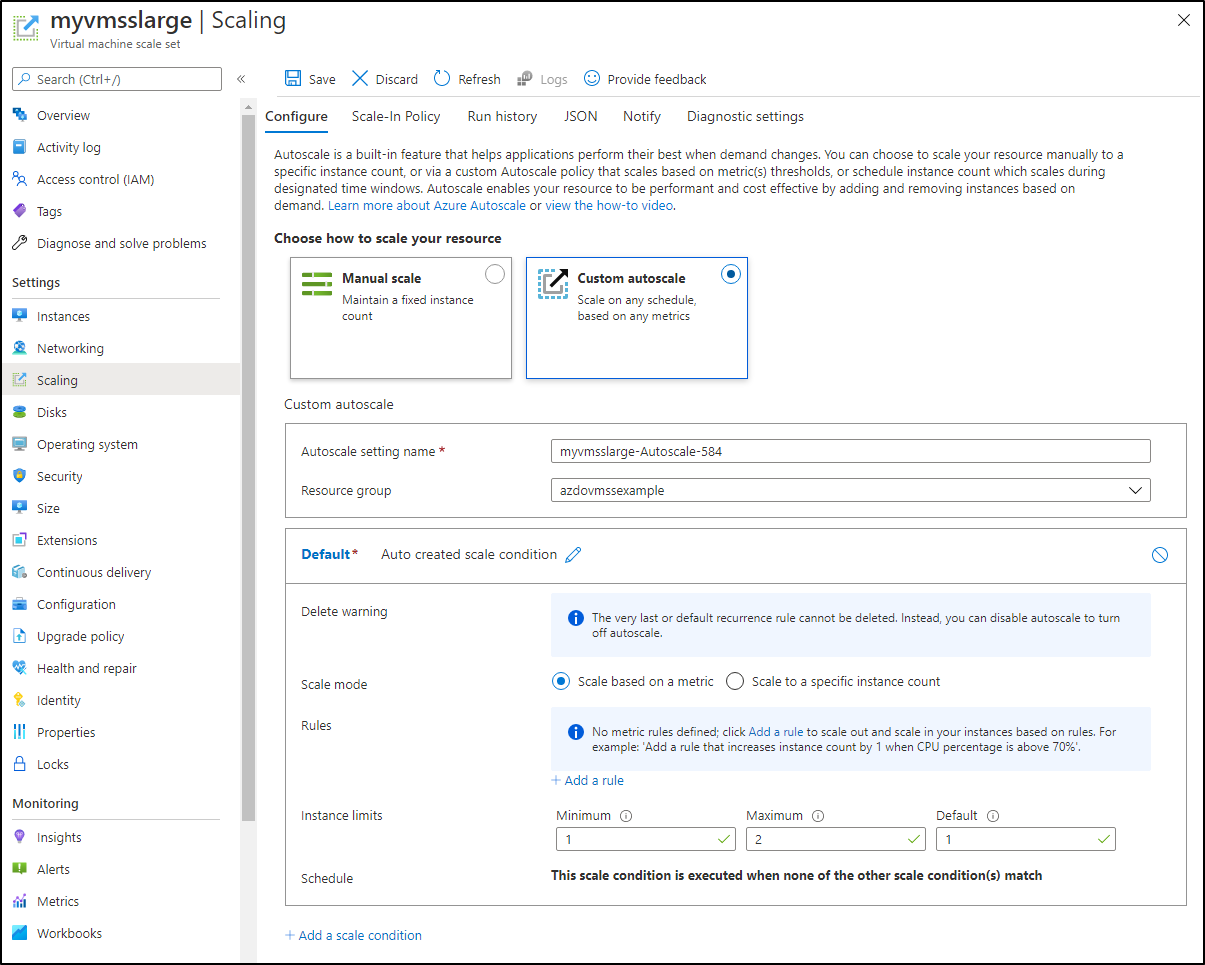
However, you can create a VMSS with an initial count of “0” - meaning it is entirely possible to create a Virtual Machine Scale Set that defines a machine group without instantiating it.
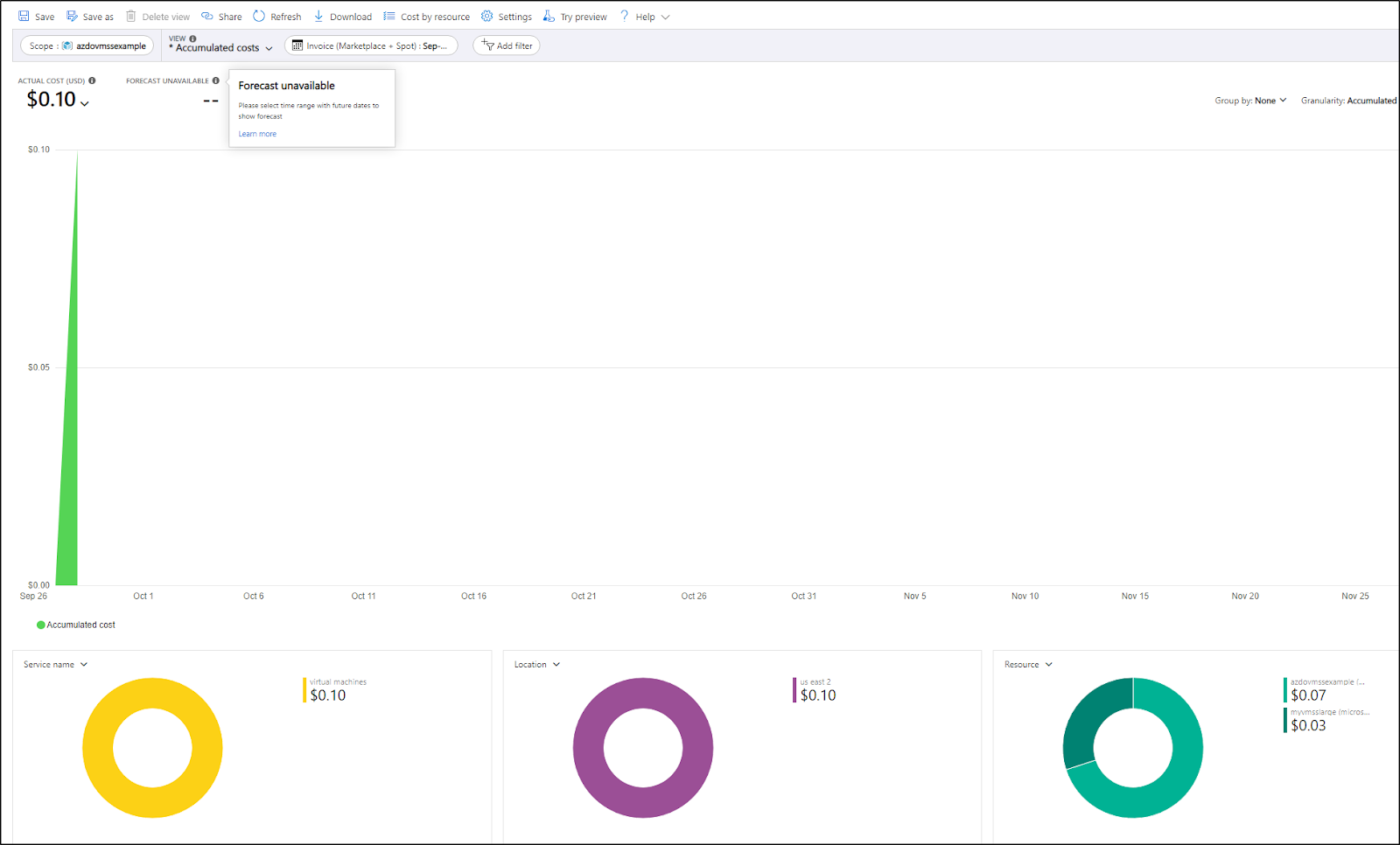
So in my case I’ve defined a large VMSS pool of Standard_D8s_v3 and we can see that it has not been leveraged in the last 30 days.
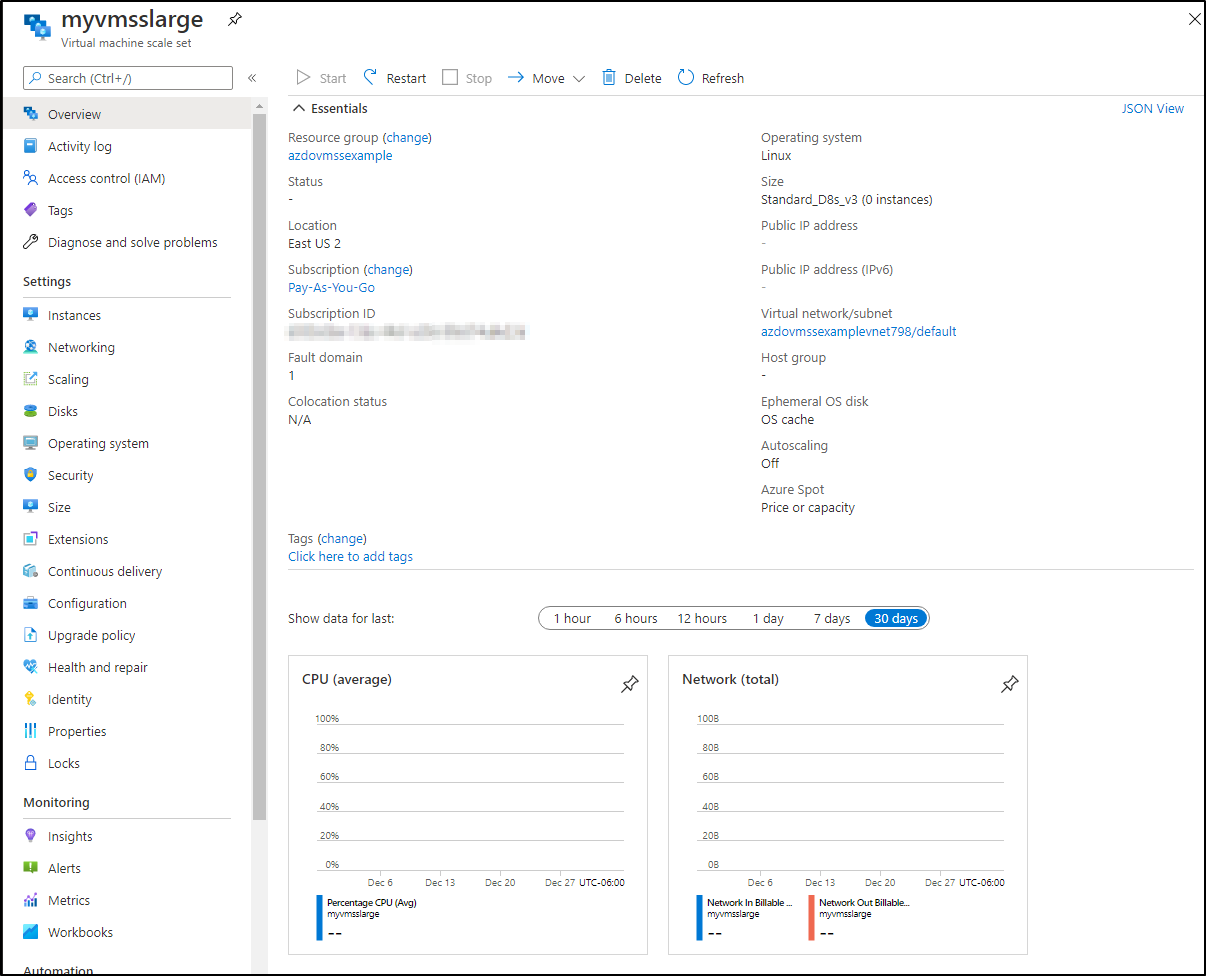
This means for the 50m or so it ran, it cost me a mere 10cents for the last quarter
We can create a VMSS agent pool with the key settings being “0” on standby and a short delay of idle time.
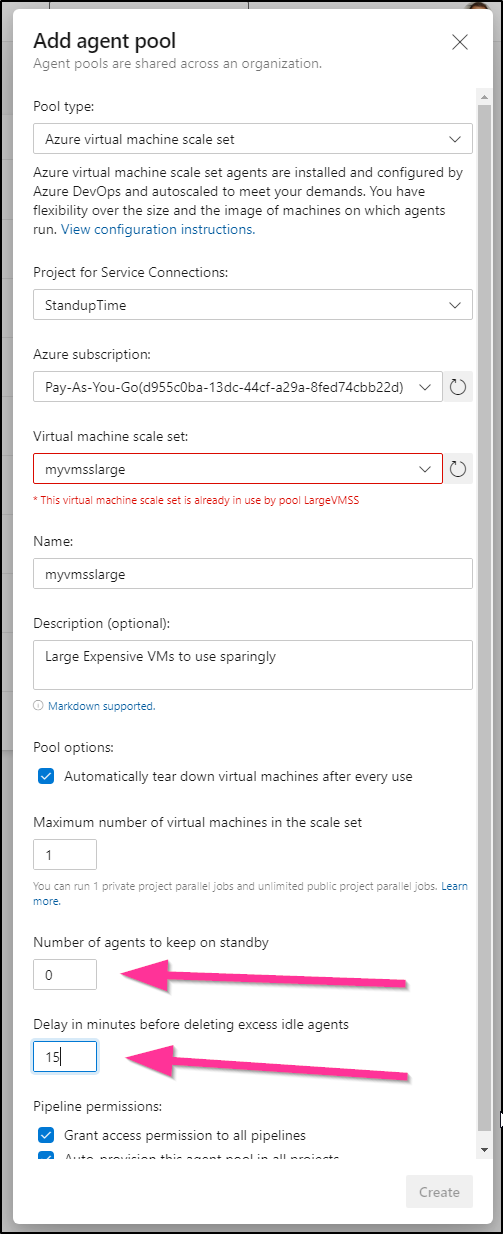
And we can see that in use here:
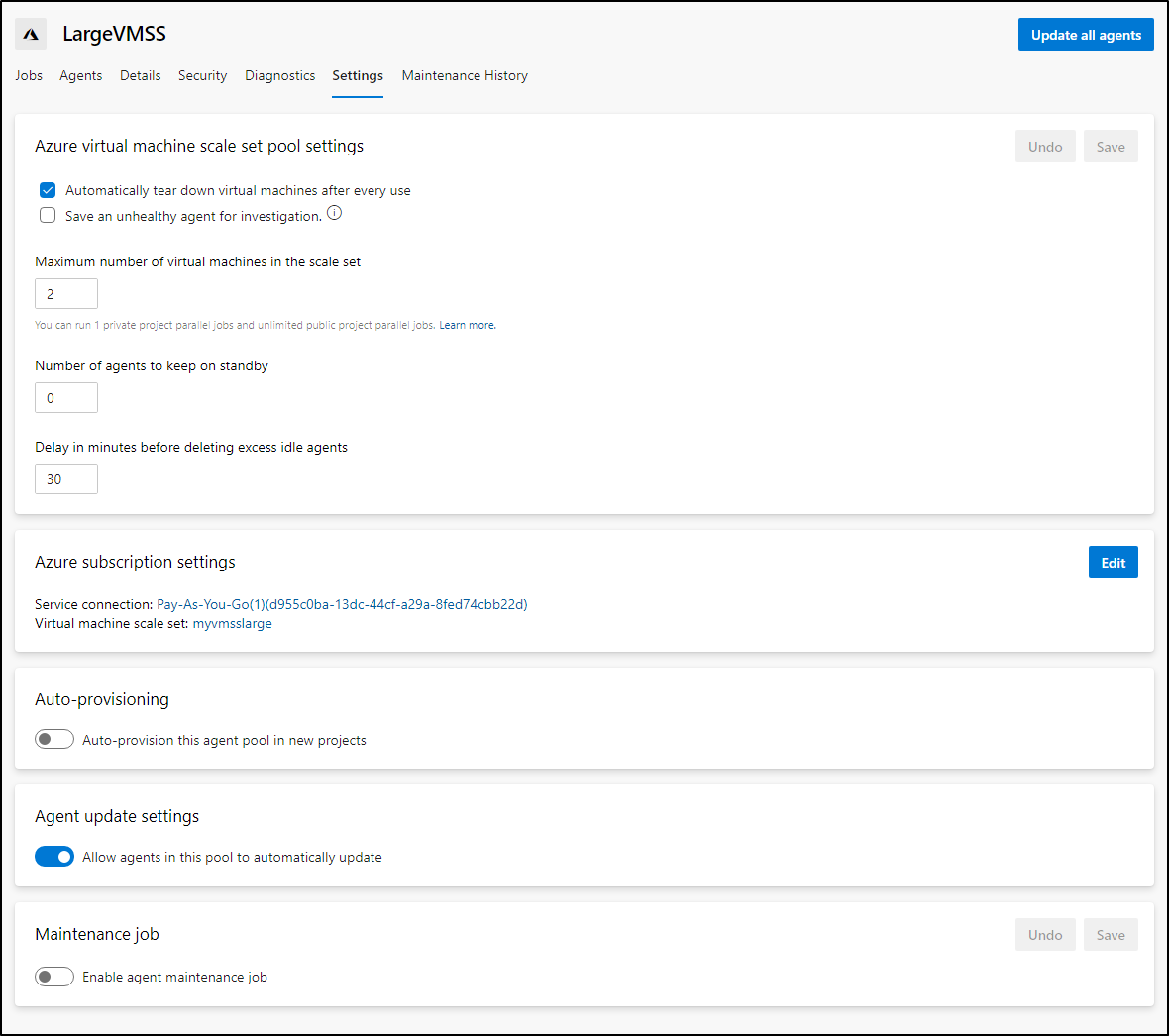
So what does this mean?
I can tie an infrequent job to a machine much larger than I would like to pay for on standby. And when i queue a build it will create, use and destroy this agent when done.
Additionally, you will notice there was no mention of Personal Access Tokens (PAT). This is a rare example of Azure DevOps using it’s own service principal to shoe-horn in a latest agent on the fly. This means we do not have to worry about expiring or user-tied credentials for this agent pool type.
This agent was used once in September
This means for the last quarter, it has only cost me 10 cents for the 50m or so of running time (30m idle and 19m build job).
Think about this for a minute. We could just as easily create a custom Virtual Machine Image (VMI) to use (seethis guide) orbuild one with Packer for a specific older product, or a slew of commercial purchased scanning tools. We would have to weigh the cost of storing a machine image versus using a (free) standard linux image and loading it via the pipeline with content.
For instance, loading several large binaries (say the full VS IDE, .net frameworks, scanning suites) would involve 30m of transfer on top of the build that would negate our VMSS speed savings (and we pay for compute time).
Using a VMI that had about 20gb of data in a HOT tier storage account would run (presently) 42c and with transfer costs, IOPS, etc would likely be around $1.50 a month for the pre-loaded image. However, if we only run this build once a year or perhaps never (it’s a DR backup), then that’s wasted money.
Applications
Consider AI modeling which can require massive parallel operations on the largest machine one can acquire. Purchasing a Cray (RIP) could set the company back a fair amount and require a team to manage it. However, One could run a job on an M416ms v2 which has 416 cores, 12Tb of RAM and 8TB of temp fast storage and do this each week for an hour, for just $516 a month (as of this writing).
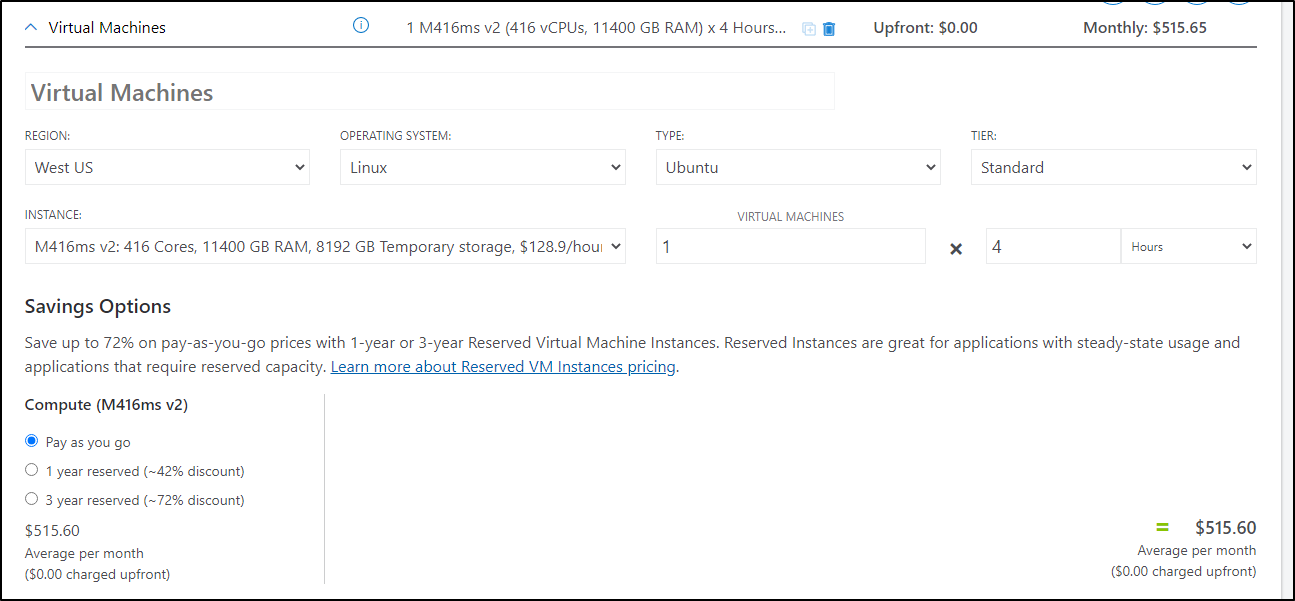
Consider the implications of being able to spend a mere $128/hr to get meaningful data to your data scientists and researchers without a massive capex cost - and do it without vendor lock-in in Azure using Cognitive Services or Azure ML or AWS ML Solutions including SageMaker.
Disaster Recovery for “that one machine”
We all have been there. We have a great build and release process, except for… that one machine or build. That for some perplexing reason, builds of a given product have to come from an older server that was set up long ago by folks long since gone and everyone just hopes and prays that it doesn’t take a drive. I’ve been there and I’m sure many of you have as well. (I can recall fondly of a slew of build servers that had dell laptop drivers as we could only P2V the originating host…).
Following these guides (there are ones for Hyper-V, VMWare, AWS and GCP as well), we could migrate a physical box into Azure as a running VM then turn around and turn that into a VMI that could be used behind a VMSS and thus an agent pool.
Cost savings
Often companies will want to use Kubernetes to solve many needs (okay, i’ll stop projecting - often I want to use K8s to solve all my needs). While hosting a Kubernetes cluster just to hold agent pools sounds nice (we can use an Horizontal Pod Autoscaler to scale out agents, of course) it means we are paying for an always running agent pool. Most of my AKS clusters run between $80 and $800 a month depending on size. If I have projects that go dormant or have smaller windows of active development, using a VMSS can actually save time and money.
An example : what if you have a project that today, during busy periods needs to have 4 active builds running at a time? So you pay $40/agent but because they are slow, the developers are demanding more parallel agents - namely 6. So considering 6x40 ($240) a month, you can counter propose that instead they keep the 1 standard parallel ms agent but move the deep regression and integration tests to a nightly job that could tag develop. After all, the regression tests rarely fail, but it’s important that they run fairly often.
So instead you create a VMSS pool with a large instance (Standard D8s v3) and it runs nightly (10c/hour). You reduce to just 1 extra parallel agent ($40/mo) leaving you with a private pool costing (5dx4w) 20x10c or around $2/mo compute plus $40 ($42) instead of $240. For one project, this might not earn a waytogo from your boss, but if you scale this out over an organization, the savings can add up.
Summary
We covered four main types of Azure Agents; the provided (Azure/Microsoft Hosted), the self-hosted, the containerized (including running via K8s) and lastly the VMSS style agents.
We pointed out some of the cost savings to each. The Microsoft agents have the least barrier to entry. Like VMSS we need not worry about expiring agent tokens. However, these both assume we are comfortable (or authorized) to use Azure for our build compute.
Self-hosted let us use existing infrastructure, including that on-prem for a small $15/agent charge. There are some limitations on machine types (such as older 32bit).
Containerized Agents offer us a way to use compute anywhere we can run containers to act as our private agent pool. We leveraged k3s running on retired macbooks in my basement and a registry in IBM cloud to prove this out.
Virtual Machine Scale Set (VMSS) agents allow us to create a scalable pool of customized build agents. This can help with the fixed 6h job limit in YAML jobs or optimized for large sized agent needs such as AI or regression testing. This also allows us to save money for infrequently running pipelines.
