

Published: May 4, 2020 by Isaac Johnson
In the world of Operations, there is a tenant of supportability called Operationalization. This is a method of measurement used when a tool or system moves from Proof of Concept (POC), past Early Adoption/Pilot onto “Supported”. To dig into Day 2 considerations, we first need to lay the groundwork by discussing ROI considerations and the Solution Lifecycle.
Return on Investment (ROI) Considerations:
When considering software (or hardware) solutions, fundamentally there are three things we must consider that form the basis for ROI:
- Cost : What is the Total Cost of Ownership (TCO). We will dig into this, but cost goes beyond sticker price.
- Benefit: How does this solution improve business processes. Whom does it affect (both positively and negatively).
- Lifespan : All solutions have a lifespan - what does this one look like and how can we maintain data portability and avoid vendor lockin.
Cost
First let’s tackle cost. This is where developers can easily get caught in the concept of “free is best”. While there is a lot of fantastic Open Source software out there, and general purpose hardware, there is a cost associated to rolling it out and maintaining it.
_ An Example: Frank is a fantastic developer and loves working on Acme’s latest line of southwestern landbased bird elimination devices, however the source code repository, Source Safe, is long past it’s prime and only supports older Windows operating systems. Current laptops cannot use it and he would like to move the company to using the popular GIT based tooling._
Frank proposes the company adopt Open Source GIT and host it on a linux computer locally. His boss Chuck insists on a pilot and shortly therein has the following observations:
- GIT server requires Frank to create new linux accounts with SSH access
- The Server requires holes punched in the company’s firewall for remote development (Frank suggests using a cloud based computer, which would cost $20/month for their current scale)
- The current linux VM Frank used is on older hardware not backed up.
Chuck determines that the annual cost would be half of Frank’s salary (assuming it takes half of Frank’s time) and at least $40 a month in hosting costs (as Frank tends to underestimate). There is also the security risk of hand-maintaining the access (both for users’ attrition and general SSH security access).
Comparatively, Github.com would be $9/user/month and Azure DevOps would be $8/user/month and could tie to their AAD and/or SAML backends.
Benefit
The second characteristic we consider is Benefit - who benefits from this solution. There are the obvious direct impacts, but there are downstream effects with any solution we consider.
In the case of source code control, one could argue the developers, but the benefit goes further - The IT staff who have to find and manage deprecated software will benefit by having a reduced maintenance effort.
Using an option that is a SaaS takes hosting and networking out of the picture reducing load on the datacenter. The CSO knows a large company (like Microsoft in the case of Github and AzDO) will manage the security vulnerabilities and that benefit goes directly to lowering risk. Lastly, HR benefits - finding talent for the company willing to use Source Safe has proven difficult. Having current technology attracts talent.
An Example : Chuck, Frank’s boss suggests Github - it’s popular and well supported. But Frank bulks at a product now owned by Microsoft. Many of the developers have a negative view of MS and would prefer to stay clear of their properties, furthermore, Frank points out that the company currently has JIRA for Ticketting and Crowd for user management. Adding Atlassian bitbucket might tie in nicely with the rest of their tool suite. Chuck starts a conversation with sourcing to determine the pricing of various options of Bitbucket to see if it’s feasible.
Lifespan
The third component we need to discuss is lifespan. After a product is rolled out from a pilot into early adoption, it will likely grow legs and take off on its own. However, all tools eventually get old (such as our source safe) and need to be replaced. It’s key to understand what can be done for data portability.
In the case of GIT, the repository is self-contained with branches and history - but the policies that manage Pull Requests/Merge Requests vary by vendor. Chuck ensures proper process will be put in place (operationalization) to track the policies and ensure they can be reapplied.
Solution Lifecycles
Before we can tackle Operationalization, we also must review the solution lifecycle. There are many variants of this, but we argue the basics hold true: first a reason to change comes in - be it a fresh idea (do it different), a problem that is affecting the business or an opportunity (like a cost savings deal on premium equipment).
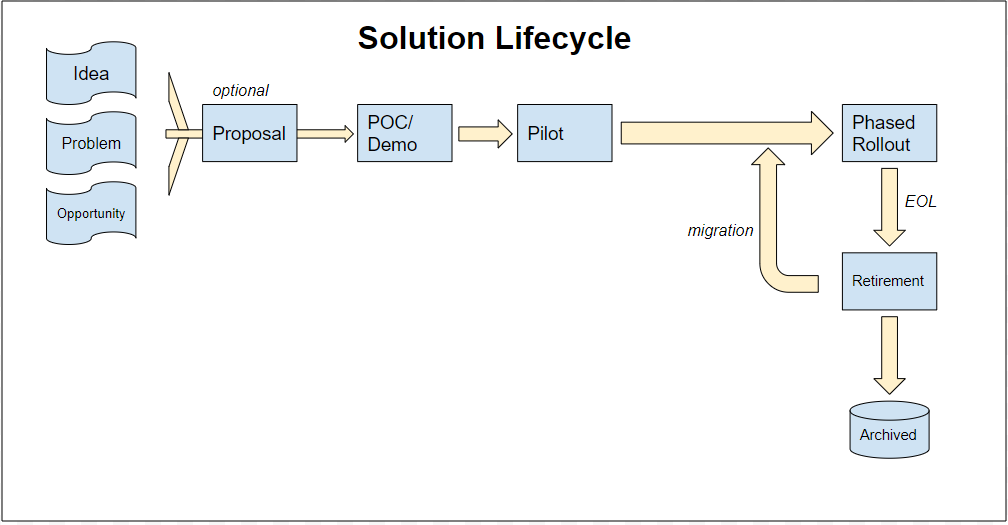
This then often translates into a proposal, but sometimes if it’s straightforward enough, it will be a proposal and a POC to demonstrate the usefulness at the same time. This Proof of Concept will get stakeholder buy-in enough to drive a pilot - a real working example.
Once the pilot has sign off by interested parties (and often paperwork is in place and a Purchase Order approved), we move into the Phased Rollout - where the solution is put in place while the prior system (if relevant) is retired. Lastly, when the solution is eventually deemed End of Life, we retire and archive any data. If relevant, we migrate old data (as would be the case in revision control systems).
Operationalization
The term Operationalizationis actually borrowed from social research. In social research, when there is a concept one wishes to test, such as Socioeconomic Status or Parenting Abilities, one uses Operationalization to measure it. Whether it’s measured in a nominal, ordinal, interval or ratio levels, the point is to measure in a consistent way.
Operationalization has another meaning as well. To operationalize something is to make it operational, functional, running. The process of doing so is operationalization. In our lifecycle above, we see operationalization come into play in the Day 2 side of operations:
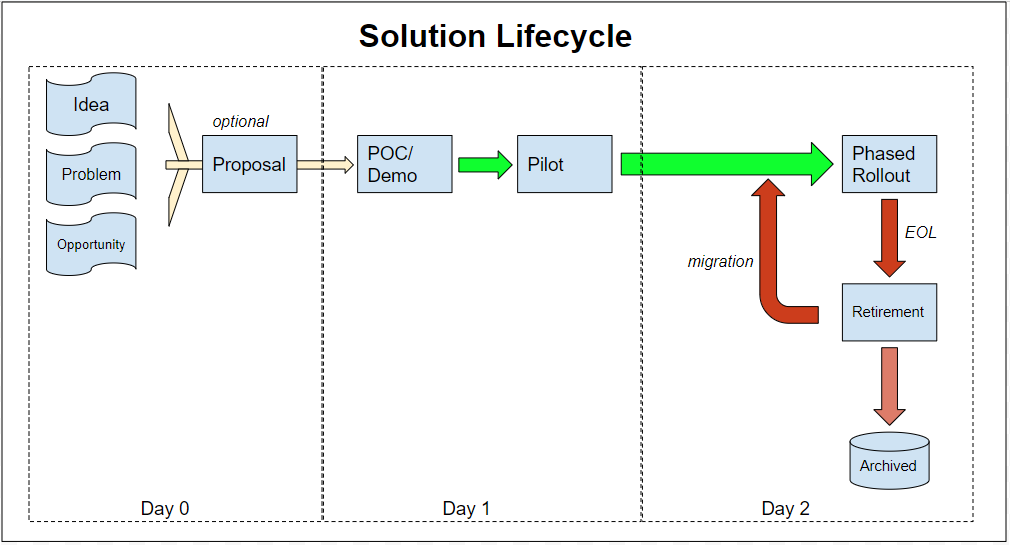
In Day 2 Operationalization we need to focus on:
- Who is doing the work - and how are they supported (usually over time - that is, often a cadre of consultants start a project, but frontline support and operations teams must maintain the systems after rollout).
- Security and Maintenance - who is monitoring security and applying patches? What is the process for upgrades and what does our support contract details out (do we have 24/7 live support or community BBS?)
- What is our Support Level Agreement (SLA)? What is our promised uptime, performance, response times - and who handles that, and how?
- Who pays for expansion and scaling out/up - often as in the case for software solutions, other departments can see ‘the shiney new’ and want in - who will pay for their seats, is there a charge back model, does the solutions scale (both in licensing and performance)
Who is doing the work:
Often the pilot is well staffed and the vendors (or engaged developers around Open Source solutions) drive the pilot, but it’s in the phased rollout things get interesting. Will the key developers who drove the OSS pilot help onboard other teams?
Who is handling teaching and training the consumers of the solution - be it the business, developers or operations? Perhaps the solution was dead simple to the Erlang and Rust developers, but the Source Safe VisualBasic users are completely confused. Perhaps the developers have a handle on the new MarkDown syntax, but the requirements writers only know MS Word.
When considering training, look to existing online resources and vendor classes. Often a level of training can be bundled in with more expensive solution build-outs.
Security and Upgrades
With cloud solutions and SaaS/PaaS offerings, there is the concept of the shared responsibility model. Cloud vendors like to hammer home, that they are responsible for the cloud while you are responsible for what’s in the cloud.
It’s still important to know who will be monitoring for downtimes, unexpected usage that could be intrusions, CVAs and security patches. Too often _security vulnerabilities go unpatched simply because there isn’t a defined proces_s to monitor for and subsequently plan and address security issues.
Documentation
When looking at rolling out, all users of the system must be considered. A plan must be put in place on how to onboard and train them. And if training is not direct and in-house, materials must be sourced and presented (this is a good use of recorded training with live followups).
Once rolled out, Front Line Support teams will need to maintain an SLA and the only way to do so is with Runbooks and Maintenance Guides. Runbooks are a critical requirement of any phased rollout. They are the solutions equivalent of FAQs. During the pilot, the implementation team should take a critical ear to all issues and write documentation as they onboard.
Documentation needs to be created for security and maintenance updates (who do we call, how and when can we reach them)? Documentation must also be created for the user base of the system. Live documentation systems such as wiki, markdown and confluence are great tools to capture and address issues with the new solution.
SLAs and Scaling
We must define what support the operations team will be providing. SLAs define what is covered (and what is not), when and how the FLS and Operations team can be reached and methods for escalation. Using an email DL is not enough. SLAs should have scoping statements and clear pointers to documentation. SLAs must include time frames, ticketing system backends and methods to escalate.
In the long tail of Day 2, we need to lastly consider Expansions and how we Scale both up/down and in/out. That is, if the solution takes legs and needs to scale ou t (expand to other BUs/Departments), how can we address that. Will we support it (and if so, do we charge back those business units). All the questions we raised in our own rollout apply - SLAs, support, documentation, users of the system. We also should consider how we scale in. That is, if our solution usage goes down, how do we consolidate hardware or VMs. Can we reduce our license in future versions?
Scaling up refers to demands on the system. Did we budget properly? Is our usage driving larger VMs, or requiring more robust hardware. How do we measure performance? Are we meeting that performance? If we need to scale up to address performance, how do we do that - what is the process and who must sign off?
With the case of cloud providers, knowing your estimated usage can save the business money by buying in advance (reserved) or scaling up during off peak (spot instances).
Scaling down is similar, if we realize we overprovisioned, or chose a class of equipment that is too large, how do we know and how do we scale down. Focusing on these things saves the company considerably and will often lead to more trust within the business by considering cost-saving measures in advance.
End of Life
Lastly, when it comes time to end of life a solution, are we able to migrate our data out? Often the question of data persistence and portability comes up when we examine our solution for Disaster Recovery (HA/DR). Where are our backups going, what format and how can we transform them to a new solution?
_ An example, Rational ClearCase was ahead of it’s time. It was (is) a fantastic revision control system that could handle all sorts of source code, document and binary types. It was so good, IBM bought them and increased the license cost beyond 10k a seat. Companies for which I was involved sought to move their data out to save money._
But trying to export from complicated configspecs and a multitude of VOBs, especially if CC UCM was involved with Clearquest was a huge undertaking. More than once, I saw a migration to Subversion over similar tools to CC (like Perforce and its Workspace specifications) because Subversion was Open Sourced and portable.
It was because of this lack of data portability and high license cost, I put forward that Clearcase lost market share over time. In fact, there is a well known term for when a superior solution is overtaken just because of marketing and cost; Betamaxed.
Summary
We covered a lot of ground in this article, but hopefully we laid some fundamentals you can take away as you consider solutions. We first covered the three considerations of ROI - cost, benefit and lifespan. Next we dug into the solution lifecycle from reasons for change, through pilot into phased rollout and lastly, how we end of life solutions.
We talked about key considerations for Day 2 operations: Who is implementing, updating and supporting the tool. Support considerations covered Security, Maintenance and Updates. We also talked about Performance monitoring, SLAs and scaling (both out/in and up/down). Lastly we spoke about Data Portability and the need for Documentation at all phases of a solution.
Topics we didn’t cover but should be on deck for highly efficient operations: Automated runbooks and monitoring (solutions like Big Panda and Data Dog), alerting and escalation (PagerDuty and VictorOps) and how to apply the CMMI and Lean Engineering principles for continuous improvement.
