

Published: Jun 23, 2019 by Isaac Johnson
At this point we have a pipeline that is dynamically created, a helm chart launched and lastly torn back down. But how can we actually use this? What more can be done with this system?
When we left, we had a branch that would build, but it had not yet been merged. Let’s create a PR and take care of that first:

Then fill out the details:

Make sure to check that all the required policies are met. You can associate a Work Item after creating PR:

Next set auto-complete and we can approve to complete the PR:


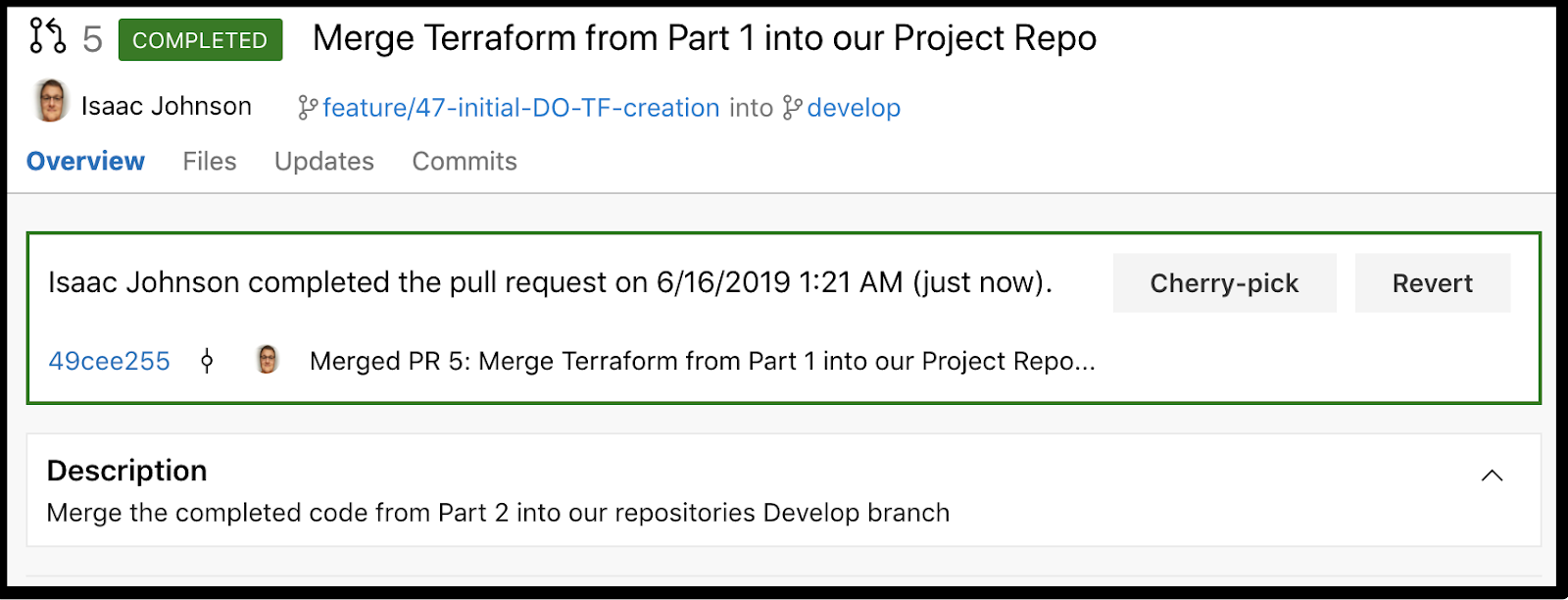
This has now been merged to develop where we can pull it down in our workspace:
$ git pull
remote: Azure Repos
remote: Found 1 objects to send. (0 ms)
Unpacking objects: 100% (1/1), done.
From https://princessking.visualstudio.com/Terraform/_git/Terraform
913ff0c..49cee25 develop -> origin/develop
Updating 913ff0c..49cee25
Fast-forward
terraform/do_k8s/main.tf | 39 +++++++++++++++++++++++++++++++++++++++
1 file changed, 39 insertions(+)
create mode 100644 terraform/do_k8s/main.tf
Let’s add a step to install Istio via Helm …
First we add a helm repo add step to the first stage of the release pipeline: (helm repo add istio.io https://storage.googleapis.com/istio-release/releases/1.1.7/charts/)
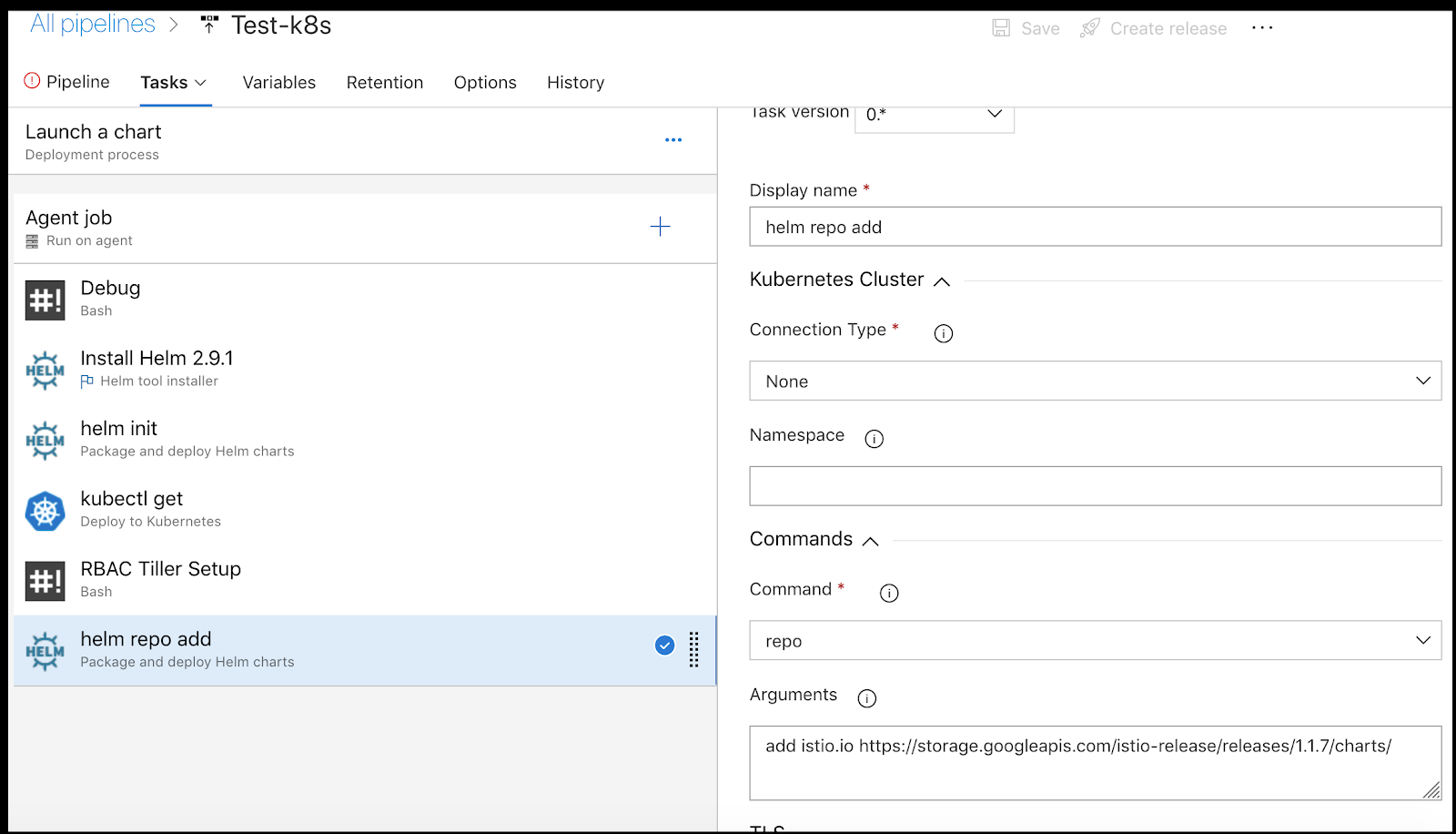
As a reminder, the reason we leave “Connection Type” to none is we set the path to the passed in kubeconfig in our variables:

Next we need to add “helm install –name istio-init –namespace istio-system istio.io/istio-init”
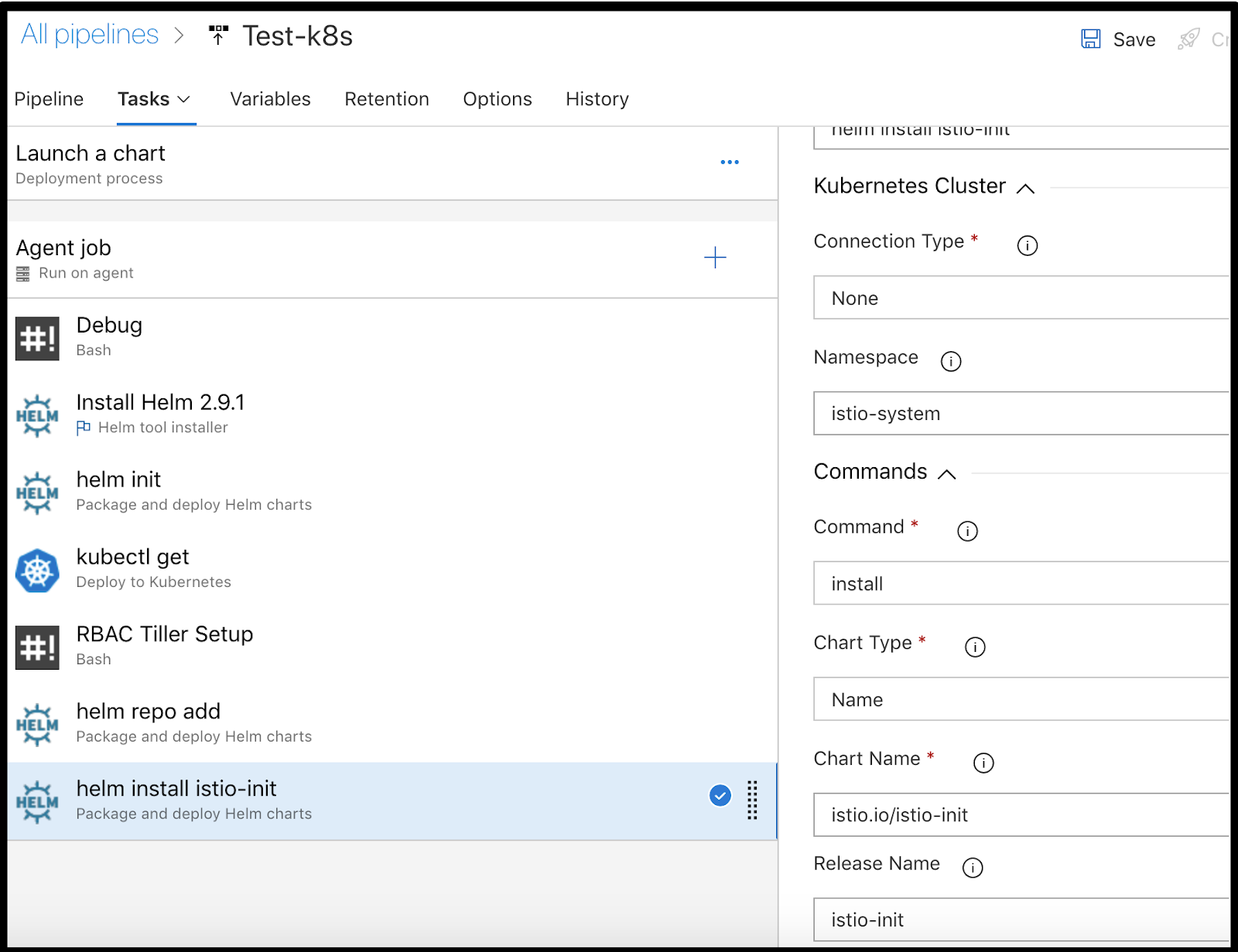
Followed by installing Istio with “helm install –name istio –namespace istio-system –set grafana.enabled=true istio.io/istio”

Let’s also add a quick check that the Istio service objects exist “kubectl get svc -n istio-system” and related pods with “kubectl get pods -n istio-system”


Now is a pretty good time to try it out…
Testing
We can queue a build from “develop” now that we’ve merged our PR:

That should queue a build using our PR commit:

This will create a cluster in our DigitalOcean account:
Once completed:

We can see it trigger our release pipeline:
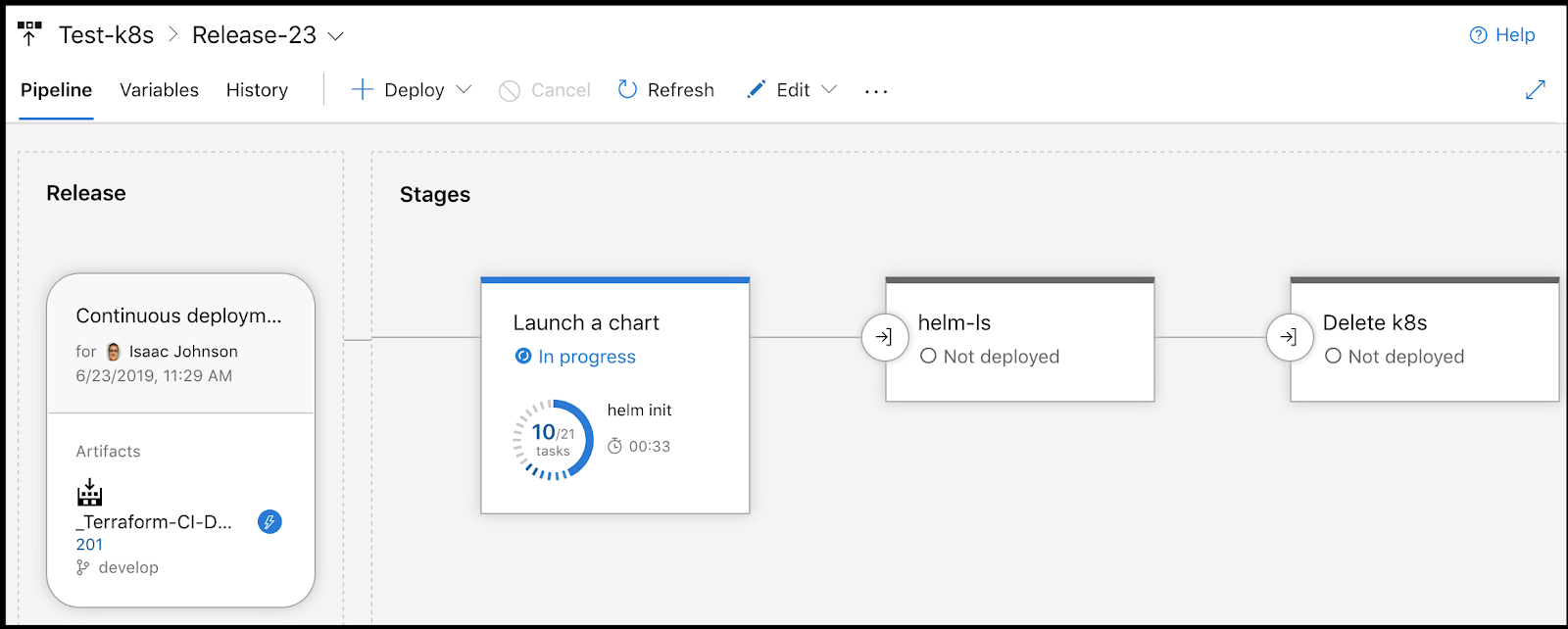
Debugging issues
If you need to debug, you can go to the CI jobs build artifacts to download the config:
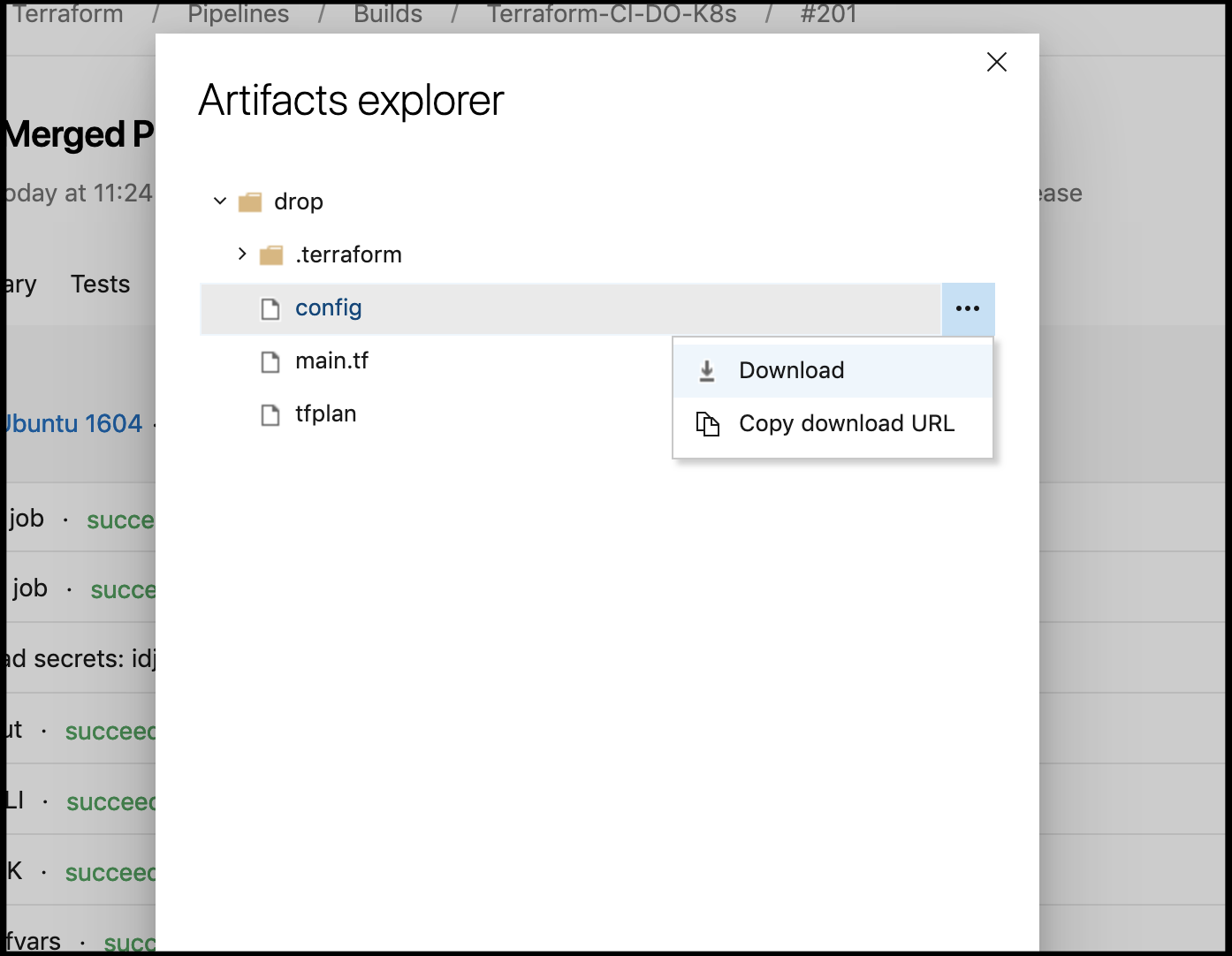
Then i copy it and set the env var (though only the env var is really necessary):
$ export KUBECONFIG=/Users/isaac.johnson/Downloads/config\(1\)
$ cp /Users/isaac.johnson/Downloads/config\(1\) ~/.kube/config
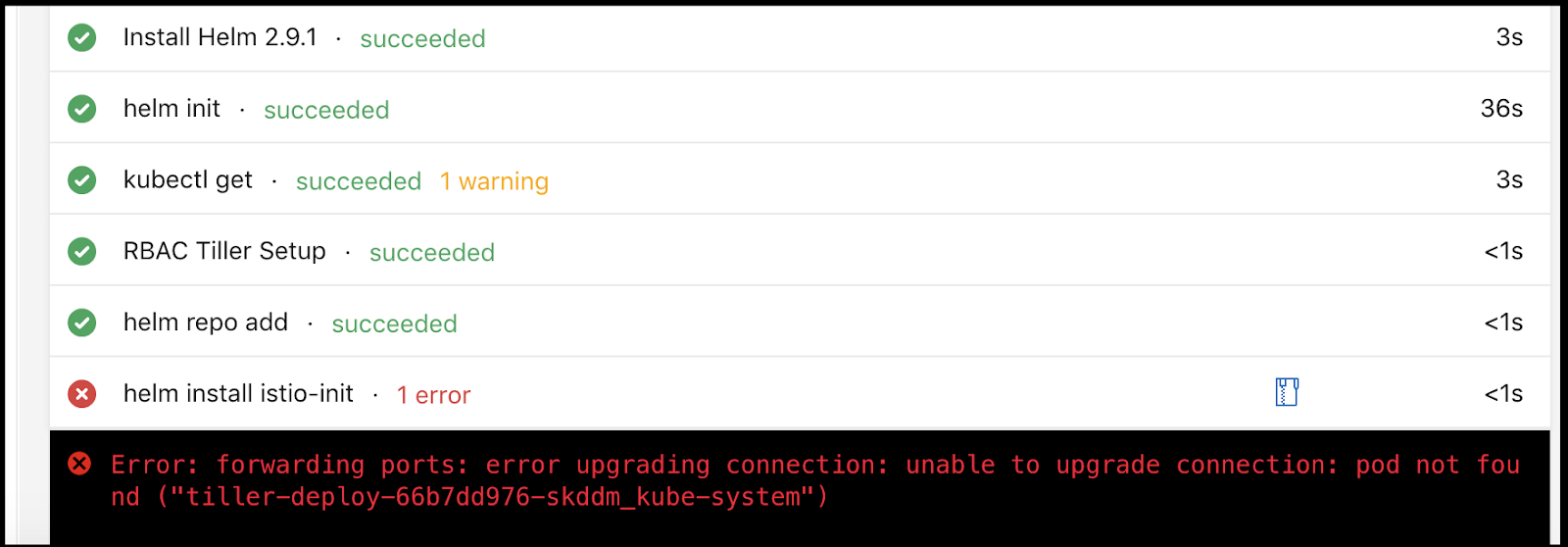
In my case i saw our Release pipeline fail on isitio-init:

The logs showed issues with tiller:
However, when trying locally, i had no issues:
$ helm repo add istio.io https://storage.googleapis.com/istio-release/releases/1.1.7/charts/
"istio.io" has been added to your repositories
$ helm install --name istio-init --namespace istio-system istio.io/istio-init
NAME: istio-init
LAST DEPLOYED: Sun Jun 23 12:22:01 2019
NAMESPACE: istio-system
STATUS: DEPLOYED
RESOURCES:
==> v1/ClusterRole
NAME AGE
istio-init-istio-system 1s
==> v1/ClusterRoleBinding
NAME AGE
istio-init-admin-role-binding-istio-system 1s
==> v1/ConfigMap
NAME DATA AGE
istio-crd-10 1 1s
istio-crd-11 1 1s
==> v1/Job
NAME COMPLETIONS DURATION AGE
istio-init-crd-10 0/1 1s 1s
istio-init-crd-11 0/1 1s 1s
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
istio-init-crd-10-x5krr 0/1 ContainerCreating 0 1s
istio-init-crd-11-68wxx 0/1 ContainerCreating 0 1s
==> v1/ServiceAccount
NAME SECRETS AGE
istio-init-service-account 1 1s
The clue is in the image above. I let it use the old Helm 2.9.1 which at this point is fairly dated.
Comparing my local machine:
$ helm version
Client: &version.Version{SemVer:"v2.13.1", GitCommit:"618447cbf203d147601b4b9bd7f8c37a5d39fbb4", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.14.1", GitCommit:"5270352a09c7e8b6e8c9593002a73535276507c0", GitTreeState:"clean"}
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"13", GitVersion:"v1.13.4", GitCommit:"c27b913fddd1a6c480c229191a087698aa92f0b1", GitTreeState:"clean", BuildDate:"2019-02-28T13:37:52Z", GoVersion:"go1.11.5", Compiler:"gc", Platform:"darwin/amd64"}
Server Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.1", GitCommit:"b7394102d6ef778017f2ca4046abbaa23b88c290", GitTreeState:"clean", BuildDate:"2019-04-08T17:02:58Z", GoVersion:"go1.12.1", Compiler:"gc", Platform:"linux/amd64"}
Shows the version on the server is all the way up to 2.14.1.
Let’s fix our pipeline - setting it up to the same:

We should be able to create a release from the same build with “Create Release”

Note: you can delete the helm install we just did to test with “helm del –purge istio-init” first or you’ll get notified that it already exists:

The helm install can take some time:

You can use your config and local machine to check the status:
$ helm list --all
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
istio 1 Sun Jun 23 12:31:25 2019 PENDING_INSTALL istio-1.1.7 1.1.7 istio-system
istio-init 1 Sun Jun 23 12:22:01 2019 DEPLOYED istio-init-1.1.7 1.1.7 istio-system
Debugging helm issues
Interesting.. Another error:
2019-06-23T17:36:35.7243548Z Error: release istio failed: timed out waiting for the condition
2019-06-23T17:36:35.7249526Z ##[error]Error: release istio failed: timed out waiting for the condition
$ helm list --all
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
istio 1 Sun Jun 23 12:31:25 2019 FAILED istio-1.1.7 1.1.7 istio-system
istio-init 1 Sun Jun 23 12:22:01 2019 DEPLOYED istio-init-1.1.7 1.1.7 istio-system
The fact it hit 5 minutes is suspect.

The logs seemed to indicate that Istio was installed and should be up
$ helm status istio
LAST DEPLOYED: Sun Jun 23 12:31:25 2019
NAMESPACE: istio-system
STATUS: FAILED
NOTES:
Thank you for installing istio.
Your release is named istio.
To get started running application with Istio, execute the following steps:
1. Label namespace that application object will be deployed to by the following command (take default namespace as an example)
$ kubectl label namespace default istio-injection=enabled
$ kubectl get namespace -L istio-injection
2. Deploy your applications
$ kubectl apply -f <your-application>.yaml
For more information on running Istio, visit:
https://istio.io/
The pods mostly look good, except for the pilot:
$ kubectl get pods -n istio-system
NAME READY STATUS RESTARTS AGE
grafana-67c69bb567-rsv64 1/1 Running 0 12m
istio-citadel-fc966574d-6h9w8 1/1 Running 0 12m
istio-galley-cf776876f-kdp45 1/1 Running 0 12m
istio-ingressgateway-7f497cc68b-clb88 0/1 Running 0 12m
istio-init-crd-10-x5krr 0/1 Completed 0 21m
istio-init-crd-11-68wxx 0/1 Completed 0 21m
istio-pilot-785694f946-m88r4 0/2 Pending 0 12m
istio-policy-79cff99c7c-5dffc 2/2 Running 0 12m
istio-sidecar-injector-c8ddbb99c-zwbgg 1/1 Running 0 12m
istio-telemetry-578b6f967c-mcvtg 2/2 Running 1 12m
prometheus-d8d46c5b5-j59zg 1/1 Running 0 12m
The describe on the istio-pilot pod shows us our real issue:
$ kubectl describe pod istio-pilot-785694f946-m88r4 -n istio-system
Name: istio-pilot-785694f946-m88r4
Namespace: istio-system
Priority: 0
PriorityClassName: <none>
Node: <none>
Labels: app=pilot
chart=pilot
heritage=Tiller
istio=pilot
pod-template-hash=785694f946
release=istio
Annotations: sidecar.istio.io/inject: false
Status: Pending
IP:
Controlled By: ReplicaSet/istio-pilot-785694f946
Containers:
discovery:
Image: docker.io/istio/pilot:1.1.7
Ports: 8080/TCP, 15010/TCP
Host Ports: 0/TCP, 0/TCP
Args:
discovery
--monitoringAddr=:15014
--log_output_level=default:info
--domain
cluster.local
--secureGrpcAddr
--keepaliveMaxServerConnectionAge
30m
Requests:
cpu: 500m
memory: 2Gi
Readiness: http-get http://:8080/ready delay=5s timeout=5s period=30s #success=1 #failure=3
Environment:
POD_NAME: istio-pilot-785694f946-m88r4 (v1:metadata.name)
POD_NAMESPACE: istio-system (v1:metadata.namespace)
GODEBUG: gctrace=1
PILOT_PUSH_THROTTLE: 100
PILOT_TRACE_SAMPLING: 1
PILOT_DISABLE_XDS_MARSHALING_TO_ANY: 1
Mounts:
/etc/certs from istio-certs (ro)
/etc/istio/config from config-volume (rw)
/var/run/secrets/kubernetes.io/serviceaccount from istio-pilot-service-account-token-q56vx (ro)
istio-proxy:
Image: docker.io/istio/proxyv2:1.1.7
Ports: 15003/TCP, 15005/TCP, 15007/TCP, 15011/TCP
Host Ports: 0/TCP, 0/TCP, 0/TCP, 0/TCP
Args:
proxy
--domain
$(POD_NAMESPACE).svc.cluster.local
--serviceCluster
istio-pilot
--templateFile
/etc/istio/proxy/envoy_pilot.yaml.tmpl
--controlPlaneAuthPolicy
NONE
Limits:
cpu: 2
memory: 1Gi
Requests:
cpu: 100m
memory: 128Mi
Environment:
POD_NAME: istio-pilot-785694f946-m88r4 (v1:metadata.name)
POD_NAMESPACE: istio-system (v1:metadata.namespace)
INSTANCE_IP: (v1:status.podIP)
Mounts:
/etc/certs from istio-certs (ro)
/var/run/secrets/kubernetes.io/serviceaccount from istio-pilot-service-account-token-q56vx (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
config-volume:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: istio
Optional: false
istio-certs:
Type: Secret (a volume populated by a Secret)
SecretName: istio.istio-pilot-service-account
Optional: true
istio-pilot-service-account-token-q56vx:
Type: Secret (a volume populated by a Secret)
SecretName: istio-pilot-service-account-token-q56vx
Optional: false
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 15s (x10 over 13m) default-scheduler 0/3 nodes are available: 1 Insufficient cpu, 3 Insufficient memory.
Handing Scaling issues
We simply didn’t make a big enough cluster to handle istio. So how can we fix that? We could verify that scaling out would fix by first testing manually:
We can do this from the ellipse menu on the node pool under our cluster in digital ocean:

Let’s set that value up that to 4 and see if our pod gets scheduled.
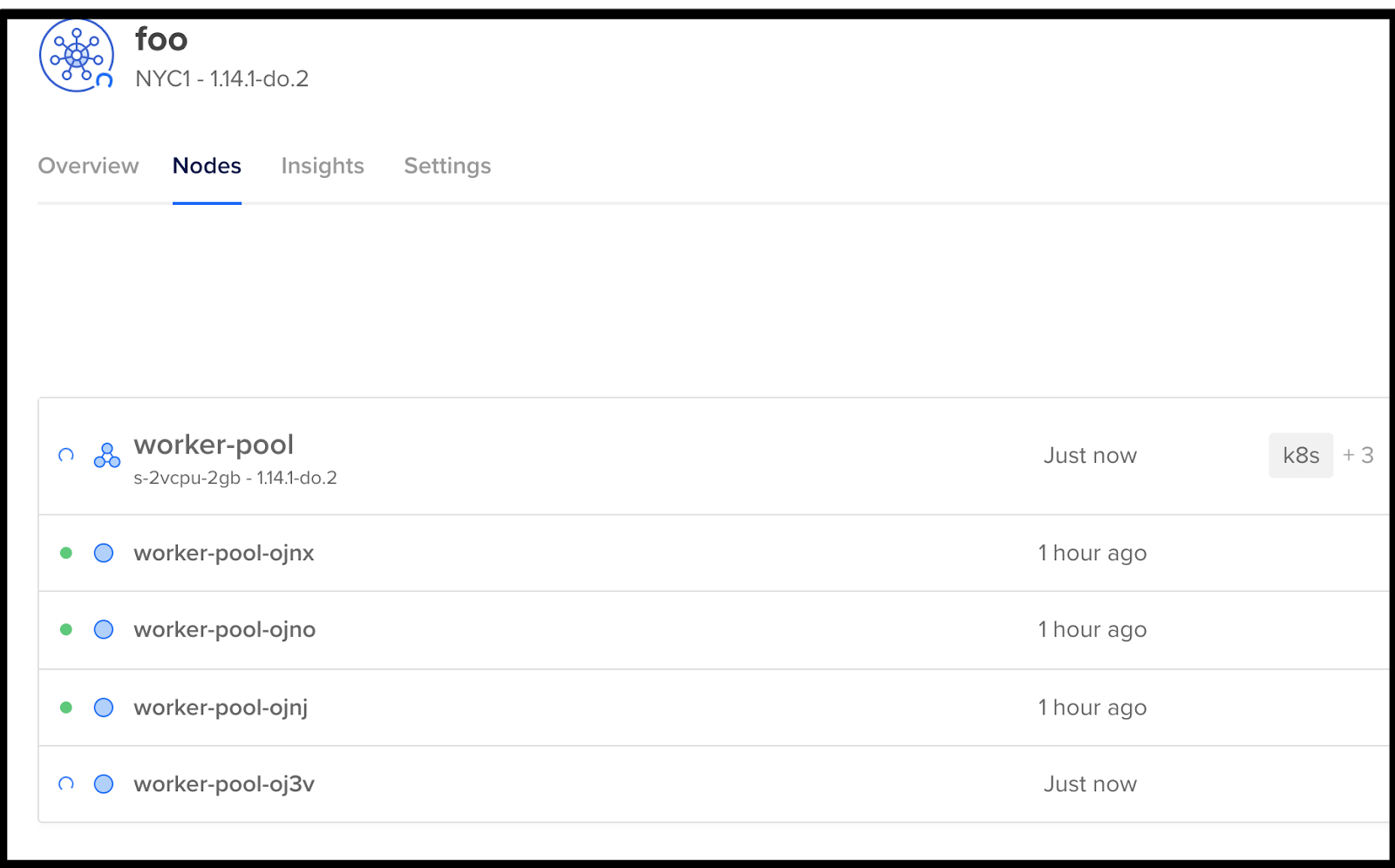
And we can see it added on the command line as well:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
worker-pool-ojnj Ready <none> 79m v1.14.1
worker-pool-ojno Ready <none> 79m v1.14.1
worker-pool-ojnx Ready <none> 79m v1.14.1
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
worker-pool-oj3v NotReady <none> 1s v1.14.1
worker-pool-ojnj Ready <none> 81m v1.14.1
worker-pool-ojno Ready <none> 81m v1.14.1
worker-pool-ojnx Ready <none> 81m v1.14.1
Ah well, still no go - it clearly needs a higher class machine:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 41s (x14 over 19m) default-scheduler 0/3 nodes are available: 1 Insufficient cpu, 3 Insufficient memory.
Warning FailedScheduling 29s (x3 over 32s) default-scheduler 0/4 nodes are available: 1 Insufficient cpu, 4 Insufficient memory.
Let’s add a new node pool to the cluster:
We’ll add a couple larger sized ones to a new worker pool:

When the pool is ready, it should be reflected:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
pool-29l9dhecn-oj30 NotReady <none> 41s v1.14.1
pool-29l9dhecn-oj3d NotReady <none> 36s v1.14.1
worker-pool-oj3v Ready <none> 5m55s v1.14.1
worker-pool-ojnj Ready <none> 87m v1.14.1
worker-pool-ojno Ready <none> 87m v1.14.1
worker-pool-ojnx Ready <none> 86m v1.14.1
And now it works!
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 6m27s (x14 over 25m) default-scheduler 0/3 nodes are available: 1 Insufficient cpu, 3 Insufficient memory.
Warning FailedScheduling 2m27s (x8 over 6m18s) default-scheduler 0/4 nodes are available: 1 Insufficient cpu, 4 Insufficient memory.
Warning FailedScheduling 59s (x4 over 64s) default-scheduler 0/5 nodes are available: 1 Insufficient cpu, 1 node(s) had taints that the pod didn't tolerate, 4 Insufficient memory.
Warning FailedScheduling 9s (x4 over 54s) default-scheduler 0/6 nodes are available: 1 Insufficient cpu, 2 node(s) had taints that the pod didn't tolerate, 4 Insufficient memory.
Normal Pulling 2s kubelet, pool-29l9dhecn-oj3d Pulling image "docker.io/istio/pilot:1.1.7"
Summary so far
We’ve verified that when Istio was added we first had too old of helm and kubectl. We upgraded those to solve the isitio-init. Our next issue was we couldn’t schedule all the pods in the istio install itself. We first tied to scale out (horizontally) but it didn’t solve the memory and cpu issues. We tried adding a node pool of larger size and it solved the issue. At this point we have a cluster with Istio installed, however, we’ve hand-jammed the cluster with extra large nodes. Our next steps should be to update the terraform and try again.
We can see the right size nodes from our node pool page (s-4vcpu-8gb):

Next we can add a branch to implement the changes istio needs:
$ git checkout -b feature/48-implementing-Istio
Switched to a new branch 'feature/48-implementing-Istio'
Let’s change our terraform to match the large node size:
$ git diff
diff --git a/terraform/do_k8s/main.tf b/terraform/do_k8s/main.tf
index e3ecc17..0a98392 100644
--- a/terraform/do_k8s/main.tf
+++ b/terraform/do_k8s/main.tf
@@ -21,7 +21,7 @@ resource "digitalocean_kubernetes_cluster" "foo" {
node_pool {
name = "worker-pool"
- size = "s-2vcpu-2gb"
+ size = "s-4vcpu-8gb"
node_count = 3
}
}
and next we commit and push the branch
$ git add -A
AHD-MBP13-048:do_k8s isaac.johnson$ git commit -m "update size of cluster nodes"
[feature/48-implementing-Istio 77eac1b] update size of cluster nodes
1 file changed, 1 insertion(+), 1 deletion(-)
$ git push
fatal: The current branch feature/48-implementing-Istio has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin feature/48-implementing-Istio
$ darf
git push --set-upstream origin feature/48-implementing-Istio [enter/↑/↓/ctrl+c]
Enumerating objects: 9, done.
Counting objects: 100% (9/9), done.
Delta compression using up to 4 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (5/5), 399 bytes | 399.00 KiB/s, done.
Total 5 (delta 2), reused 0 (delta 0)
remote: Analyzing objects... (5/5) (8 ms)
remote: Storing packfile... done (171 ms)
remote: Storing index... done (78 ms)
To https://princessking.visualstudio.com/Terraform/_git/Terraform
* [new branch] feature/48-implementing-Istio -> feature/48-implementing-Istio
Branch 'feature/48-implementing-Istio' set up to track remote branch 'feature/48-implementing-Istio' from 'origin'.
Before we trigger another build, let’s undo our cluster.
First i’ll remove that extra node pool we added:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
pool-29l9dhecn-oj30 Ready <none> 21m v1.14.1
pool-29l9dhecn-oj3d Ready <none> 21m v1.14.1
worker-pool-oj3v Ready <none> 27m v1.14.1
worker-pool-ojnj Ready <none> 108m v1.14.1
worker-pool-ojno Ready <none> 108m v1.14.1
worker-pool-ojnx Ready <none> 108m v1.14.1
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
pool-29l9dhecn-oj30 Ready,SchedulingDisabled <none> 21m v1.14.1
pool-29l9dhecn-oj3d Ready,SchedulingDisabled <none> 21m v1.14.1
worker-pool-oj3v Ready <none> 27m v1.14.1
worker-pool-ojnj Ready <none> 108m v1.14.1
worker-pool-ojno Ready <none> 108m v1.14.1
worker-pool-ojnx Ready <none> 108m v1.14.1
Then I’ll use our manual delete cluster job to remove the cluster:

This will delete them. We can use kubectl get nodes to track the deprecation process
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
pool-29l9dhecn-oj30 Ready,SchedulingDisabled <none> 25m v1.14.1
pool-29l9dhecn-oj3d Ready,SchedulingDisabled <none> 25m v1.14.1
worker-pool-oj3v Ready <none> 30m v1.14.1
worker-pool-ojnj Ready <none> 112m v1.14.1
worker-pool-ojno Ready <none> 112m v1.14.1
worker-pool-ojnx Ready <none> 111m v1.14.1
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
pool-29l9dhecn-oj3d Ready,SchedulingDisabled <none> 26m v1.14.1
worker-pool-ojnj Ready <none> 113m v1.14.1
worker-pool-ojnx Ready <none> 112m v1.14.1
$ kubectl get nodes
Unable to connect to the server: dial tcp: lookup 6b986be3-a2b5-43a6-a5e0-52ba69908862.k8s.ondigitalocean.com on 192.168.1.1:53: no such host
Let’s now kick off the build to create the cluster with the new size:

And we can see the cluster is being created with the right size now:

Note: I did have a minor issue with the error:
2019-06-23T19:58:27.7099665Z Error: forwarding ports: error upgrading connection:
2019-06-23T19:58:27.7124782Z ##[error]Error: forwarding ports: error upgrading connection:
and
2019-06-23T19:58:27.9671805Z Error: could not find a ready tiller pod
2019-06-23T19:58:27.9677271Z ##[error]Error: could not find a ready tiller pod
However, in testing, i couldn’t replicate it (i believe tiller was just slow to come up). Moving forward to canary version and back again as well as attempting locally seemed to clear up any issues.
Validation:
If we check during our 10m window before cluster removal, we should be able to dig up the SonarQube IP and check our service:

$ helm ls
NAME REVISION UPDATED STATUS CHART APP VERSION NAMESPACE
do-sonarqube 1 Sun Jun 23 16:04:10 2019 DEPLOYED sonarqube-2.0.0 7.7 default
istio 1 Sun Jun 23 15:59:30 2019 DEPLOYED istio-1.1.7 1.1.7 istio-system
istio-init 1 Sun Jun 23 15:59:26 2019 DEPLOYED istio-init-1.1.7 1.1.7 istio-system
$ kubectl get svc --namespace default do-sonarqube-sonarqube -o jsonpath='{.status.loadBalancer.ingress[0].ip}
> '
165.227.253.23

Beyond that, we know that Istio installed because we can portforward to grafana just fine:
$ kubectl port-forward grafana-67c69bb567-brf5s -n istio-system 3000:3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
Handling connection for 3000

In our next blog we’ll dig into propegating the Istio sidecar…
$ kubectl label namespace default istio-injection=enabled
namespace/default labeled
$ kubectl get namespace -L istio-injection
NAME STATUS AGE ISTIO-INJECTION
default Active 84m enabled
istio-system Active 25m
kube-node-lease Active 84m
kube-public Active 84m
kube-system Active 84m
_ Source of material: most of the steps are an extension of the tutorial from Digital Ocean themselves: https://www.digitalocean.com/community/tutorials/how-to-install-and-use-istio-with-kubernetes . I had desired to do this entirely with Terraform but no DO Istio module exists at present._
