

Published: May 26, 2019 by Isaac Johnson
Harness bills itself as “the industry’s first Continuous Delivery-as-a-Service platform”. You can signup up from the website https://harness.io/ using a few different credentials providers. The product is priced in a few different ways. One method is k8s pods at $25/pod/month. When you signup you get a two week trial so let’s do that and see what it can do.
Login to https://app.harness.io/#.

Let’s try the quickly deploy a sample app:

Next you can start a deployment:

And check on it using the deployments Graphical progress:

There is more info on the lower right:

Our sample pipeline has an approval gate we need to action upon to move forward:
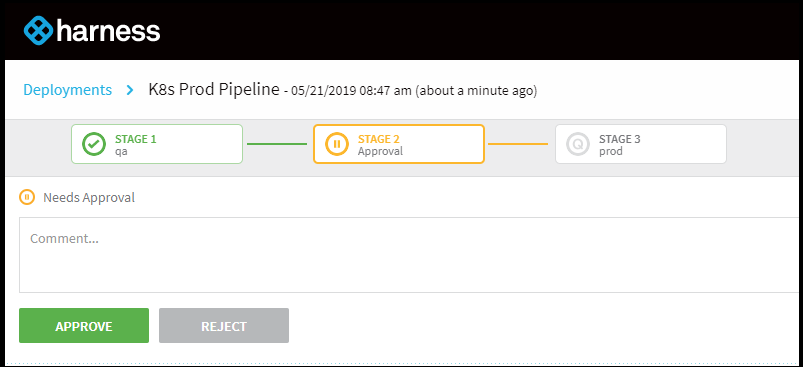
This then started the Prod canary deployment:

Deployments dashboard view:

Details on our Harness Sample App:

Reviewing environment configurations:

Digging into the Yaml files:

Now let us TRY to do one on our own:
Before we get anywhere, we’ll need to launch a delegate on our cluster. I found the sample one disappeared shortly after our demo. But more to the point, i would rather see how harness works within my own cluster.
For this example, we’ll follow one of our prior guides to spin up a k8s cluster.
Spinning an AKS cluster on the quickly:
$ az login
$ az group create --location eastus --name idj-harness-k8s
$ az ad sp create-for-rbac --skip-assignment
{
"appId": "c0372857-xxxxx-xxxxxx-xxxxxxx-xxxxxxx",
"displayName": "azure-cli-2019-05-26-xx-xx-xx",
"name": "http://azure-cli-2019-05-26-xx-xx-xx",
"password": "54e12673-xxxx-xxxx-xxxx-xxxxxxxxxx,
"tenant": "bxxxxxxxx-xxxxxxxxx-xxxxxxxx-xxxxxxxx"
}
$ az aks create --resource-group idj-harness-k8s --name idjharnessk8scluster --kubernetes-version 1.14.0 --node-count 1 --enable-vmss --enable-cluster-autoscaler --min-count 1 --max-count 3 --generate-ssh-keys --service-principal c0372857-xxxxx-xxxxxx-xxxxxxx-xxxxxxx --client-secret 54e12673-xxxx-xxxx-xxxx-xxxxxxxxxx
I’m mostly including those as if you’ve been following along, you’ll likely made a fair number of clusters and perhaps, like me, your default SPs have been scrubbed and Azure forgets and vomits out “Operation failed with status: ‘Bad Request’. Details: The credentials in ServicePrincipalProfile were invalid. Please see https://aka.ms/aks-sp-help for more details. (Details: adal: Refresh request failed. Status Code = ‘401’.” when you try to fire a cluster.
Then we need a touch of RBAC for the dashboard (dashboard-rbac.yaml from prior AKS guides):
$ kubectl apply -f ~/dashboard-rbac.yaml
$ kubectl create clusterrolebinding kubernetes-dashboard -n kube-system --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
$ az aks browse --resource-group idj-harness-k8s --name idjharnessk8scluster

Now that we have kubernetes up and going, let’s download and install the delegate:

Choose Kubernetes Yaml and give it a name to download:
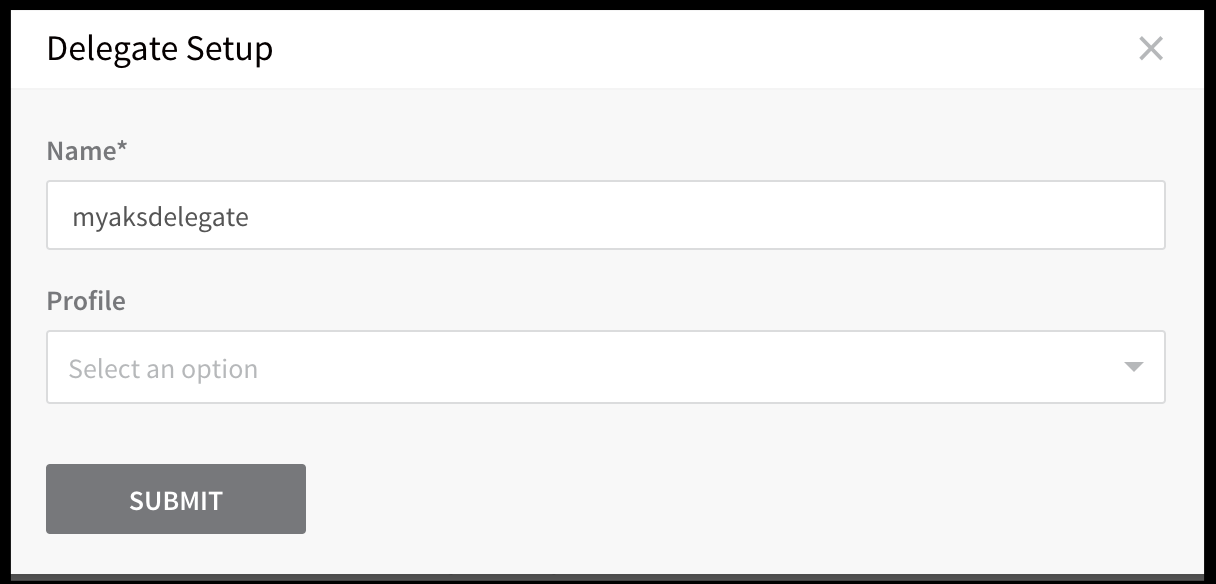
Expand it into a directory and apply it per README.txt
$ ls
README.txt harness-delegate.yaml
$ kubectl apply -f harness-delegate.yaml
namespace/harness-delegate created
clusterrolebinding.rbac.authorization.k8s.io/harness-delegate-cluster-admin created
secret/myaksdelegate-proxy created
statefulset.apps/myaksdelegate-neegfp created
After launching i expected to see a pod but realized it wasn’t coming up…
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
harness-delegate myaksdelegate-neegfp-0 0/1 Pending 0 7m13s
kube-system coredns-76b964fdc6-lmrnc 1/1 Running 0 7h41m
kube-system coredns-76b964fdc6-lpww6 1/1 Running 0 7h38m
kube-system coredns-autoscaler-86849d9999-lv2vd 1/1 Running 0 7h41m
kube-system kube-proxy-mq8bs 1/1 Running 0 7h38m
kube-system kube-svc-redirect-22kg9 2/2 Running 0 7h39m
kube-system kubernetes-dashboard-6975779c8c-gwwwl 1/1 Running 1 7h41m
kube-system metrics-server-5dd76855f9-5thr6 1/1 Running 0 7h41m
kube-system tunnelfront-85dfd97d49-rc8p7 1/1 Running 0 7h41m
$ kubectl describe pod myaksdelegate-neegfp-0 --namespace harness-delegate
Name: myaksdelegate-neegfp-0
Namespace: harness-delegate
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NotTriggerScaleUp 2m18s (x31 over 7m22s) cluster-autoscaler pod didn't trigger scale-up (it wouldn't fit if a new node is added): 1 Insufficient memory
Warning FailedScheduling 10s (x7 over 7m29s) default-scheduler 0/1 nodes are available: 1 Insufficient memory.
We can easily scale out in the Azure Portal or command line.

When that failed to solve it i looked more carefully and realized this harness delegate needs 8gb of ram - the standard DS2 are 7gb.. So i upped the class size to DS3_v2:

Then i deleted the one i added to force the VMSS to add a new sized one:

note: after that, I did have to manually scale back to 2.. I thought it would save it but it didn’t

This solved the problem:
$ kubectl get nodes --all-namespaces
NAME STATUS ROLES AGE VERSION
aks-nodepool1-17170219-vmss000000 Ready agent 7h56m v1.14.0
aks-nodepool1-17170219-vmss000002 Ready agent 103s v1.14.0
$ kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
harness-delegate myaksdelegate-neegfp-0 1/1 Running 1 24m
kube-system coredns-76b964fdc6-lmrnc 1/1 Running 0 7h58m
And after a few minutes, the entry came up in harness:
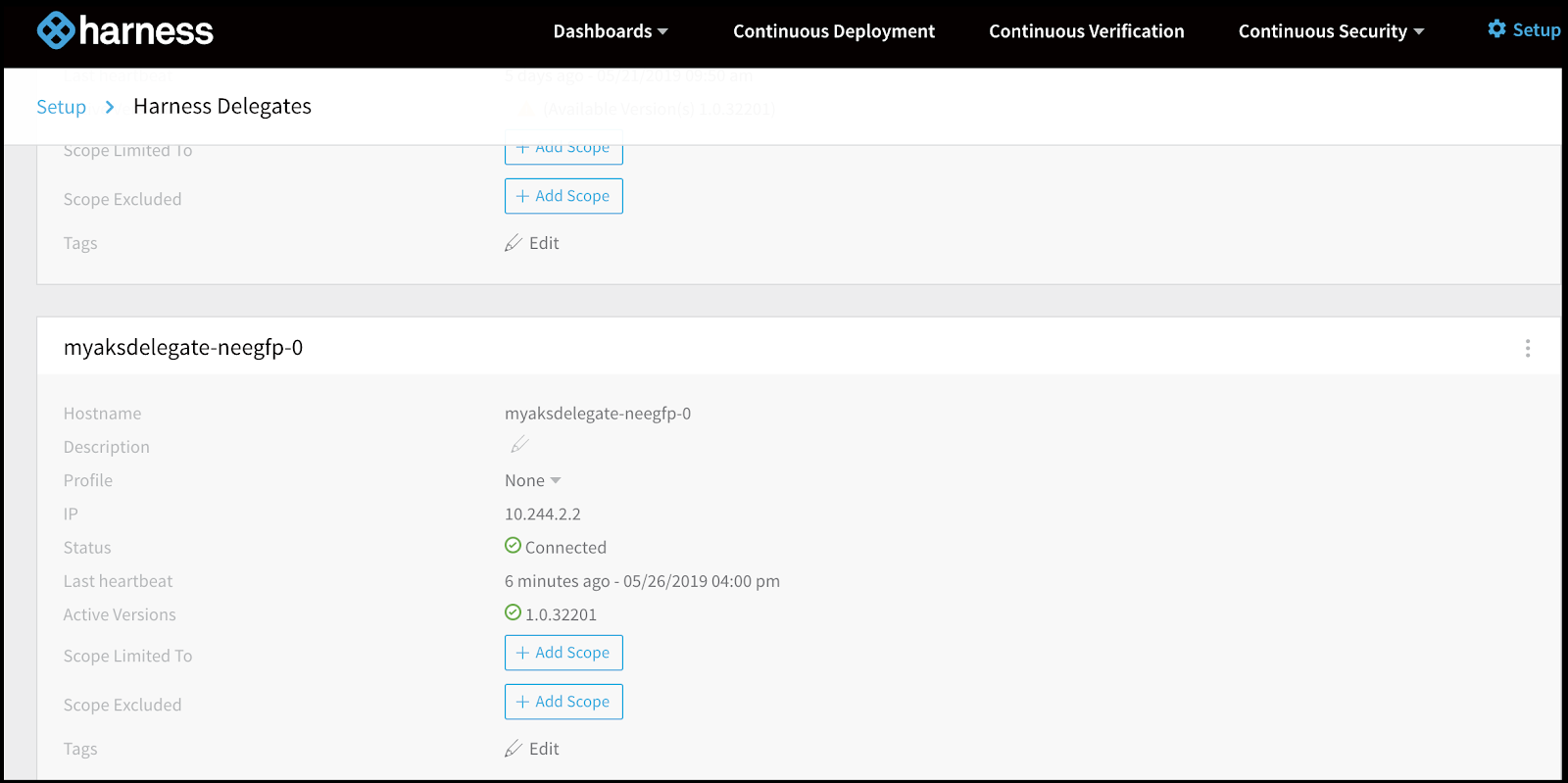
So let’s launch a deployment using our own cluster and see what gets created:

However, it failed in deployment:

Now sadly, all we have to go on is “No delegates could reach the resource. [delegate-name: harness-sample-k8s-delegate]”
Because they’re doing their own thing, I couldn’t get specifics from k8s:
$ kubectl get deployments --all-namespaces
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system coredns 2/2 2 2 8h
kube-system coredns-autoscaler 1/1 1 1 8h
kube-system kubernetes-dashboard 1/1 1 1 8h
kube-system metrics-server 1/1 1 1 8h
kube-system tunnelfront 1/1 1 1 8h
I would assume we cannot reach the image repository, but without more detailed logs, it’s hard to be sure.
I checked the logs on the pod later, but cannot be sure it’s related
$ kubectl logs myaksdelegate-neegfp-0 --namespace harness-delegate
curl: (6) Could not resolve host: app.harness.io
Downloading JRE packages...
######################################################################## 100.0%
Extracting JRE packages...
Installing kubectl...
Can we create an application?
Go to setup and then add an application with “+ Add Application”:

However, i immediately found myself i the game of pre-requisites:

You cannot create a pipeline without a workflow. Workflows then require Environments. Environments then require Services.
So let’s add a service.

Caught again, it needs a repository to pull charts from. So let’s try and add https://github.com/helm/charts/tree/master/stable

However, no matter what password i used (and the UI required a Git login/password), it would not connect:

Trying other features
I tried to explore some of the other features as well. I found some good youtube videos exploring the CV stages, but it’s been deprecated in favour of a new “Service Guard” add-on:

However, there is no real info and the “Learn More” launches a help window that times out:

I was able to add Cloud Providers:

However, i can’t use AKV for secrets management:
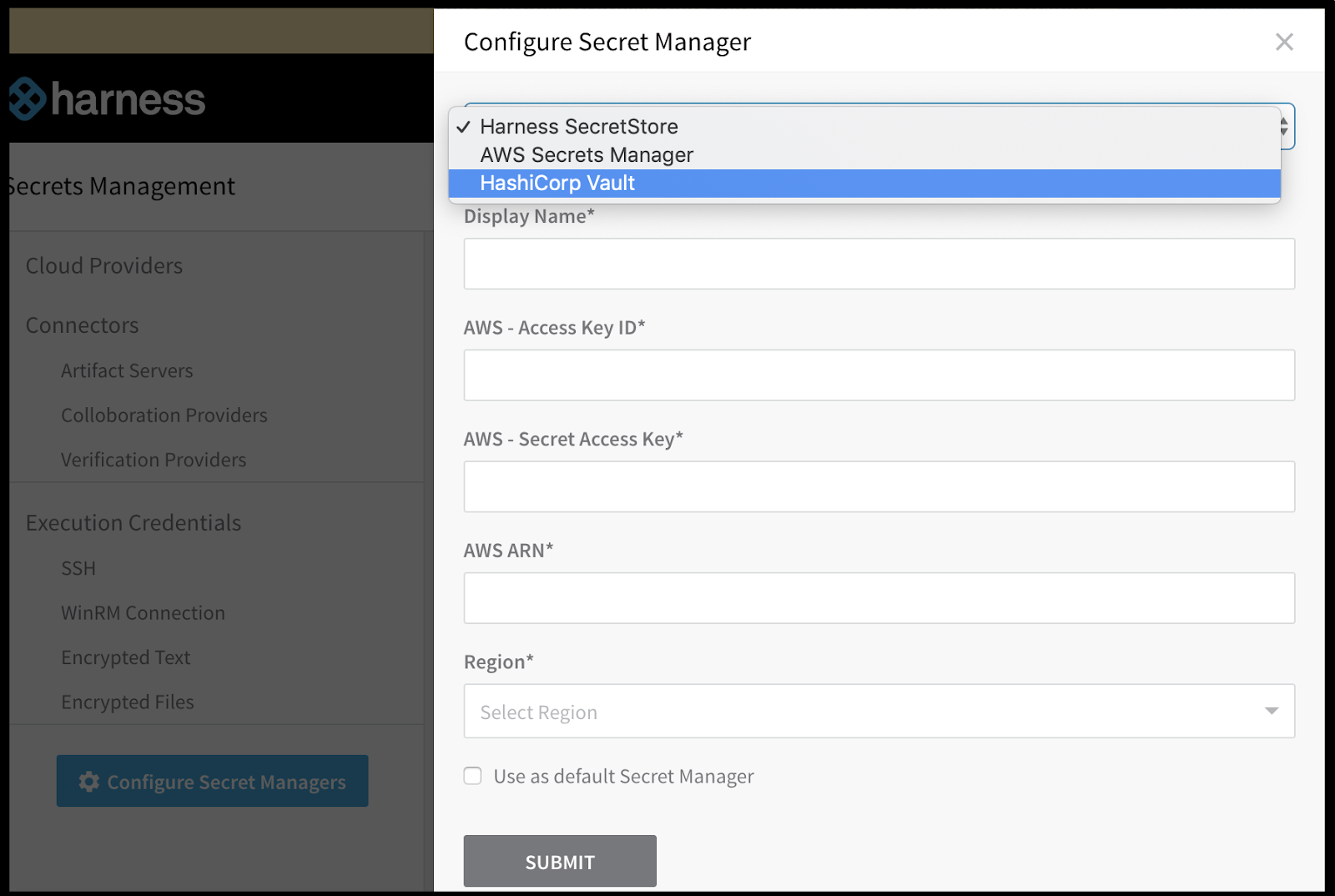
Another minor issue i had is that Vault requires a public facing vault instance. I would have liked to pick a cluster or environment to use an OSS internal facing Vault instead:

Summary
Harness wins when it comes to menus. They have a lot of fields and objects and a fairly clean UI. There is promise here. The sample app they steer you to at the start works (i think) and exercises a pipeline.
However, struggles with integrating it with my own environment and i could imagine any non-AWS environment kept me from digging deeper. The agent that worked the first day was gone a few days later so i couldn’t try again. And the LB URL for the sample app timed out which leads me to believe it was an ephemeral cluster.
The agent’s hefty memory requirements also means you need a fairly tall cluster which would rule out some of the smaller clusters we’ve spun up in the past. I could see from the logs it’s running Xenial so i’m not sure how they made it so memory intensive.
I’ll like revisit it in the future when they have better Azure support and better start guides. I also hope the find ways to skinny up their agents and provide a bit better error logs.
