
In the past I've discussed trying to automate this blog.
Phase 1: KISS method
I created some scripts that would sync it locally from a local node server (using httrack) then parse the html files to identify and sync any missing images. Lastly i would upload the whole thing to s3.
There are several problems with this approach. The first is it's clearly jenky - i have to have a locally running server and sync it.. locally? then sed the snot out of files only to upload them to s3.
The second issue is it's risky - what if this laptop dies? I'm hard as hell on laptops. If i terf this craptop it's all over.
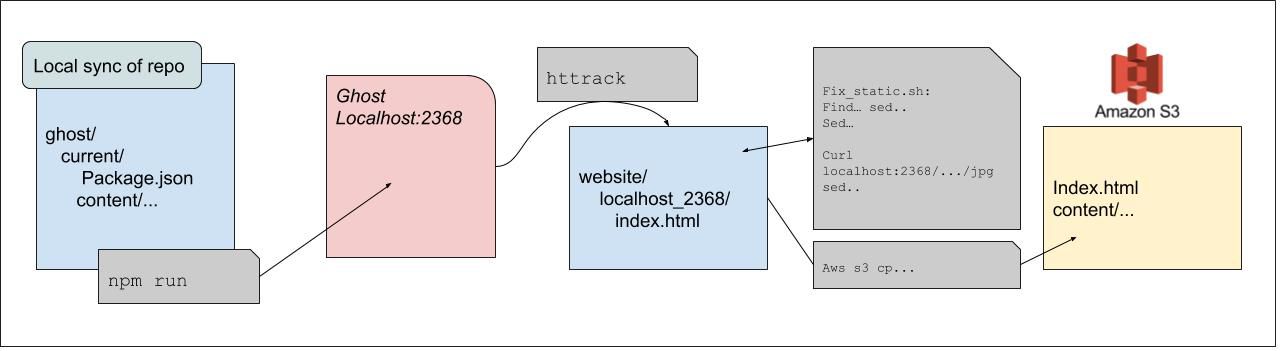
This worked, but I had two major concerns:
- It's not backed up
- It would be hard to recreate/migrate
Phase 2: Automating with Azure DevOps
First thing I did was sync it to a fresh AzDO Repo.
isaac.johnson$ git remote add vsts https://myvstsinstance.visualstudio.com/ghost-blog/_git/ghost-blog
isaac.johnson$ git push vsts --all
Username for 'https://myvstsinstance.visualstudio.com': isaac.johnson@myemail.com
Password for 'https://isaac.johnson@myemail.com@myvstsinstance.visualstudio.com':
Enumerating objects: 15060, done.
Counting objects: 100% (15060/15060), done.
Delta compression using up to 4 threads
Compressing objects: 100% (10922/10922), done.
Writing objects: 100% (15060/15060), 31.95 MiB | 3.51 MiB/s, done.
Total 15060 (delta 3061), reused 15060 (delta 3061)
remote: Analyzing objects... (15060/15060) (9612 ms)
remote: Storing packfile... done (1350 ms)
remote: Storing index... done (176 ms)
To https://myvstsinstance.visualstudio.com/ghost-blog/_git/ghost-blog
* [new branch] master -> master
Once the files are in a Repo (in Repos) you can create a build pipeline under builds to run most of the manual steps.
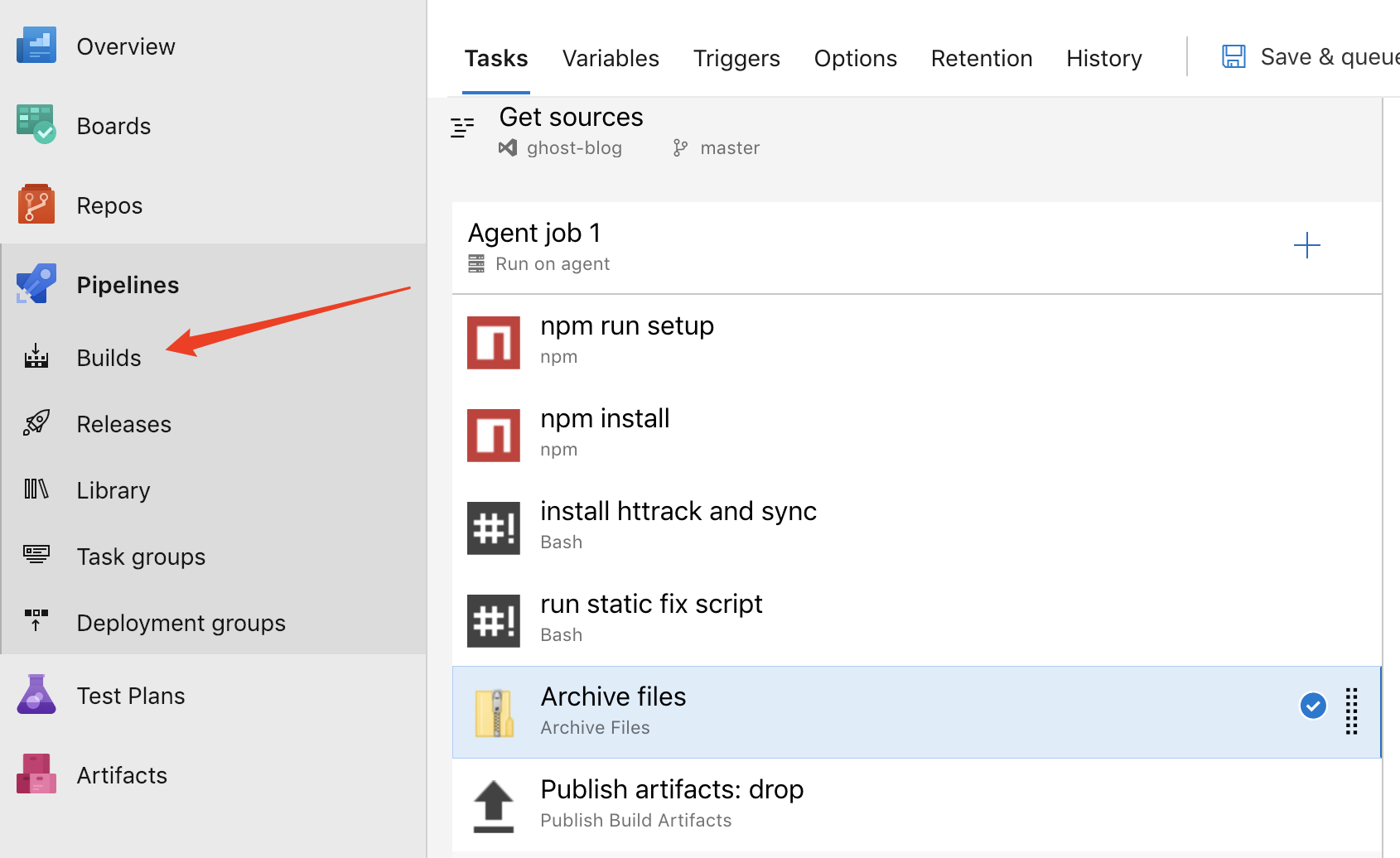
At the end of pipeline, we see the key step - publishing my drop artifact. I could use Azure Artifacts to store a sync of the site, but really, the publish artifact is sufficient as I'll use that to trigger the Release pipeline that follows.
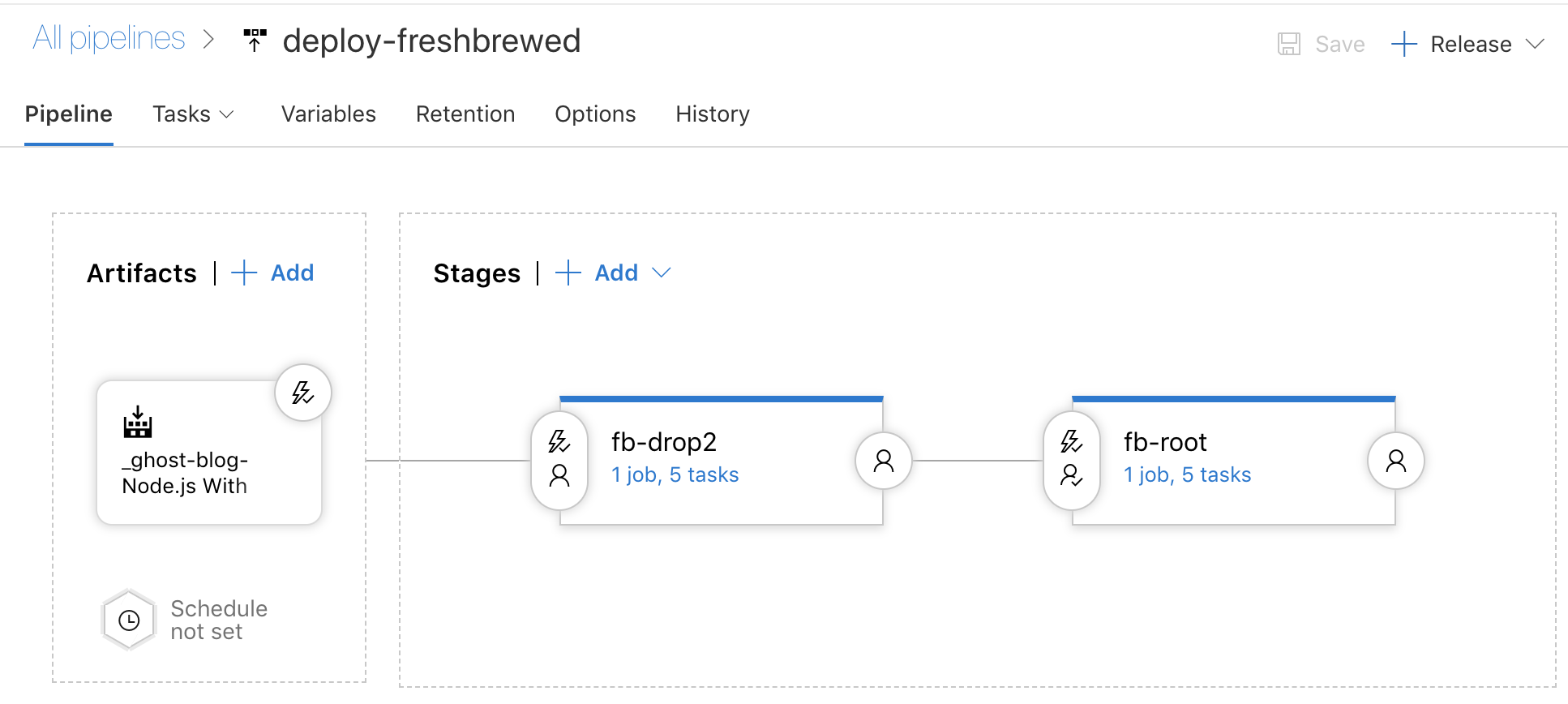
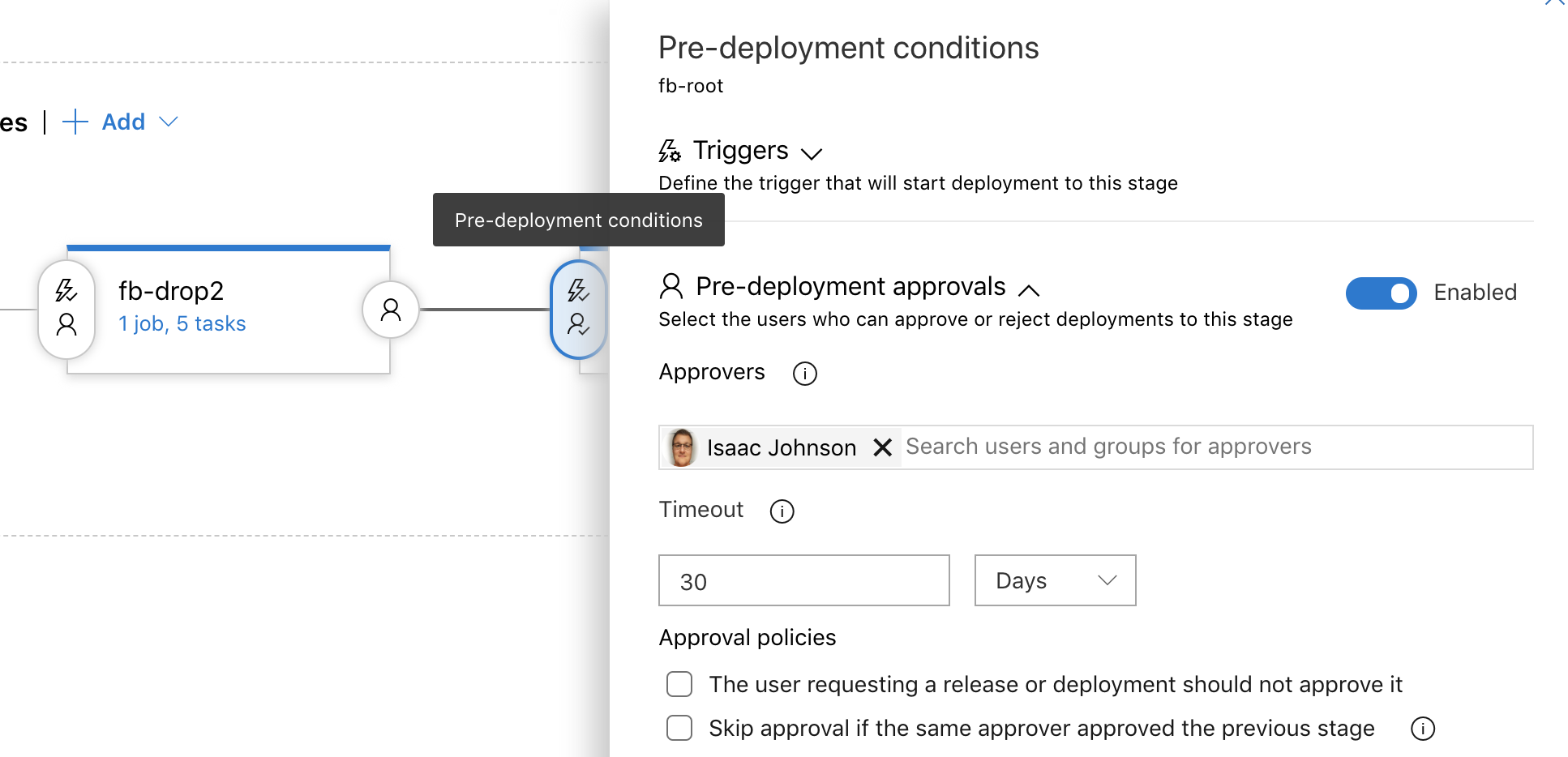
The key point is that the release pipeline is triggered with each build of the CI pipeline for true Continuous Deployment. You'll notice that there is a gate indicator on the second stage (which actually launches the site). This enables me to preview it first on a url before making it live.
The release steps themselves are identical in both stages (except for the s3 copy steps have different destinations). This means I'll likely bundle these into a task group in the near future.
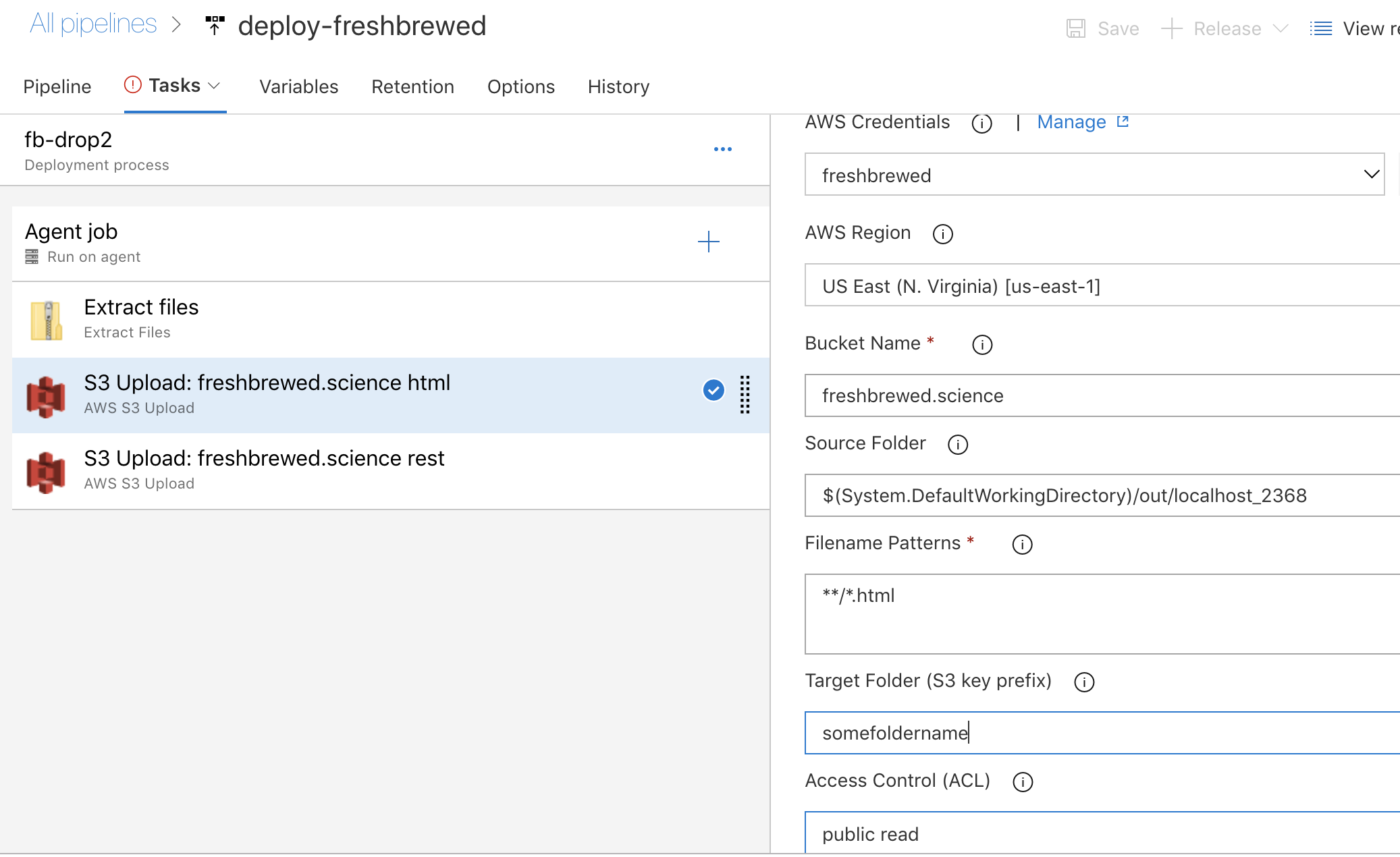
The stages are quite similar using the AWS S3 task to copy contents i extracted from the zip (recall, i was passed the artifact zip from the CI pipeline) to a staging folder. One needs to set the ACLs to "public read".
The reason I broke it into two steps was simple - in the advanced section (not shown above) of the s3 task, you can choose to overwrite. For HTML files, i chose to blast them as the index pages can easily change. However, the images never do, so the rest are set to not overwrite to save on bandwidth.
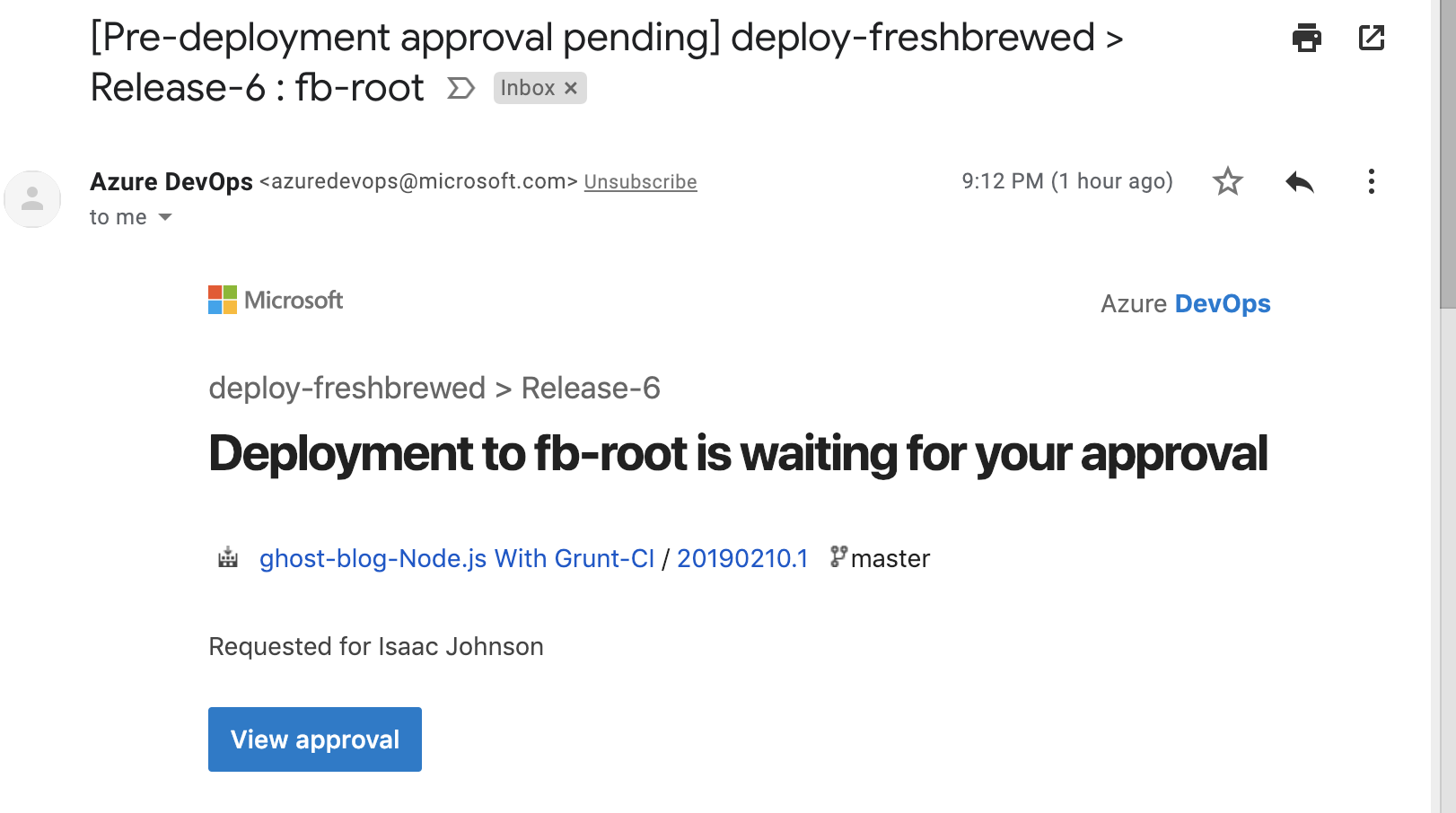
When it triggers a deploy, i get emailed from the gate and can chose whether to make it go live now simply by confirming a simple email;
In future posts, i'll break down the various steps and we can even transition to yaml based builds to bring the thinking bits under better revision control inside our GIT repo.